
Fluxo de Preservação Dataverse com o Archivematica
Esta página define os requisitos e designs para integração com o Dataverse. A partir do Archivematica v. 1.15.1, a integração com o repositório SciELO Data como um tipo de fonte de transferência oferece suporte à seleção e ao processamento de conjuntos de dados de pesquisa do Dataverse.
Conforme os detalhes nos arquivos de recursos abaixo, a integração foi projetada com o seguinte escopo de uso:
- A integração atual pressupõe um usuário que tenha uma conta com uma instância do Dataverse e tenha gerado uma chave de API associada, e o mesmo usuário (ou um diferente, autorizado) que tenha acesso a uma instância do Archivematica e serviço de armazenamento que esteja conectado a esse Dataverse por meio da chave de API.
- Você pode ler mais na documentação do Dataverse em "Permissões do Dataverse raiz" sobre usuários, administradores e categorias de superusuário que podem impactar o acesso aos conjuntos de dados do Dataverse por meio da API.
- Presume-se que o usuário tenha obtido os direitos necessários para processar e armazenar arquivos de conjuntos de dados no Dataverse para preservação e tenha acesso apropriado ao conjunto de dados e/ou arquivos associados com base nos direitos relacionados à sua chave de API do Dataverse (veja acima).
- Presume-se que o preservador esteja interessado em selecionar conjuntos de dados específicos em um Dataverse para preservação. SIPs e seus AIPs resultantes são criados a partir de versões atuais de conjuntos de dados do Dataverse com um ou mais arquivos associados nesse conjunto de dados. Um conjunto de dados é, portanto, equivalente a um SIP. Arquivos individuais não podem ser selecionados para preservação, nem versões mais antigas de arquivos. No entanto, os usuários podem fazer uso das funções de avaliação do Archivematica para selecionar arquivos individuais em um conjunto de dados específico para criar um AIP final.
- Atualmente, uma função para automatizar a ingestão de todos os conjuntos de dados em um Dataverse não foi desenvolvida.
Apresentando: Preservando um Conjunto de Dados do Dataverse
Rondineli é um usuário do Archivematica
E ele quer preservar um conjunto de dados publicado em um Dataverse
Definições:
- Conjunto de dados do Dataverse: Um conjunto de dados que foi publicado em um Dataverse, incluindo todos os
arquivos originais enviados para o Dataverse e quaisquer arquivos derivados criados pelo Dataverse. - METS do Dataverse: Um arquivo de metadados usando o padrão METS que descreve um conjunto de dados;
incluindo metadados descritivos, lista de todos os objetos no conjunto de dados, sua estrutura
e relacionamentos entre si.
Cenário: Seleção manual do conjunto de dados
- Dado que o Serviço de armazenamento está configurado para se conectar a um repositório do Dataverse
- E o conjunto de dados foi publicado no Dataverse
- Quando o usuário seleciona o tipo de transferência “Dataverse”
- E o usuário seleciona o conjunto de dados a ser preservado
- E o usuário insere o <Nome da transferência>
- E o usuário insere o <Número de acesso>
- E o usuário clica no botão “Iniciar transferência”
- Então o Archivematica copia os arquivos do Dataverse para um diretório de processamento local
- E o microsserviço Aprovar transferência pede ao usuário para aprovar a transferência
- E o usuário seleciona sim
- E o microsserviço Verificar conformidade de transferência cria o METS do Dataverse
- E os arquivos de metadados do Dataverse são gerados e incluídos em um diretório de metadados
- E o microsserviço Verificar conformidade de transferência confirma que esta é uma transferência válida do Dataverse
- E o microsserviço Verificar somas de verificação de transferência confirma que as somas de verificação fornecidas pelo Dataverse correspondem às geradas para cada arquivo no conjunto de dados
- E o arquivo Mets do AIP inclui os eventos gerados pelo Dataverse
- E o concluído O AIP é armazenado no local de armazenamento especificado do Dataverse
Diagrama do Fluxo de Preservação
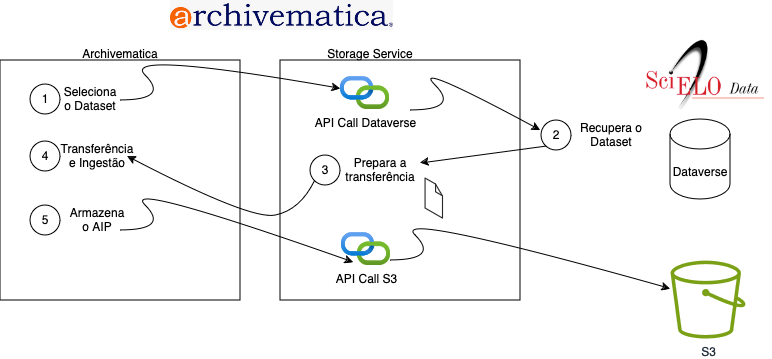
1) O usuário seleciona o conjunto de dados Quando o Serviço de armazenamento é configurado para se conectar ao Dataverse, o Navegador de transferência no Painel exibirá uma lista de todos os Locais de origem de transferência do Dataverse. Os locais de origem de transferência podem ser configurados para filtrar termos de pesquisa ou um Dataverse específico. Os usuários podem navegar pelos conjuntos de dados disponíveis, selecionar um e definir o Tipo de transferência como Dataverse.
2) O serviço de armazenamento recupera o conjunto de dados Os serviços de armazenamento usam a API do Dataverse para recuperar o conjunto de dados selecionado. As credenciais da API são armazenadas no Espaço do serviço de armazenamento.
3) Preparar transferência
O Archivematica cria um arquivo de metadados chamado agents.json que inclui as informações do agente configuradas no serviço de armazenamento. Essas informações são usadas para preencher os detalhes do agente PREMIS nos arquivos METS. Consulte Dataverse#agents.json para obter mais detalhes.
Quando um conjunto de dados inclui um "pacote" de arquivos relacionados para dados tabulares, ele é fornecido como um arquivo .zip. O Archivematica extrai todos os arquivos em pacotes neste estágio. Outros arquivos .zip não são afetados e podem ser extraídos ou não usando as opções de configuração de processamento padrão.
4) Transferência e ingestão
O Archivematica realiza processos de transferência e ingestão usando as opções de configuração de processamento padrão. O processamento adicional para conjuntos de dados do Dataverse inclui
a criação de um METS do Dataverse que descreve o conjunto de dados conforme fornecido pelo Dataverse
verificação de fixidez de arquivos usando somas de verificação fornecidas pelo Dataverse
incluindo metadados do Dataverse (do METS do Dataverse) no METS AIP final
5) Armazene o AIP
O AIP é armazenado em qualquer local que tenha sido configurado. O SciELO Data armazena seus AIPs em um local S3.
Fluxos de trabalho relacionados a pacotes
Pacotes enviados pelo usuário É comum que os usuários do Dataverse façam "dupla compactação" de arquivos ao fazer upload de arquivos para conjuntos de dados. Essa é a prática de compactar arquivos e depois compactá-los novamente uma segunda vez. O Dataverse sempre descompacta os pacotes enviados, mas se os usuários fizerem dupla compactação, eles podem economizar o trabalho de fazer upload de muitos arquivos um por um. Os usuários do Archivematica podem escolher se desejam que esses pacotes sejam extraídos e/ou excluídos posteriormente, definindo a configuração de processamento correspondente apropriada.
Pacotes derivados criados pelo Dataverse Um segundo conjunto de pacotes é criado pelo Dataverse na forma de pacotes derivados. Derivativos são cópias de arquivos em formato tabular que o Dataverse cria a partir de arquivos enviados pelo usuário. O Dataverse entrega esses pacotes ao Archivematica como pacotes zip. Consulte Pacotes para arquivos de dados tabulares para obter mais detalhes abaixo. Consulte o guia do Dataverse sobre ingestão tabular para obter documentação adicional. Esses pacotes são sempre extraídos pelo Archivematica por padrão. Definir a configuração de processamento para não extrair pacotes não funcionará para esse tipo de transferência.
Problemas conhecidos que afetam as transferências
A tabela a seguir resume os problemas conhecidos que afetam o sucesso das transferências individuais: