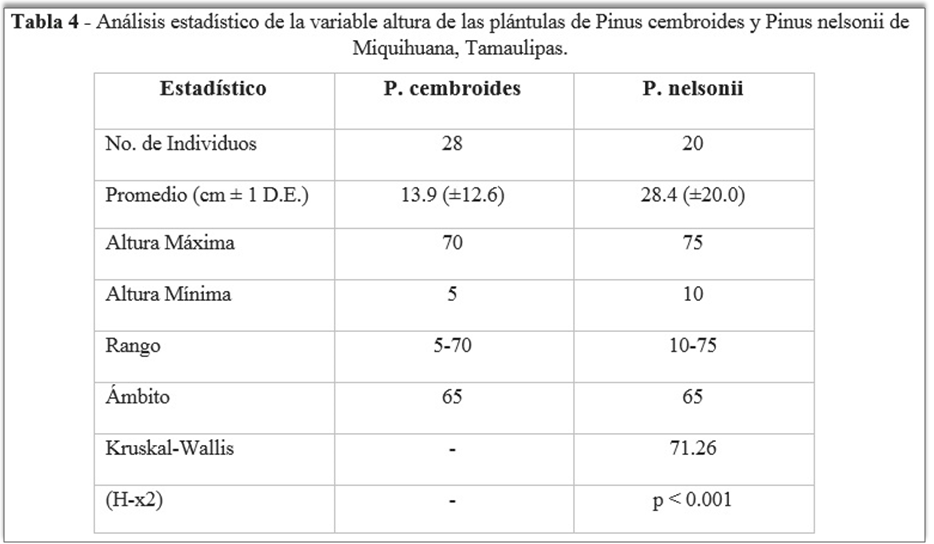
SciELO PC-Programs (Português)
- Pré-requisitos
- Download
- Como instalar
- Como configurar
- Bem-vindo à documentação de SciELO PC Programs!
- Programs
- Code Manager
- Title Manager
- Converter
- XML Converter (XC)
- XML Exporter (for PubMed and ISI)
- SciELO XML to PubMed XML
- Markup Program
- SGML Parser
- XML Package Maker (XPM)
- Instalação
- Workflow of article in HTML / article or text DTD
- Como Produzir e Validar Artigos em XML?
- Preparação de arquivos para o programa Markup
- Como usar o Markup
- Gerando o Arquivo .xml
- Como validar o pacote XML SPS
- Perguntas Frequentes Sobre a Adoção de XML
- How to update the local web site
- Support
- Glossary
- List of codes
Pré-requisitos
Os pré-requisitos são procedimentos/programas que devem ser executados antes da instalação de SciELO PC Programs.
Uma vez cumpridos os requisitos, não é necessário executá-los todas as vezes que o SciELO PC Programs for instalado / atualizado.
Verificar os pré-requisitos
Verificar a localização e situação da pasta serial
Somente para os programas de gestão de coleção, que devem estar instalado em um servidor local.
Este servidor deve ter acesso à pasta serial e esta pasta tem que estar atualizada (title, section, issue etc) antes de executar a instalação de SciELO PC Programs.
Warning
Não atualizar o conteúdo da pasta serial após a instalação. Fazer antes da instalação.
Verificar a instalação de Python + pip
-
Sempre abrir uma nova janela de Terminal para garantir que as atualizações estejam aplicadas na sessão do terminal.
-
Executar o comando no terminal:

-
Verificar se o comando apresenta a versão do Python. Por exemplo:
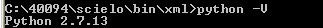
Note
ao executar o comando para verificar a versão do Python não necessariamente ela será igual a da imagem
-
Caso o resultado não seja o esperado, repetir todas as instruções anteriores.
-
Executar o comando no terminal:

-
Verificar se o comando apresenta a versão do pip. Por exemplo:
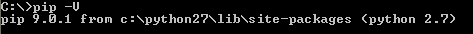
Note
ao executar o comando para verificar a versão de pip não necessariamente ela será igual a da imagem
- Caso o resultado não seja o esperado, reinstalar Python.
Verificar a instalação de Pillow
Pillow é pré-requisito somente para versões anteriores a SciELO PC Programs 4.0.094.
Verificar se foi corretamente instalado, executando os comandos no terminal:
-
Executar python:

-
Verificar que o resultado esperado será a apresentação do terminal do Python.

Note
ao executar este comando a versão de python não necessariamente tem que ser igual a da imagem
-
Executar import PIL (letras maiúsculas):

-
Verificar que o resultado esperado é:

Mas se a mensagem for similar a
reinstalar pillow.
-
Executar exit() para sair do terminal do Python

-
Verificar que saiu do terminal do Python

Verificar a instalação Java
-
Executar no terminal:
-
Verificar se o resultado apresentado é similar a:
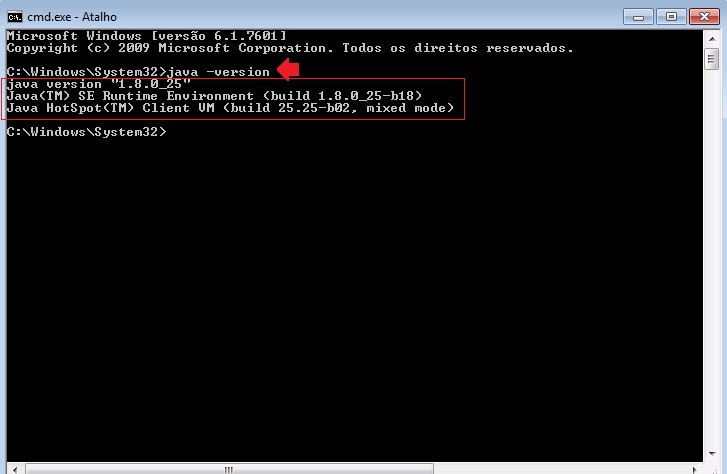
Note
ao executar este comando a versão de java não necessariamente tem que ser igual a da imagem
Caso a mensagem seja: java não é um comando reconhecido …, repetir as instruções desta seção.
Instalar os pré-requisitos
Como instalar Python e pip igual ou superior a 2.7.10
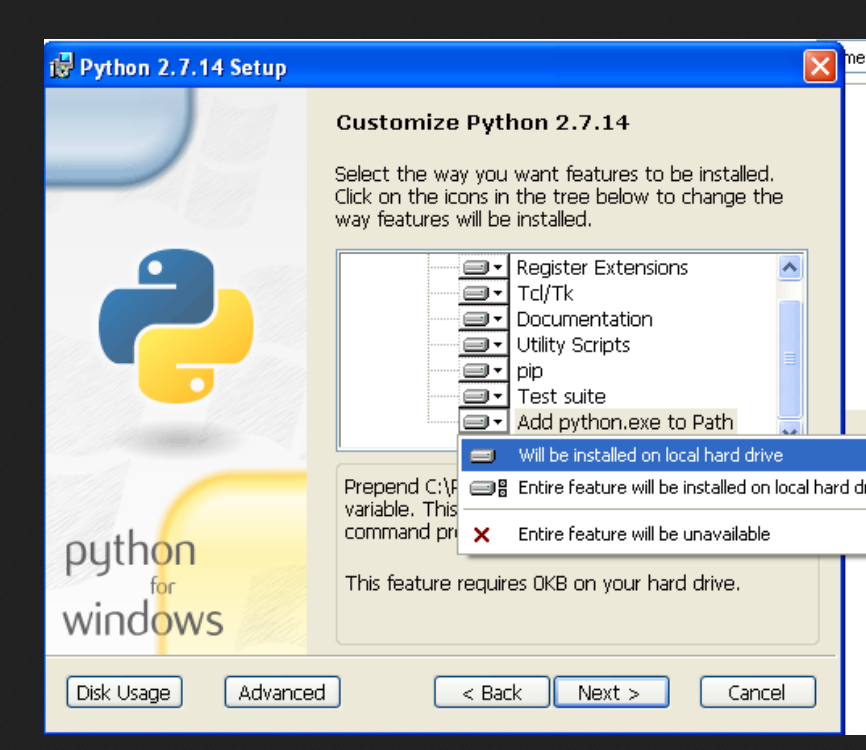
Primeiramente, garantir que tenha apenas uma versão de Python 2.7.x instalada. Caso seja necessário instalar uma versão mais recente de Python, remova a anterior antes de prosseguir.
Ao instalar Python, selecione todas as opções disponíveis, especialmente:
- Add Python to PATH
- pip
Como instalar Pillow
É pré-requisito somente para versões anteriores a SciELO PC Programs 4.0.094.
Executar o comando no terminal:

Como instalar Java
Depois de instalar Java, abrir a “Configuração do Sistema”, indicar a localização do Java instalado para a variável de ambiente PATH.
Adicionar aplicação no PATH
O atalho para abrir a janela é: Windows + Pause Break key.
Ou clique em Computador com o botão direito do mouse.

Então clique em Propriedades.
Configuração do Sistema
Clique em configurações avançadas do sistema
E depois em Variáveis de Ambiente
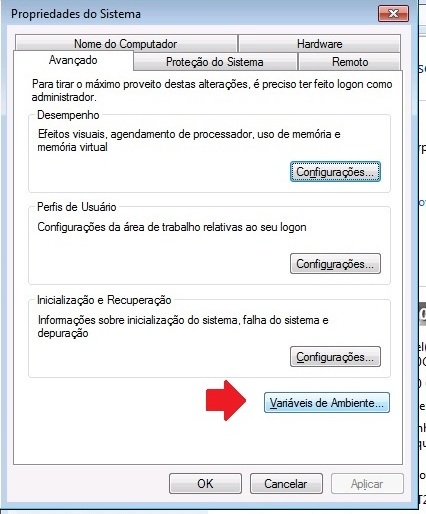
Encontre o caminho da lista de variáveis
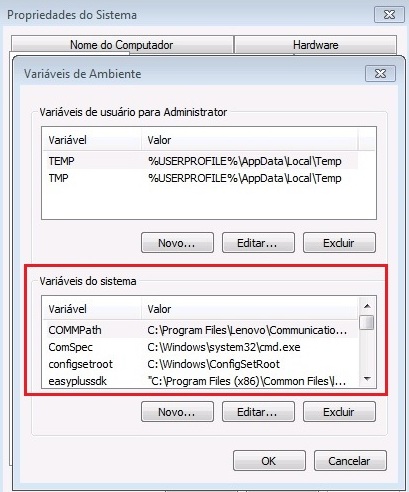
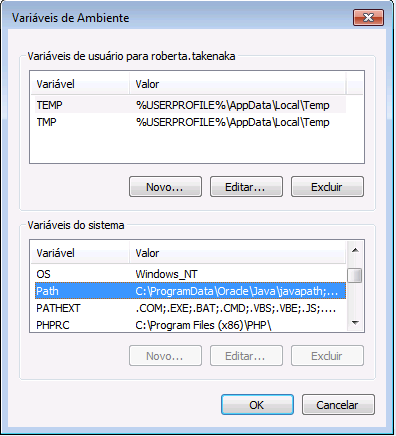
Selecione o Path e clique em Editar
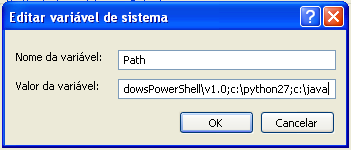
Coloque o cursor no final da linha, acrescente o caracter ponto-e-vírgula (;) e a localização do Java instalado.
Download

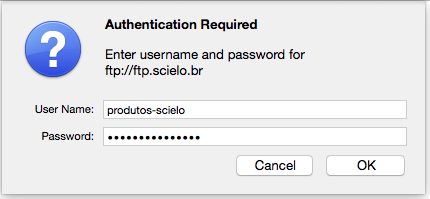
Informar o usuário e senha
- user: produtos-scielo
- password: produtos@scielo
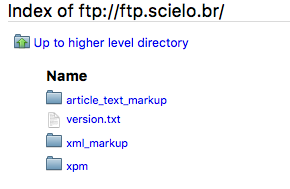
Selecionar a pasta de acordo com os programas que deseja instalar.
- article_text_markup
- para Marcação SGML (article e text DTD)
- xml_markup
- para Marcação XML (doc DTD)
- xpm
- para XML Package Maker
Nota:
Não há mais novos desenvolvimentos para os programas relacionados ao Markup SGML, no entanto, eles podem ser instalados com o instalador que está em xml_markup.
Como instalar
XML Package Maker
-
Instalar e/ou verificar os pré-requisitos
-
Fazer o download dos instaladores
-
Executar o instalador
-
Indicar a localização da aplicação
-
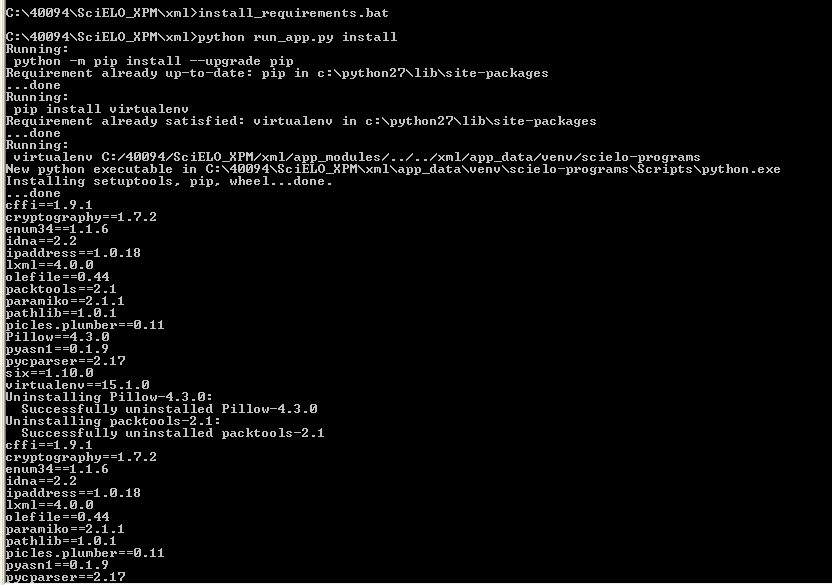
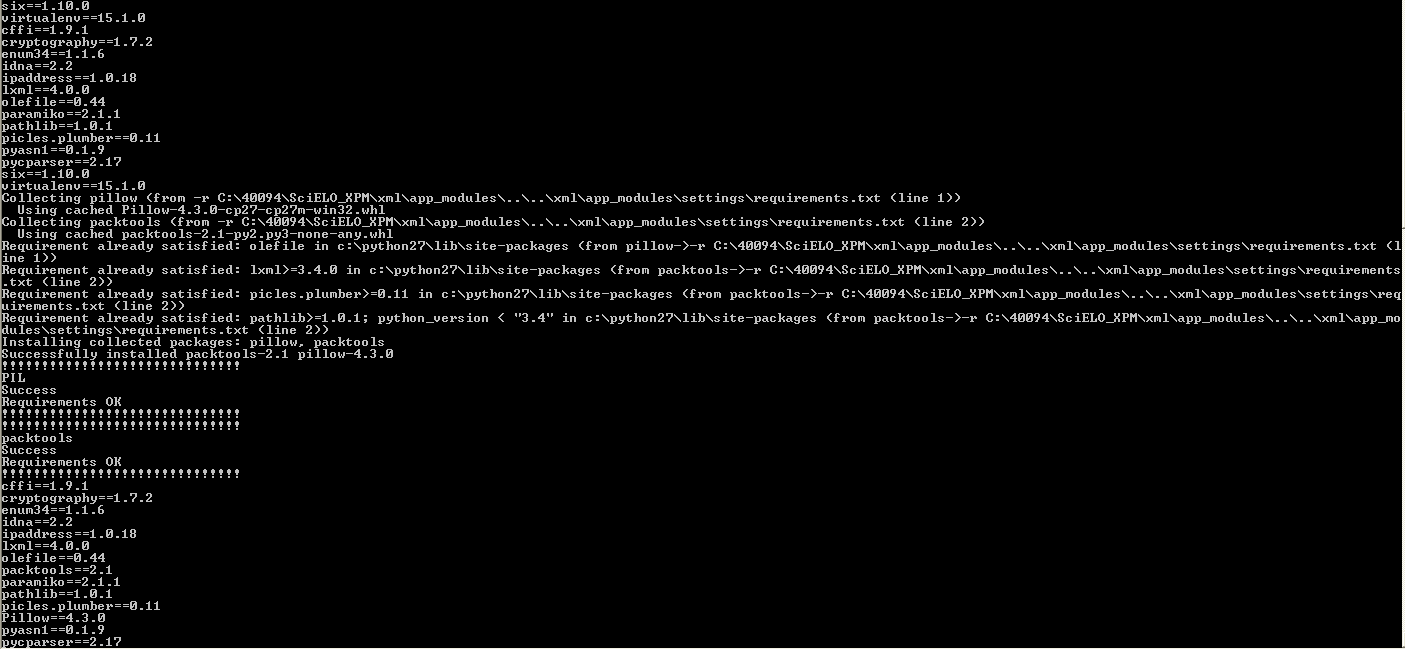
Abrir um terminal (cmd) e executar os seguintes comandos:
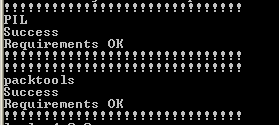
Executar o comando abaixo para entrar na pasta onde está o programa install_requirements.bat:
Exemplo:

Resultado esperado:

Executar o comando abaixo para instalar os pré-requisitos install_requirements.bat:
Exemplo:

Resultado esperado:

Markup
-
Instalar e/ou verificar os pré-requisitos
-
Fazer o download dos instaladores
-
Executar o instalador
-
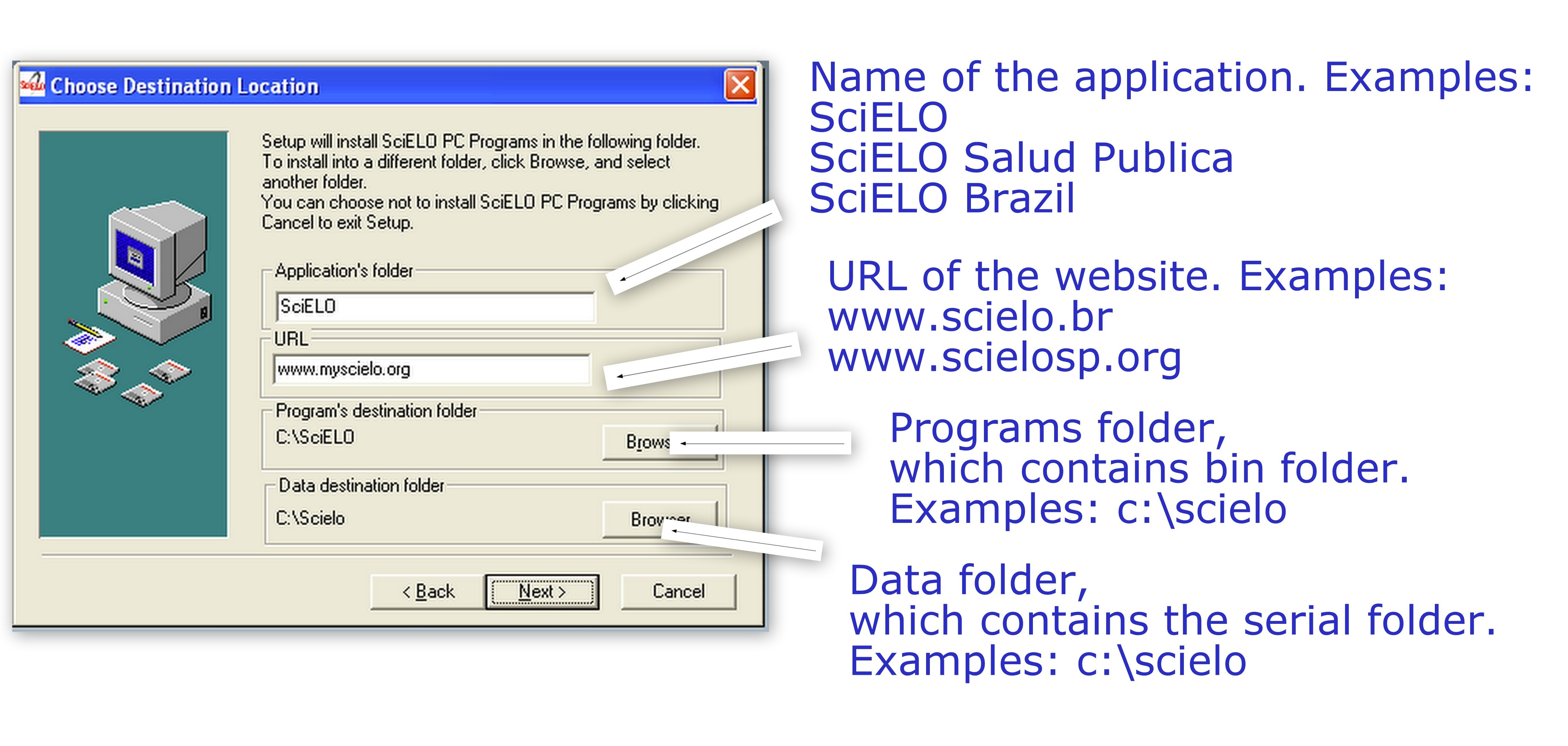
Configurar:
- Application’s folder: complete com o nome da aplicação que aparecerá no Menu de Programas
- URL: endereço do site público da coleção
- Programs’s destination folder: localização da pasta dos programas (bin)
- Data destination folder: localização da pasta dos dados (serial). Repetir o mesmo valor do anterior.
-
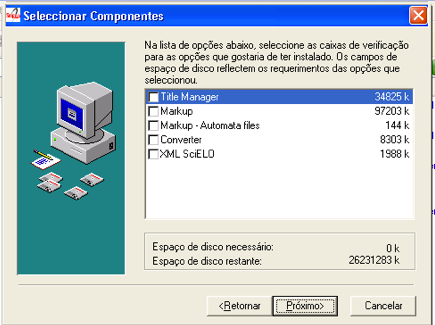
Selecionar:
- Markup: programa para identificar elementos de um artigo/texto
- Markup - Automata files (opcionalmente): examplos de arquivos para marcação automática de referências bibliográficas
-
Abrir um terminal (cmd) e executar os seguintes comandos:
Executar o comando abaixo para entrar na pasta onde está o programa install_requirements.bat:
Exemplo:
Resultado esperado:

Executar o comando abaixo para instalar os pré-requisitos install_requirements.bat:
Exemplo:

Este comando executará várias linhas, mas o resultado principal esperado é:
SciELO PC Programs Completo: Title Manager, Converter, Markup, XPM etc
-
Instalar e/ou verificar os pré-requisitos
-
Fazer o download dos instaladores
-
Executar o instalador
-
Configurar:
- Application’s folder: complete com o nome da aplicação que aparecerá no Menu de Programas
- URL: endereço do site público da coleção
- Programs’s destination folder: localização da pasta dos programas (bin)
- Data destination folder: localização da pasta dos dados (serial).
-
Selecionar os programas:
Title Manager: programa para gestão da coleção de periódicos
Converter: programa de conversão de documentos marcados para a base de dados
XML SciELO: (opcional) programa para criar formato XML para a base de dados PubMed
-
Abrir um terminal (cmd) e executar os seguintes comandos:
Executar o comando abaixo para entrar na pasta onde está o programa install_requirements.bat:
Exemplo:
Resultado esperado:
Executar o comando abaixo para instalar os pré-requisitos install_requirements.bat:
Exemplo:
Este comando executará várias linhas, mas o resultado principal esperado é:
Como configurar
XML Package Maker e XML Markup
Por padrão o programa funciona considerando acesso à Internet disponível, ausência de proxy para acesso à internet e uso do packtools como validador de estrutura de XML (em substituição ao style-checker).
Para os casos em que o acesso à Internet é feito via proxy ou não há acesso à internet é necessário editar o arquivo scielo_env.ini disponível em ?/bin/ com os seguintes parâmetros:
Exemplo dos parâmetros preenchidos:
Title Manager e Converter
Configurar a variável de ambiente: Painel de controle -> Segurança e Manutenção -> Sistema -> Configurações avançadas do Sistema -> Variáveis de ambiente.
Verifique se a variável já existe. Em caso negativo, clique em Novo e adicione o valor.
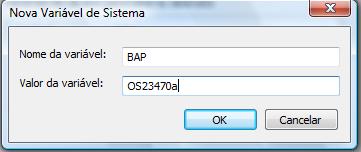
XML Converter
PDF, XML e imagens para o site local
Para que XML Converter copie os arquivos pdf, img, xml para o site local, editar o arquivo correspondente a c:\scielo\bin\scielo_paths.ini, na linha:
Trocar c:\home\scielo\www pela localização do site local. Por exemplo:
Validação de tabelas e fórmulas
Para SciELO Brasil, o padrão de exigência para tabelas e fórmulas é que elas sejam codificadas.
Para alterar este nível, editar o arquivo correspondente a c:\scielo\bin\scielo_collection.ini:
off é para que o XML Converter não exija os elementos codificados ou não bloqueie a publicação devido a discordâncias com os critérios.
Menu de aplicação
Em alguns casos, o menú da aplicação será criado apenas com o usuário de administrador.
Neste caso, copie a pasta SciELO para a pasta Usuários para que todos os usuários tenham o menú disponível.
Como configurar
XML Package Maker
-
Instalar e/ou verificar os pré-requisitos
-
Fazer o download dos instaladores
-
Executar o instalador
-
Indicar a localização da aplicação
-
Abrir um terminal (cmd) e executar os seguintes comandos:
Executar o comando abaixo para entrar na pasta onde está o programa install_requirements.bat:
Exemplo:
Resultado esperado:
Executar o comando abaixo para instalar os pré-requisitos install_requirements.bat:
Exemplo:
Resultado esperado:
Markup
-
Instalar e/ou verificar os pré-requisitos
-
Fazer o download dos instaladores
-
Executar o instalador
-
Configurar:
- Application’s folder: complete com o nome da aplicação que aparecerá no Menu de Programas
- URL: endereço do site público da coleção
- Programs’s destination folder: localização da pasta dos programas (bin)
- Data destination folder: localização da pasta dos dados (serial). Repetir o mesmo valor do anterior.
-
Selecionar:
- Markup: programa para identificar elementos de um artigo/texto
- Markup - Automata files (opcionalmente): examplos de arquivos para marcação automática de referências bibliográficas
-
Abrir um terminal (cmd) e executar os seguintes comandos:
Executar o comando abaixo para entrar na pasta onde está o programa install_requirements.bat:
Exemplo:
Resultado esperado:
Executar o comando abaixo para instalar os pré-requisitos install_requirements.bat:
Exemplo:
Este comando executará várias linhas, mas o resultado principal esperado é:
SciELO PC Programs Completo: Title Manager, Converter, Markup, XPM etc
-
Instalar e/ou verificar os pré-requisitos
-
Fazer o download dos instaladores
-
Executar o instalador
-
Configurar:
- Application’s folder: complete com o nome da aplicação que aparecerá no Menu de Programas
- URL: endereço do site público da coleção
- Programs’s destination folder: localização da pasta dos programas (bin)
- Data destination folder: localização da pasta dos dados (serial).
-
Selecionar os programas:
Title Manager: programa para gestão da coleção de periódicos
Converter: programa de conversão de documentos marcados para a base de dados
XML SciELO: (opcional) programa para criar formato XML para a base de dados PubMed
-
Abrir um terminal (cmd) e executar os seguintes comandos:
Executar o comando abaixo para entrar na pasta onde está o programa install_requirements.bat:
Exemplo:
Resultado esperado:
Executar o comando abaixo para instalar os pré-requisitos install_requirements.bat:
Exemplo:
Este comando executará várias linhas, mas o resultado principal esperado é:
Como configurar
XML Package Maker e XML Markup
Por padrão o programa funciona considerando acesso à Internet disponível, ausência de proxy para acesso à internet e uso do packtools como validador de estrutura de XML (em substituição ao style-checker).
Para os casos em que o acesso à Internet é feito via proxy ou não há acesso à internet é necessário editar o arquivo scielo_env.ini disponível em ?/bin/ com os seguintes parâmetros:
Exemplo dos parâmetros preenchidos:
Title Manager e Converter
Configurar a variável de ambiente: Painel de controle -> Segurança e Manutenção -> Sistema -> Configurações avançadas do Sistema -> Variáveis de ambiente.
Verifique se a variável já existe. Em caso negativo, clique em Novo e adicione o valor.
XML Converter
PDF, XML e imagens para o site local
Para que XML Converter copie os arquivos pdf, img, xml para o site local, editar o arquivo correspondente a c:\scielo\bin\scielo_paths.ini, na linha:
Trocar c:\home\scielo\www pela localização do site local. Por exemplo:
Validação de tabelas e fórmulas
Para SciELO Brasil, o padrão de exigência para tabelas e fórmulas é que elas sejam codificadas.
Para alterar este nível, editar o arquivo correspondente a c:\scielo\bin\scielo_collection.ini:
off é para que o XML Converter não exija os elementos codificados ou não bloqueie a publicação devido a discordâncias com os critérios.
Menu de aplicação
Em alguns casos, o menú da aplicação será criado apenas com o usuário de administrador.
Neste caso, copie a pasta SciELO para a pasta Usuários para que todos os usuários tenham o menú disponível.
Bem-vindo à documentação de SciELO PC Programs!
SciELO PC Programs é um conjunto de ferramentas para produzir entrada de dados para o processo de publicação de artigos em uma coleção SciELO.
Para a Produção de XML:
- XML Package Maker
- valida pacotes de XML SciELO PS produzidos por quaisquer ferramentas;
- uso obrigatório para a produção de pacotes XML validados de acordo com SciELO PS.
- Markup
- macro para Word para identificar os elementos estruturais e semânticos dentro de um texto;
- adaptado para gerar o XML segundo SciELO PS a partir da identificação destes elementos;
- uso opcional já que é permitido e incentivado a usar quaisquer ferramentas para produzir os XML de acordo com o SciELO PS.
Para Gestão de Coleções (para uso somente das Coordenações de uma Coleção SciELO):
- Title Manager;
- Converter;
- XML Converter;
- XML SciELO (Exportador de XML para outras bases: ISI e PubMed)
- Instalação
- Programs
- Workflow of article in HTML / article or text DTD
- Como Produzir e Validar Artigos em XML?
- How to update the local web site
- Support
- Glossary
- List of codes
- acquisition priority
- alphabet of title
- article status
- authidtp
- blcktype
- corresp
- count
- country
- ctdbid
- date
- dateiso
- deceased
- deposid
- doctopic
- doctype
- eqcontr
- fntype
- frequency
- from
- ftp
- ftype
- hcomment
- history
- historystatus
- id
- idiom interface
- illustrative material type
- indexing coverage
- issn type
- issue status
- keyword priority level
- language
- license_text
- lictype
- listtype
- literature type
- month
- no
- orgdiv
- orgdiv1
- orgdiv2
- orgdiv3
- orgname
- pages
- pii
- publication level
- pubtype
- ref-type
- rid
- role
- scheme
- scielonet
- sec-type
- standard
- state
- status
- stitle
- study area
- table of contents
- to
- toccode
- treatment level
- usersubscription
- version
- Annexes
Programs
Databases Managers (Local server)
Programs to manage journals, issues and articles databases.
Markup and Validators (Desktop)
Programs to generate and validate SGML/HTML or XML files.
Code Manager
Desktop application (Visual Basic, CDS/ISIS database) to manage the tables of codes/values used by SciELO Methodology.
Used in the Local Server
This program is only used if it is necessary to change data of the customizable tables (newcode database)
Opening the program
Or use the Windows Explorer:
c:\scielo\bin\codes\codes.exe
(or corresponding to c:\scielo)
Managing the tables
- Select File > Open:
- Restricted Area is used only by SciELO Methodology team. It is password protected. (Code database)
- Customizing Tables is to manage the customizable tables. (Newcode database)
Accessing a table
Select the name of one of the tables, then click on the […] button.
The program will display the selected table:
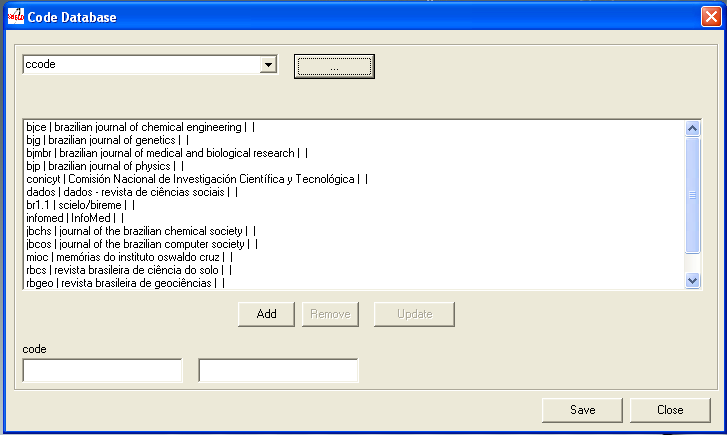
The data of the table will be presented as: code | label in Portuguese | Spanish | English. But if there is no dependence on any language, only one column is displayed.
Removing a row of the table
- Select a row to delete. Its data will be presented at code and labels fields of each language.
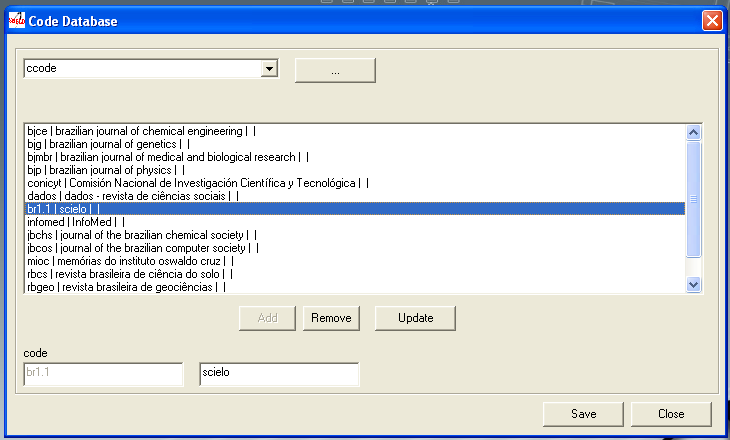
- Click on Remove button.
- Click on Save button.
Updating a row of the table
- Select a row to update. Its data will be presented at code and labels fields of each language.
- Change the data.
- Click on Update button. The updated row will be displayed in the list.
- Click on Save button
Creating a new row
- Fill in the fields: code and label of each language or only one if it is not depending on a language.
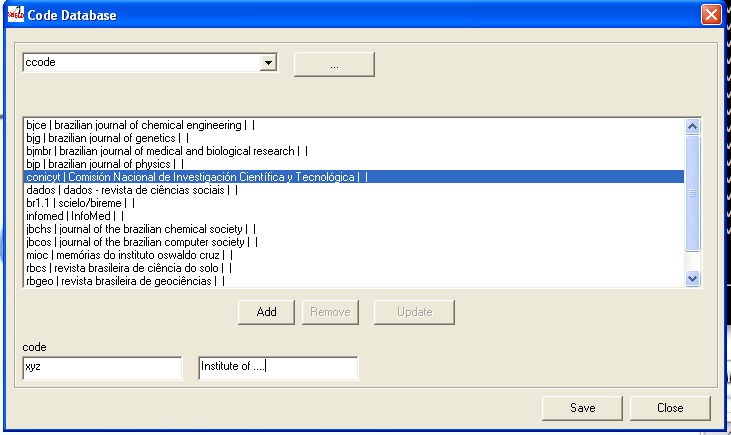
- Click on Add button.
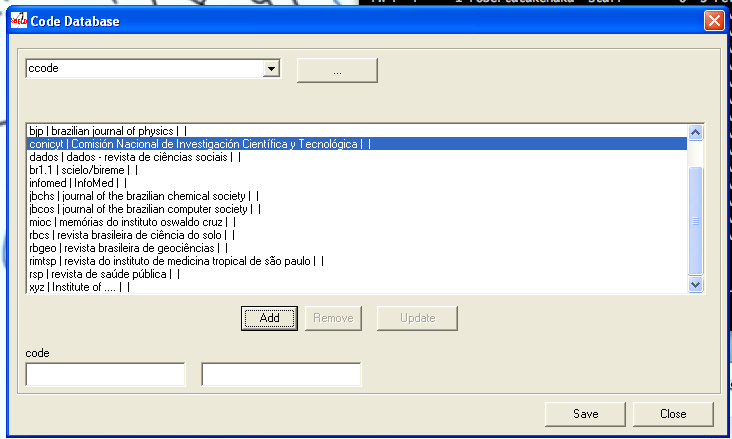
The new row will be displayed at the end of the list.
Title Manager
Desktop Application (Visual Basic), used in the Local server, to manage the databases: title, issue and section, it means, respectively the data of journals, their issues and sections of the table of contents.
Prevent installation errors
Read:
Warning
If Title Manager does not open properly, reinstall the programs.
Opening the program
Converter
Desktop Application (Visual Basic), installed in the local server, to generate the database of the documents, by reading the files from markup and body folders and the databases in title and issue folders.
How to open the program
Or by the path of the program:
c:\scielo\bin\convert\convert.exe
How to change the language of the program
The programs are available in Portuguese, Spanish and English.
How to use the program
- Select Files > Open.
- Fill the fields:
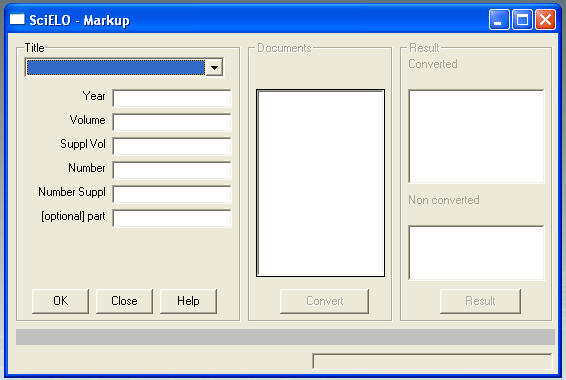
-
- journal’s title:
- select the title of the journal.
-
- year:
- FILL ONLY if it is ahead number
-
- volume:
- fill it in with the volume
-
- supplement of volume:
- fill it in with the supplement of volume, if it is applicable
-
- number:
- fill it in with the number. If it is an ahead of print, use ahead, respectively
-
- supplement of number:
- fill it in with the supplement of number, if it is applicable
-
- complement:
- fill it in, if it exists. Recently it is used to press release, fill it in with pr.
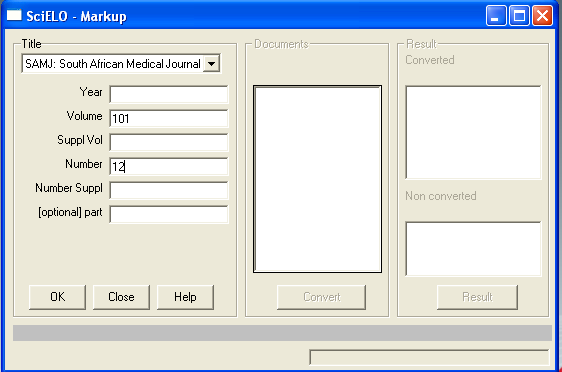
- Click on OK button.
- Converter uses these data to identify the issue, markup and body folders. If the data are correct, the program will list the markup files.
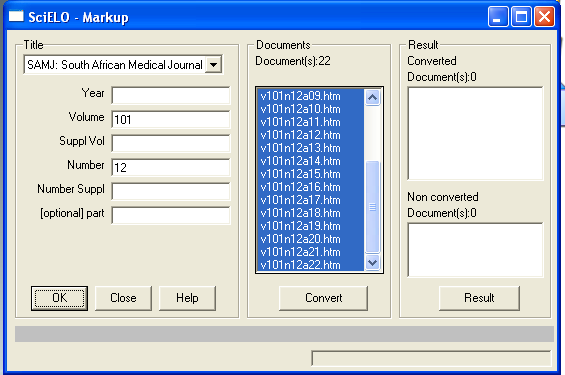
-
Click on Convert button.
-
Converter will convert the selected files.
For each file, the program:
- extracts the identified data
- compares the data in the document and the data in the issue database
Attention
If there are any unmatched data related to the issue, the program will not create the database. It will be necessary to correct the data in Markup or in Title Manager
If the database is generated, the result will be shown on the screen.
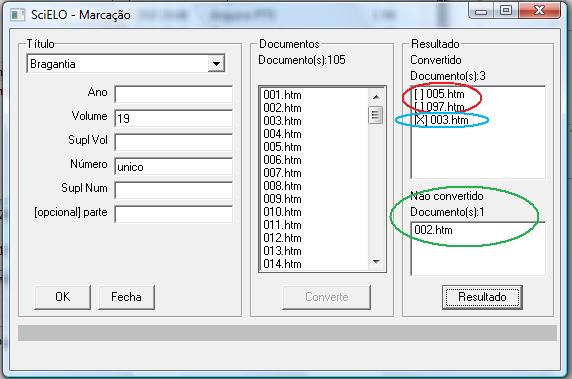
Results:
- successfully converted: [ ] (in red)
-
- converted, with errors: [X] (in blue)
- There are some not fatal markup errors, which could have been corrected at SGML Parser stage.
-
- not converted: (in green)
- It is related to unmatched data of the issue database and the data in the markup file. For instance: - The issue’s volume is 30, and the volume in the document is 3. The program will indicates an error. In this case, the correction is in the markup file.
-
Click on each file in the result area, then on Result button, to view the result of the convertion.
Successfully converted
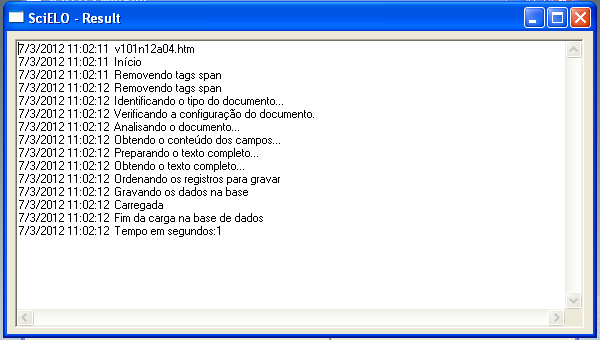
Converted, but no fatal errors: markup error
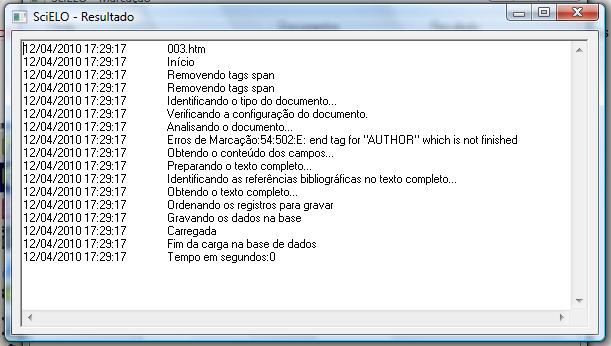
Converted, but no fatal error: some bibliography references not identified
Converter also marks, in the body file, the end of the paragraph of each bibliography reference found in markup file. It is used by the website to create [ Links ] at the end of the paragraph of each reference.

If Converter was not able to find the markup references in body references:
It is necessary to evaluate the references in markup and in body. There must be some different character that causes the error.
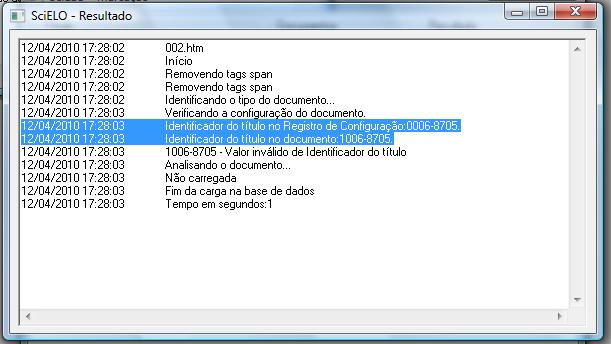
Not converted, because of fatal errors
XML Converter (XC)
It is a tool to generate CDS/ISIS databases in the serial folder to generate the Web site.
How to use
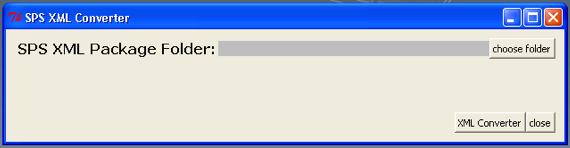
Select the folder which contains XML package files
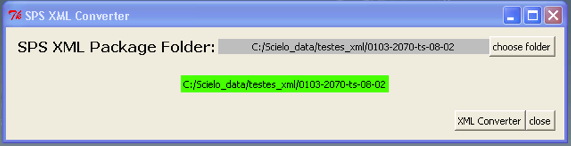
Press XML Converter.
Unable to identify the issue
If XC was unable to identified the issue, the output folder (0103-2070-ts-08-02_xml_converter_result) is generated in the same folder which contains the input folder (0103-2070-ts-08-02) and it contains:
- XML files for SciELO (scielo_package and/or scielo_package_zips folders)
- XML files for PMC (pmc_package folder)
- report files (errors folder)
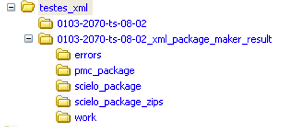
Package has a valid issue
If XC has identified the issue, the results will be generated in the corresponding folder in the serial folder.
For instance, serial/ts/v8n2.
Results
- base: CDS/ISIS database, used to generate the Web site.
- base_xml/id: files used to generate base contents
- base_xml/base_source: XML package files
- base_xml/base_reports: reports (xml_converter.html)
- windows: (optional) if it does not run in Windows, windows is generated in order to export base in Windows format.
If in the computer there is an instance of SciELO Web site, the images, pdf, etc are copied to the corresponding folders in the SciELO Web site.
- htdocs/img/revistas/<acron>/<issue_id>/
- bases/pdf/<acron>/<issue_id>/
- bases/xml/<acron>/<issue_id>/
Reports
After finishing the processing the reports are displayed in a Web browser.
Switch between the tabs.
Some reports are the same generated by XPM. Consult its documentation.
Summary report
Conversion status
Presents the files according to the conversion results:

- converted
- files for which the database was successfully generated
- deleted incorrect order
- files which order was incorrect
- not converted
- files for which the database was failed to generate
- rejected
- files were rejected because they have fatal errors in issue’s data.
- skipped conversion
- files which were not necessary to convert because they have no changes since last conversion
AOP Status

Presents information about AOP.
If the journal has aop documents, presents the deleted ex aop and files which continue as aop.
Detail report
Presents the documents in a table.
The columns order, aop pid, toc section, @article-type are hightlighted because contain important data.
The column reports contains buttons to open/close the detail reports of each document.
Each row has the document’s data.

XC checks if the data found in XML are the same which were registered in the issue’s forms (Title Manager or SciELO Manager).
Presents the results of these validations.
Database overview
Presents the package’s data and the status of database before the conversion.
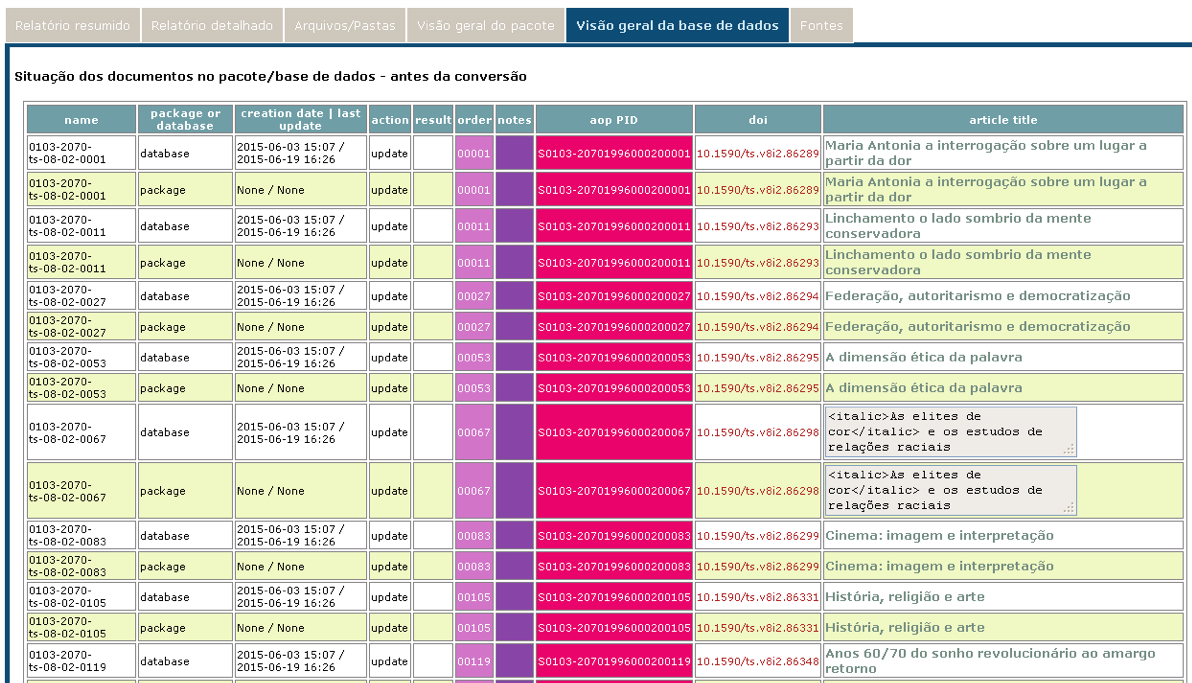
Presents the status of the database after the conversion.
XML Exporter (for PubMed and ISI)
DOS Batch program to export XML and SGML files to PubMed and ISI. Located in c:\scielo\xml_scielo.
For PubMed, there are two types of files:
-
- Journal data:
- http://www.ncbi.nlm.nih.gov/books/bv.fcgi?rid=helplinkout.section.files.Resource_File#files.Resource_File_Format. Sent once or every time the journal data was changed.
-
- Articles data:
- http://www.ncbi.nlm.nih.gov/entrez/query/static/spec.html Sent one XML file for each issue.
Configuration
If it is the first installation, you have some procedures to execute.
There is a file in c:\scielo\xml_scielo\config.example. You have to copy and rename it to config.
Configure the files:
- PubMed\doi_conf.txt
- PubMed\config\config.seq
- PubMed\journals\journals.seq
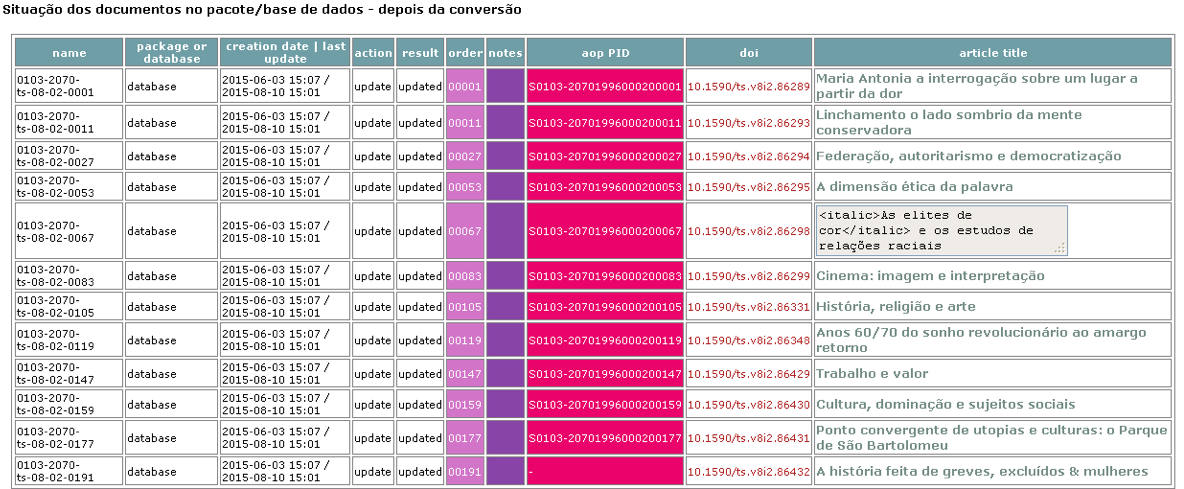
File doi_conf.txt
It contains the data of the Publisher and the prefix given by CrossRef, according to the agreement signed by CrossRef and the SciELO of each country. IF YOUR SCIELO DOES NOT HAVE IT. SO THIS FILE MUST BE EMPTY.
INSTITUTION SPACE E-MAIL SPACE PREFIX
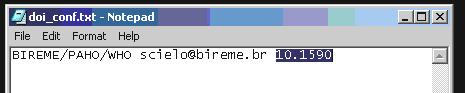
File config\config.seq
The file configconfig.seq is to inform to the program which articles or text must not be sent to PubMed, because some kind of documents are not accepted, and it is know by the section in the table of contents.
Acronym space sectionId
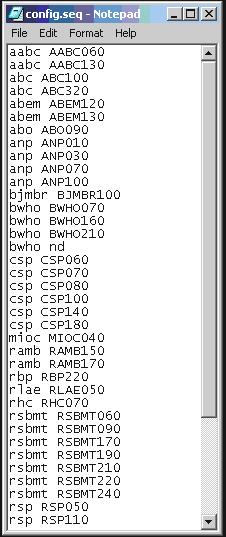
File journals\journals.seq
This file journals\journals.seq contains data used to generate XML file of the journal: journals_acronimo.xml.
This is the first XML file which must be sent to PubMed in order to register the journal. Read more: http://www.ncbi.nlm.nih.gov/books/bv.fcgi?rid=helplinkout.section.files.Resource_File#files.Resource_File_Format.
Its format is:
ACRONYM SPACE FIRST_YEAR_IN_PubMed SPACE SCIELO_URL SPACE ISSN
One line for each journal.
Executing
It has to be executed using the command line in DOS.
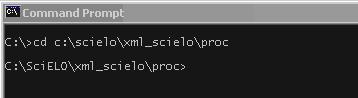
Go to the folder where this program is installed. E.g.: c:\scielo\xml_scielo\proc.
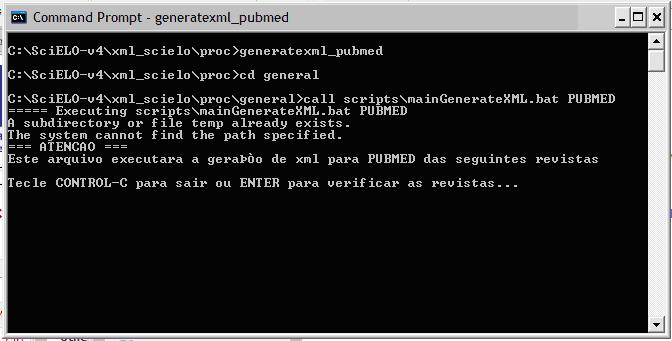
In proc you will find three scripts:
-
GenerateXML_all.bat: generates at the same time ISI and PubMed
-
GenerateXML_ISI.bat: generates SGML to ISI
-
GenerateXML_PubMed.bat: generates XML to PubMed
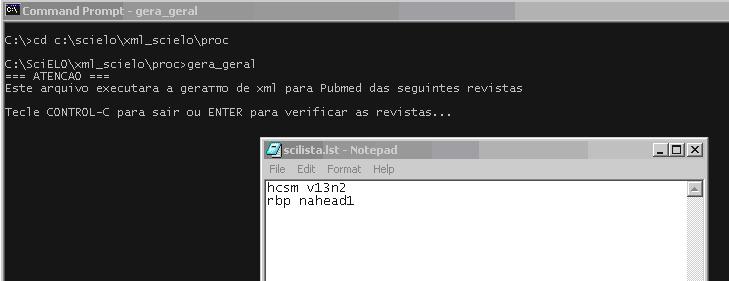
Provide a list similar to scilist, to execute any of them.
The program will open the scilist file and you have to check it, and include or remove lines, according to what you want to generate.
To generate also the XML file which contains journal data, journals_<acronimo>.xml, add one more parameter “YES”:
To generate ONLY the XML file which contains journal data, journals_<acronimo>.xml, the second parameter must be “NONE” and third one must be YES.
To generate XML file of ahead articles, use as:
- fourth parameter: the start date
- fifth parameter: the end date
The program will generate the XML file for articles which has ahpdate (publication date of ahead) between 20140100 and 20140228.
The name of the XML file will be hcsm2014nahead20140100-20140228.xml.
SciELO XML to PubMed XML
Program to export XML to PubMed, according to http://www.ncbi.nlm.nih.gov/books/NBK3828/, using SciELO XML (SciELO Publishing Schema).
How to execute
Double clicking on c:\scielo\bin\xml\xml_pubmed.py
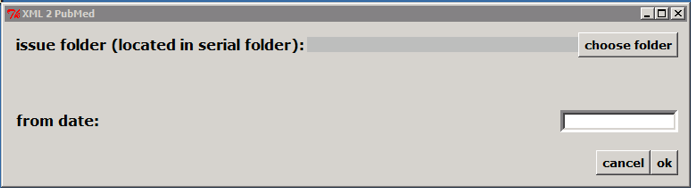
Select the issue folder
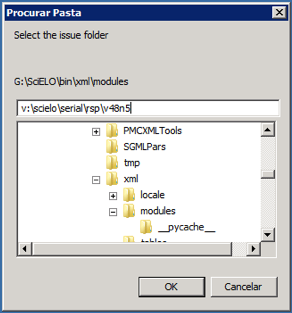
Only if issue is published on batches, such aop or rolling pass, you should inform from date to generate XML for the article published from this date to the current date.
Then click on OK button.
According to the example, the program will create the file: v:\scielo\serial\rsp\v48n5\PubMed\rsp-v48n5-20160510-20160523.xml, containing articles which have epub date between 20160510 and the current date.
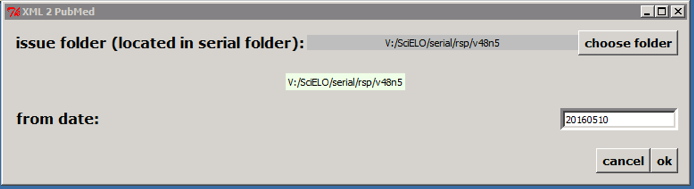
If it is not an issue published on batches, click on OK button. According to the example, the program will create the file: v:\scielo\serial\rsp\v48n5\PubMed\rsp-v48n5.xml.
Or execute it on a terminal:

Optionally informing the from date

SciELO XML to PubMed XML
Program to export XML to PubMed, according to http://www.ncbi.nlm.nih.gov/books/NBK3828/, using SciELO XML (SciELO Publishing Schema).
How to execute
Double clicking on c:\scielo\bin\xml\xml_pubmed.py
Select the issue folder
Only if issue is published on batches, such aop or rolling pass, you should inform from date to generate XML for the article published from this date to the current date.
Then click on OK button.
According to the example, the program will create the file: v:\scielo\serial\rsp\v48n5\PubMed\rsp-v48n5-20160510-20160523.xml, containing articles which have epub date between 20160510 and the current date.
If it is not an issue published on batches, click on OK button. According to the example, the program will create the file: v:\scielo\serial\rsp\v48n5\PubMed\rsp-v48n5.xml.
Or execute it on a terminal:
Optionally informing the from date
Markup Program
Markup program is a desktop Application (macro in Microsoft Office Word), to identify bibliographic elements in documents, according to SciELO DTD for article and for text, based on standard ISO 8879-1986 (SGML - Standard Generalized Markup Language) and ISO 12083-1994 (Electronic Manuscript Preparation and Markup). Nowadays there is a new SciELO DTD: doc. It is simpler than article and text because there are less levels, but by the other hand, there are more elements to identify. It must be used to identify the elements to generate XML according to SPS.
Functionalities
How to open
Or use Windows Explorer and click on markup.exe:
c:\scielo\bin\markup\markup.exe
Word Program location
Markup Program will try to open the Microsoft Office Word Program. If it is unable to open it, inform the correct path of Microsoft Office Word Program.
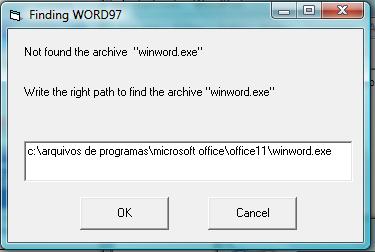
Or edit, c:\scielo\bin\markup\start.mds, inserting the Microsoft Office Word path. E.g.:
“c:\arquivos de programas\microsoft office\office11\winword.exe”
Enabling macro execution
Markup Program requires permission to run macros
Markup button
If Word program opens properly, Markup bar will appear at the bottom of the screen.
From Word 2007, it is different. The Markup bar will appear inside the Supplement group.
Loading macro manually
If there is no Markup button. You can try to load the macro manually.
Select the Tools->Supplements and Models option of the menu.
Remove the incorrect item and inform the right path corresponding to c:\scielo\bin\markup\markup.prg.
Overview
- Open only one file of article or a text file (.doc or .html).
- Click on Markup button.
- Click on Markup DTD-SciELO.
- white: operations over the document: edit or eraser a tag and automatic markup
- orange: floating tags, which can be used in any part of the document
- green: tags which requires an hierarchical structure
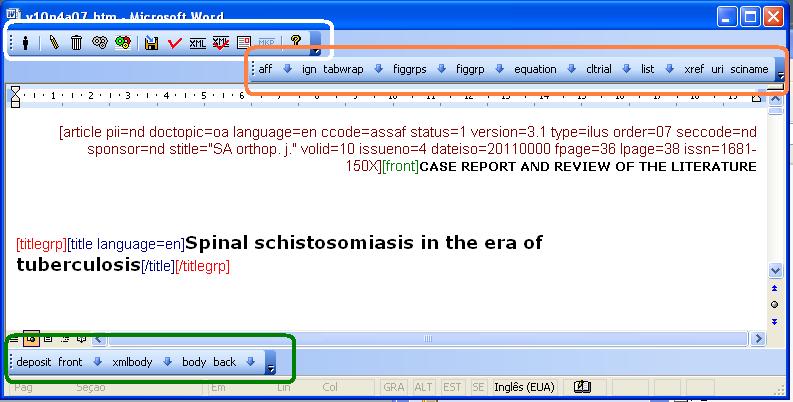
From Word 2007, all these tags bars are grouped in Supplements.
Operations bar

Exit button

To exit the program, click on Exit button.
Choose one of the options bellow.
Edition tag’s attribute button

To edit attributes of an element, click on the element name, then click on the edit button (pencil). Edit the values of the attributes, then confirm this action.
Delete tag button

To delete one element and its attributes, click on the element name, then click on the delete button. The program will ask to confirm this action.
Save file button

To save the file, click on the save button.
Automata 1 button

To identify automatically the elements of the bibliographic references:
It requires that the journal has an automata file (read how to program an automata), which configures the rules to identify the references elements.
- Click on a paragraph of one bibliographic reference
- Click on the Automata 1 button.
This action will activate a tool which will try to identify automatically the bibliographic reference elements. The tool will present the several possibilities of identification. Choose the correct one.
Automata 2 Button

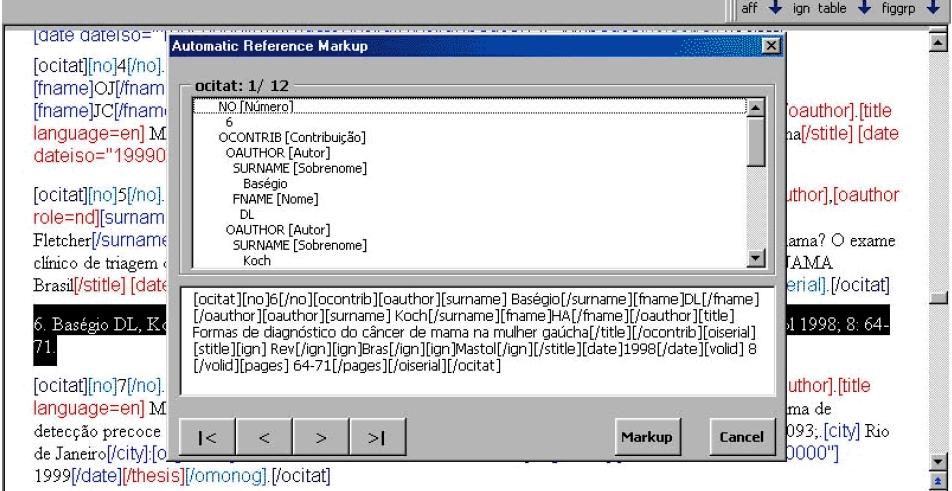
To identify automatically a set of bibliographic references (available only for Vancouver standard).
- Select one or more bibliographic references
- Click on the Automata 2 button.
The program will try to identify all the references, keeping the original reference identified as [text-ref]. Thus the user can compare the original to the detailed identification in order to check if the reference was properly identified, and correct it, if necessary.
Automata 3 button

To identify automatically the elements of the bibliographic references:
It requires that the journal has to adopt a standard (APA, Vancouver, ABNT, ISO)
- Click on a paragraph of one bibliographic reference
- Click on the Automata 3 button.
This action will activate a tool which will try to identify automatically the bibliographic reference elements. The tool will present the several possibilities of identification. Choose the correct one.
Save button
SGML Parser button

Generate XML button
After identifying all the elements of the document, click on this button to generate the XML file.
Files and DTD errors report button

SciELO Style Checker report button

Contents Validations report button

PMC Style Checker report button

View Markup button
The operations bar would be presented with some buttons unavailable when any report is displayed.


Floating tags bar

Hierarchical tags bar
This bar groups the elements which follow an hierarchical structure.
The highest level are doc, article, text.

Tag
- Select the text you want to identify.
- Click on the tag button which identifies the text. For example: to identify the first name of an author, select the text corresponding to the first name, then click on fname.
- Some elements have attributes. Complete the form with the values of their attributes.
- Some elements have children (agroup other elements). As it is identified, the bar of the lower level is displayed.
Read the SciELO Markup Elements and Attributes
Navigation
The down and up arrows button are used to navigate between the levels.

For example:
Down
Bar of front element

Bar of front element’s children

Bar of titlegrp element’s chidren
Up


Error messages
- The user has not filled the attribute field with a valid value
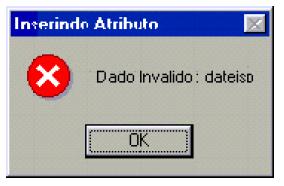
- The user clicked on a tag which is not allowed in a incorrect place (it is not according to the DTD).
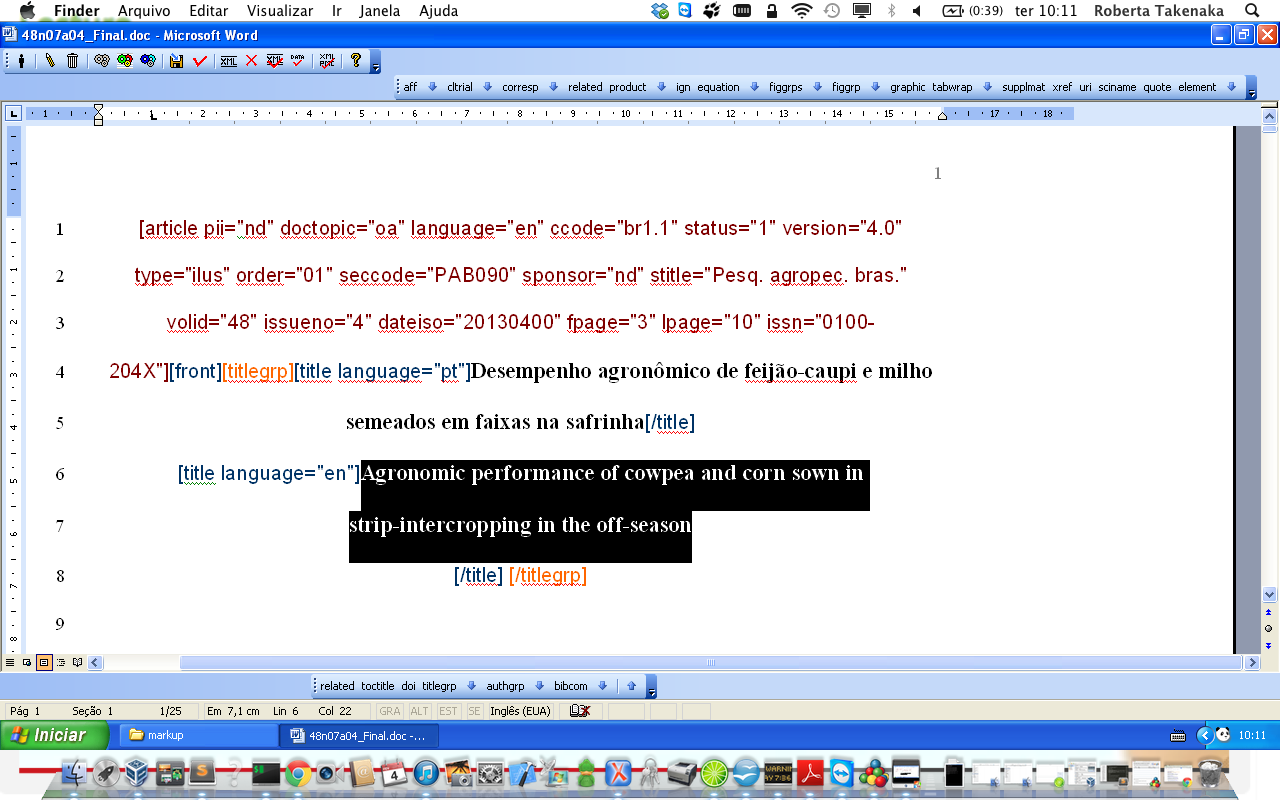
The selected text is inside title and the user clicks on authgrp, which is not allowed inside title.
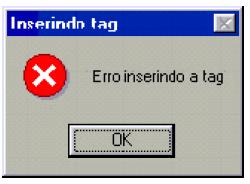
This message is also displayed if the selected text contains tags or part of tags.

Last update of this page: July 2015
SGML Parser
SGML Parser is a desktop application (Visual Basic, C and sp120.dll library), to validate if the document was identified according to DTD SciELO.
This program can be executed:
- from Markup
- Embedded in Converter, for internal use, to analyze and get the value of the elements and their attributes.
- as stand-alone application
Executed from Markup Program
To execute the SGML Parser from Markup, click on the button:
The file, which is open in the Markup program, is saved as .txt and is open in SGML Parser program.
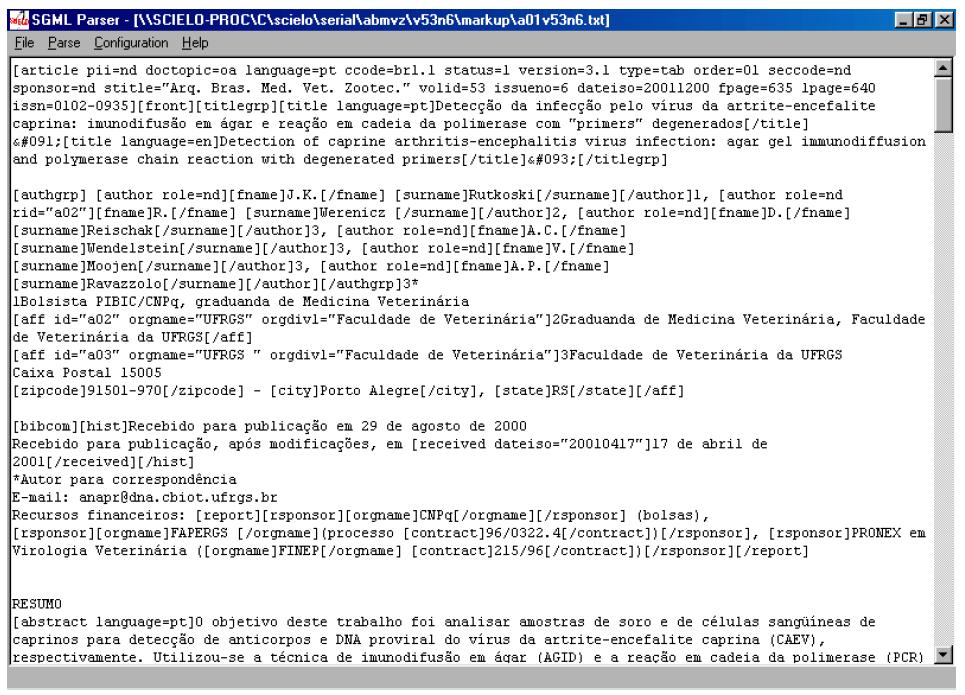
Executed embedded in Converter
Converter uses SGML Parser to validate the files but also to get the identified contents, in order to load them in the database.
During this process, some markup errors can be found. To view the errors:
- open the SGML Parser program as stand-alone application
- open the *.sci file
- execute the program
Executed as stand-alone application
Open the SGML Parser program using the Windows menu.
Configuration
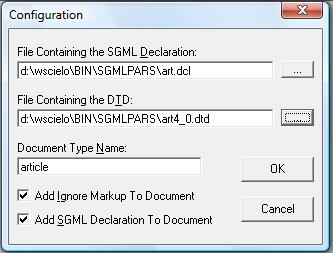
The options below must be checked:
- Add ignore markup to document
- Add SGML declaration to document
The other fields, for:
- article:
- File Containing the DTD = C:\SCIELO\BIN\SGMLPARS\article4_0.dtd
- Document Type Name = article
- text:
- File Containing the DTD = C:\SCIELO\BIN\SGMLPARS\text4_0.dtd
- Document Type Name = text
Document analysis
After the configuration, the user have to click on Parse menu option in order to analyze the document.
If everything is correct, the message bellow is presented:
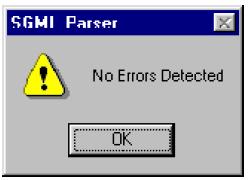
Then, the user can exit the program.
If there are errors, the SGML Parser will indicate the line and the error type occured. In this case, the user must go back to Markup program, make corrections, then repeat the procedure of using SGML Parser until there is no error.
XML Package Maker (XPM)
It is a tool to generate XML packages for SciELO and PMC.
How to use
Select the folder which contains XML package files

Press XML Package Maker.
Or, to execute Package Maker via command line, open the terminal and go to the folder where the program is installed:
Then type:
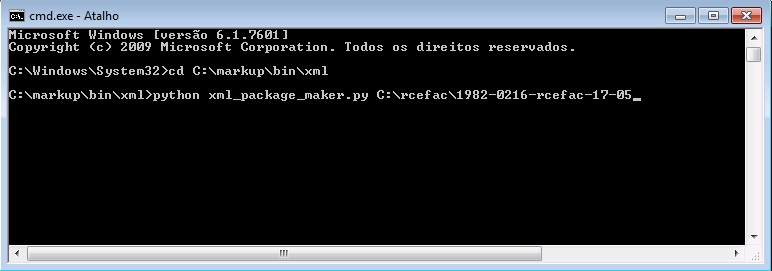
Results
- XML files for SciELO (scielo_package and/or scielo_package_zips folders)
- XML files for PMC (pmc_package folder)
- report files (errors folder)
The output folder (0103-2070-ts-08-02_xml_package_maker_result) is generated in the same folder in which contains the input folder (0103-2070-ts-08-02)
Reports
After finishing the processing the reports are displayed in a Web browser.
Switch between the tabs.
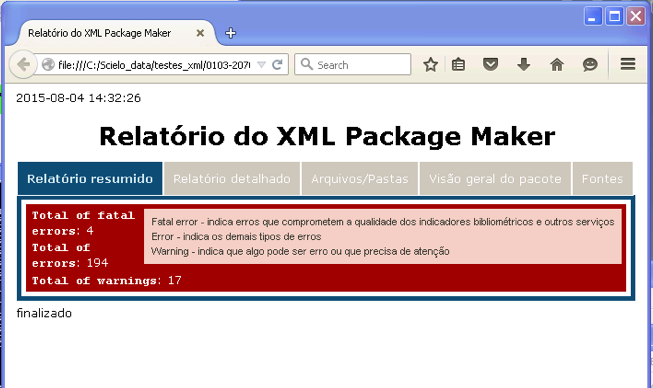
Summary report
Validations Statistics
Presents the total of fatal errors, errors, and warnings, found in the whole package.
- FATAL ERRORS
- represents errors related to Bibliometrics Indicators.
- ERRORS
- represents other types of errors
- WARNINGS
- represents something that needs more attention
Detail report
Detail report - package validations
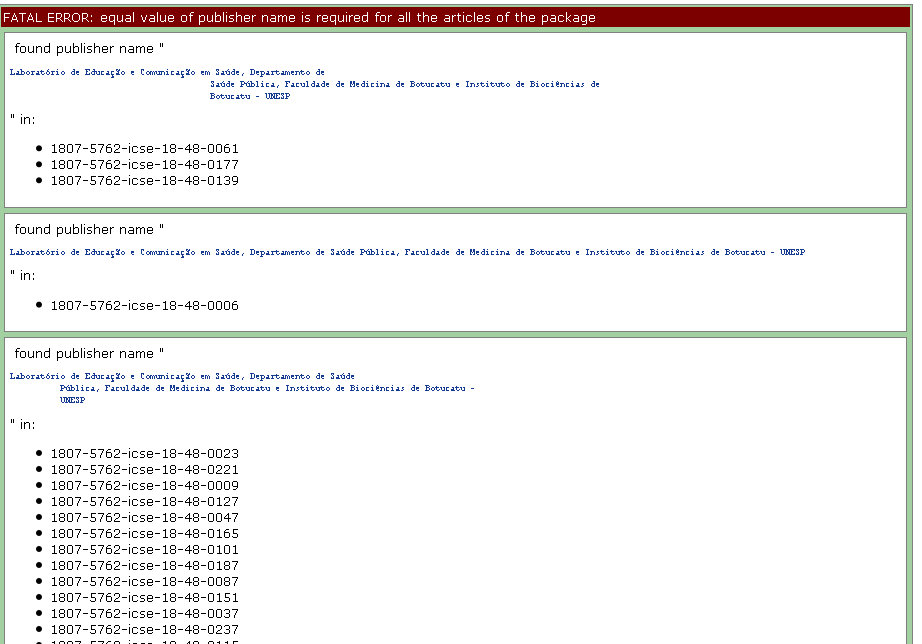
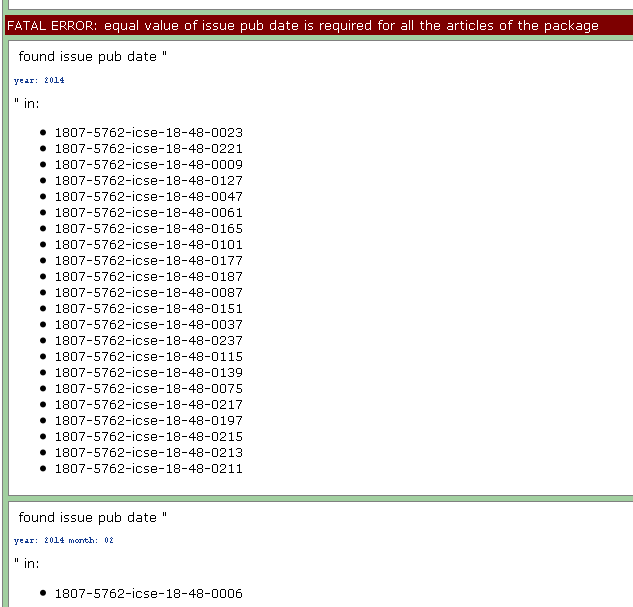
Fist of all, XPM validates some package’s data:
- Some data must have same value in all the XML files, such as:
- journal-title
- journal id NLM
- journal ISSN
- publisher name
- issue label
- issue pub date
- Some data must have unique value in all the XML files, such as:
- doi
- elocation-id, if applicable
- fpage and fpage/@seq
- order (used to generated article PID)
Example of fatal error because of different values for publisher-name.
Example of fatal error because of different values for pub-date.
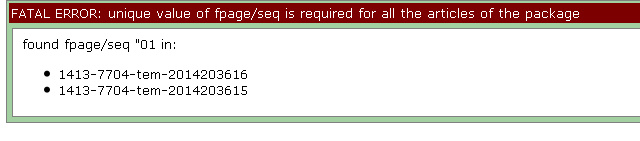
Example of fatal error because unique value is required
Detail report - documents’ validations
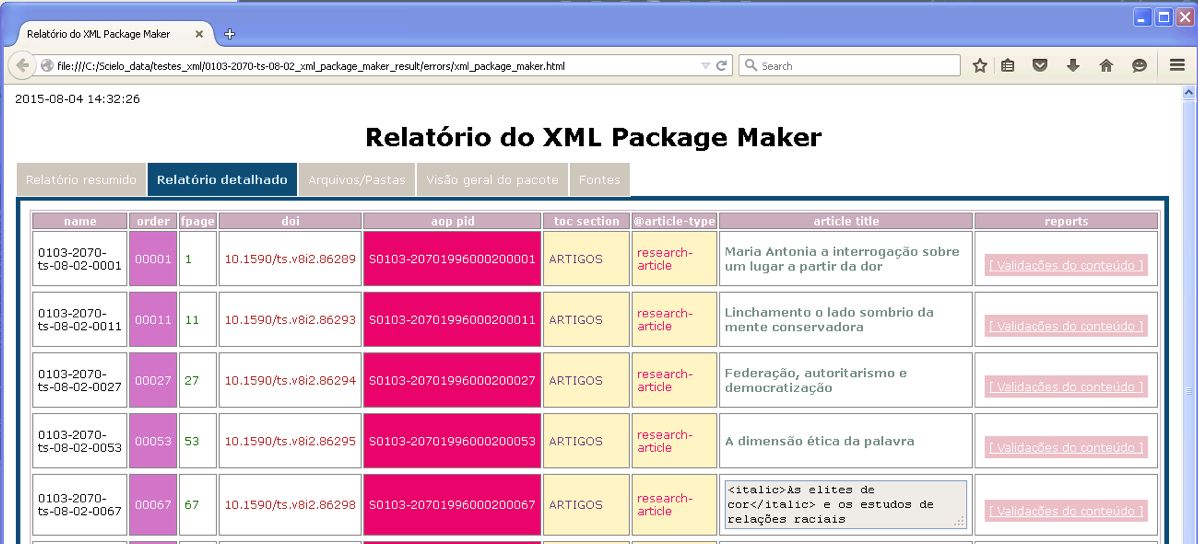
Presents the documents in a table.
The columns order, aop pid, toc section, @article-type are hightlighted because contains important data.
The column reports contains buttons to open/close the detail reports of each document.
Each row has the document’s data
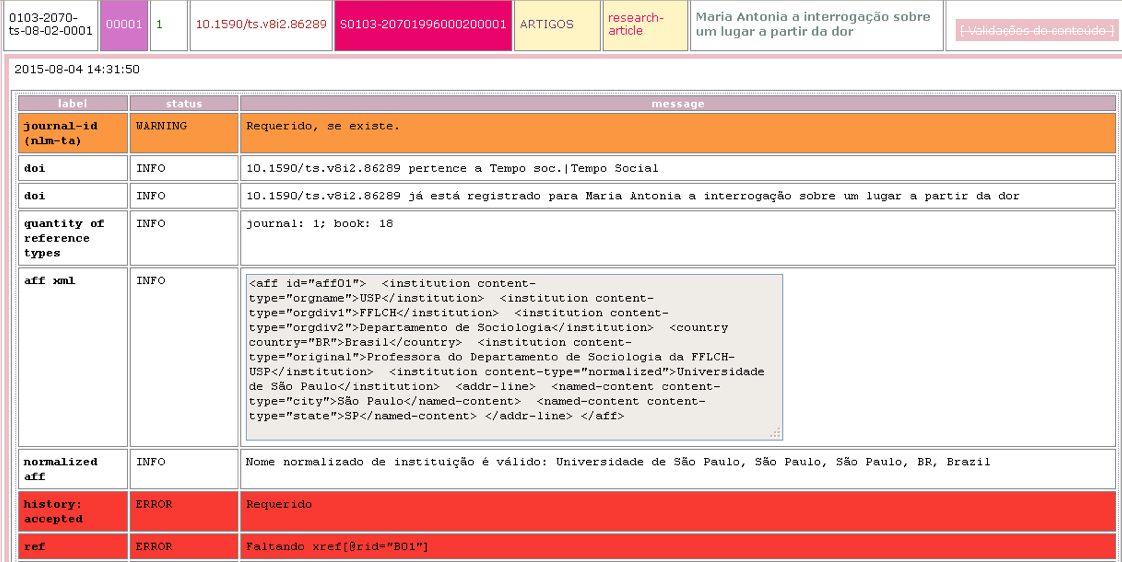
Detail report - Validations
Click on Data Quality Control to view the problems. The detail report is displayed below the row
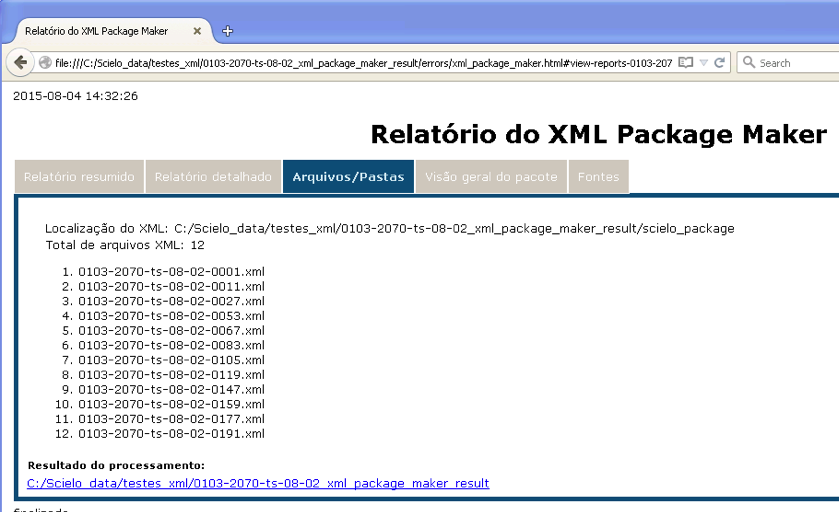
Folders/Files
Displays the files/folders which are inputs and outputs.
Overview report
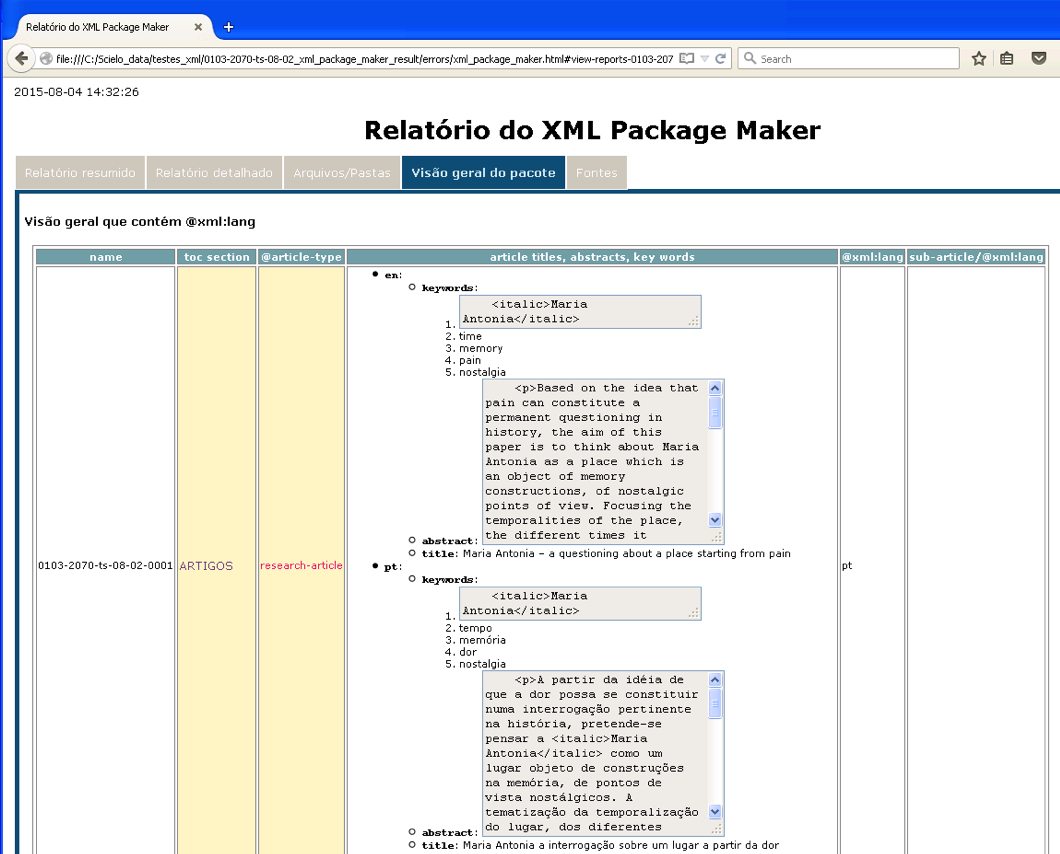
Overview report - languages
Displays the elements which contains @xml:lang.
Overview report - dates
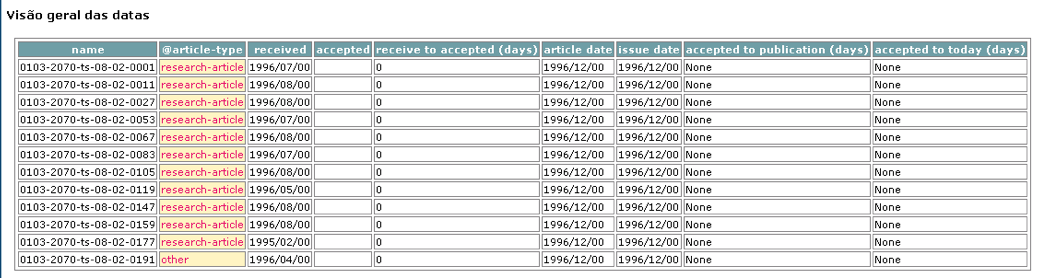
Displays the dates found in the document: publication and history. Displays the spent time between received and accepted, accepted and published, accepted and the present date.
Overview report - affiliations

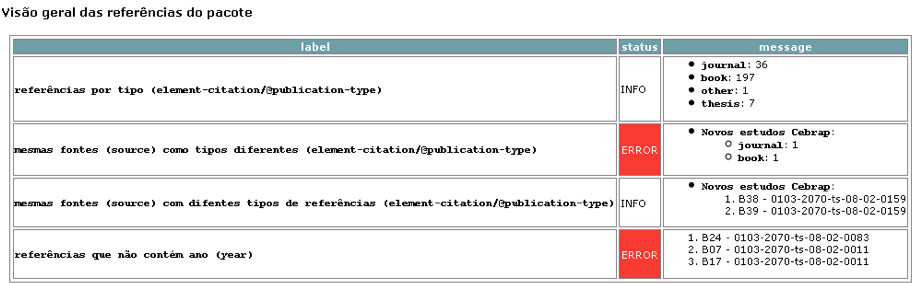
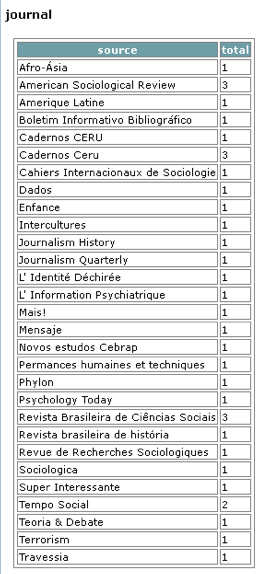
Overview report - references
Sources report



Instalação
Workflow of article in HTML / article or text DTD
How to generate SGML files (article and text DTD)
Files specifications
- one document (article or text) by file
- .html
- all the files related to the document must have the same name. For instance, a01.pdf.
- all the translations files must have the same name preceeded by <lang two letters>_. For instance, en_a01.pdf, en_a01.html.
Files location
Organize the files according to this files/folders structure.
- files for Markup
- /scielo/serial/<acron>/<issue_identification>/markup
- body
- /scielo/serial/<acron>/<issue_identification>/body
- images
- /scielo/serial/<acron>/<issue_identification>/img
- /scielo/serial/<acron>/<issue_identification>/pdf
For instance:
Input files for Markup
You must not have /scielo/bin/markup/markup_journals_list.csv. If you do, delete it.
Instead, you must have:
- ??_issue.mds: updated/created as any issue number’s data is updated/created
- issue.mds: updated/created as any issue number’s data is updated/created
- journal-standard.txt: updated/created as any journal’s data is updated/created
These files are generated by Title Manager or SciELO Manager.
Markup
Use Markup Program.
Como Produzir e Validar Artigos em XML?
Preparação de arquivos para o programa Markup
Introdução
Antes de iniciar o processo de marcação, é necessário seguir alguns passos para preparação do arquivo que será marcado. Veja abaixo os requisitos para a marcação do documento:
- Os arquivos devem estar em formato Word (.doc) ou (.docx).
- A estrutura de pastas deve seguir o padrão SciELO
- Os arquivos devem ser formatados de acordo com a Formatação SciELO.
Note
A nomeação dos arquivos que serão trabalhados não deve conter espaços, acentos ou caracteres especiais.
Arquivos de entrada para o Markup
Periódicos do SciELO.org
Somente se estiver trabalhando com um periódico do SciELO.org, use o menu para atualizar a lista de periódicos.
Selecione a coleção:
Outros periódicos
Não deve existir o arquivo /scielo/bin/markup/markup_journals_list.csv. Se existe, apague-o.
No lugar, deve existir:
- ??_issue.mds: atualizado/criado assim que qualquer dado de número é criado ou atualizado
- journal-standard.txt: atualizado/criado assim que qualquer dado de periódico é criado ou atualizado
Estes arquivos são gerados pelo programa Title Manager ou SciELO Manager.
Note
Title Manager gera estes arquivos em /scielo/bin/markup no computador onde é executado. Então, se o Markup será usado em outro computador, é necessário copiar estes arquivos para o computador onde ele será executado.
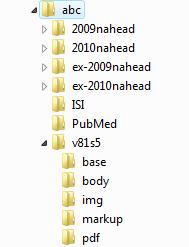
Estrutura de pastas
Antes de iniciar a marcação, é necessário garantir que a estrutura de pastas esteja como segue:
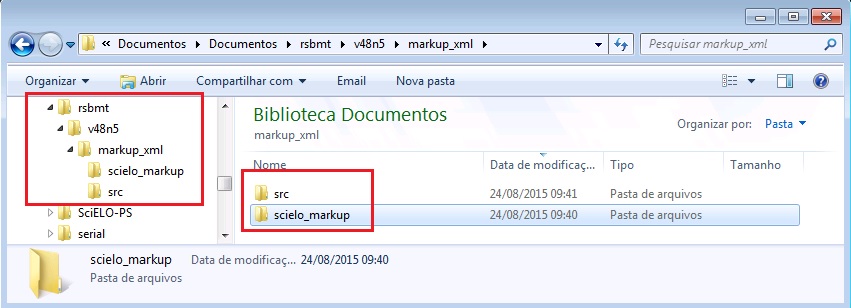
Veja que dentro da pasta markup_xml foram inseridas duas pastas, no mesmo nível:
- src: utilizada para inserir os arquivos PDF, mídia, ativos digitais (imagens, tabelas etc) e suplementos.
- scielo_markup: utilizada para inserir os arquivos .doc ou .docx.
Note
Se a recomendação de estrutura apresentada acima não for seguida, o processo de marcação não será iniciado.
Pasta src
Os arquivos referenciados no arquivo marcado, ou seja, aqueles identificados em href, devem estar na pasta src e devem ser nomeados da mesma forma no .doc (ou .docx). Nessa pasta também devem ser inseridos todos os arquivos que farão parte do pacote final, nas extensões desejadas.
Exemplo:
Em scielo_markup, há o arquivo a01.doc, que corresponde ao artigo 1.
Em src, devem ficar os seus arquivos relacionados, inclusive PDF.
A nomeação destes arquivos deve seguir a regra:
Figura
- Mesmo nome do arquivo .doc (sem a extensão) + f + identificação da figura + extensão do arquivo de imagem; ou
- Mesmo nome do arquivo .doc (sem a extensão) + fig + identificação da figura + extensão do arquivo de imagem.
Exemplo: a01f01.svg, a01f01.tiff, a01f01.jpg, a01f01.png, …
Tabela
- Mesmo nome do arquivo .doc (sem a extensão) + t + identificação da tabela + extensão do arquivo de imagem; ou
- Mesmo nome do arquivo .doc (sem a extensão) + tab + identificação da tabela + extensão do arquivo de imagem.
- Mesmo nome do arquivo .doc (sem a extensão) + t
Exemplo: a01t01.svg, a01t01.tiff, a01t01.jpg, a01t01.png, …
Tabela codificadas em XHTML
- Mesmo nome do arquivo .doc (sem a extensão) + t + identificação da tabela + extensão do arquivo html;
- Mesmo nome do arquivo .doc (sem a extensão) + tab + identificação da tabela + extensão do arquivo html;
Exemplo: a01t01.html, a01tab01.html, …
Note
No caso de SciELO Brasil, a codificação da tabela é obrigatória.
Equation
- Mesmo nome do arquivo .doc (sem a extensão) + eq + identificação da equação + extensão do arquivo de imagem; ou
- Mesmo nome do arquivo .doc (sem a extensão) + frm + identificação da equação + extensão do arquivo de imagem; ou
- Mesmo nome do arquivo .doc (sem a extensão) + form + identificação da equação + extensão do arquivo de imagem.
Exemplo: a01eq1.svg, a01eq1.tiff, a01eq1.jpg, a01eq1.png, a01eq1.gif, …
Note
No caso de SciELO Brasil, a codificação de equações é obrigatória.
No arquivo marcado, o Markup rotula automaticamente os objetos gráficos, identificando-os da seguinte forma [graphic href=”?a01”] {elemento gráfico fica aqui} [/graphic]. Este valor não deve ser alterado, pois desta forma, o Markup é capaz de associar esta referência com os arquivos localizados na pasta src.
Note
As imagens dos artigos devem estar disponíveis no arquivo .doc, preferencialmente em formato .jpeg e .png.

O Markup também renomeia as imagens para o padrão já estabelecido.

No entanto, quando os arquivos correspondentes na pasta src não existem, o Markup exporta a imagem inserida no próprio arquivo .doc, mas há perda da qualidade da imagem. Recomenda-se, então, que as imagens de boa qualidade estejam na pasta src antes da geração do XML.
O relatório indica de onde as imagens foram obtidas, se da pasta src ou extraídas do arquivo marcado .doc.

O Markup também ajusta automaticamente o nome dos arquivos no XML.

Formatação do arquivo
Para otimizar o processo de marcação dos elementos básicos do arquivo, é necessário seguir o padrão de Formatação SciELO disponível abaixo:
Instruções para formatação de dados básicos do artigo:
- Linha 1: inserir número de DOI, caso não exista começar pela seção do sumário;
- Linha 2: inserir a seção do sumário, caso não exista deixar linha em branco;
- Linha 3: título do artigo;
- Linhas seguintes: Títulos traduzidos do arquivo;
- Para separar autores de título, pular uma linha;
- Cada autor deve estar em uma linha separada e ter o label de sua afiliação sbrescrito para que o programa consiga fazer a identificação automática;
- Pular 1 linha para separar autores de afiliações;
- Cada afiliação deve estar em uma linha separada e ter o label de sua afiliação sbrescrito para que o programa consiga fazer a identificação automática;
- Pular 1 linha para separar afiliação de resumos;
- O título do resumo deve estar em negrito em um parágrafo. O resumo deve começar no parágrafo seguinte;
- No caso de resumos estruturados, título da seção em negrito e cada seção em um parágrafo;
- O título do grupo de palavras-chave: deve estar em negrito. As palavras-chave devem ser separadas por vírgula ou ponto e vírgula;
- Seções: negrito, 16 pt;
- Subseções: negrito, 14 pt;
- Subseção de subseção: negrito, 13 pt;
- Texto: formatação livre;
- Para tabelas, label e legenda devem estar na linha antes do corpo da tabela; e as notas de tabela após o corpo da tabela;
- Separador de label e legenda: dois-pontos e espaço ou espaço + hífen + espaço ou ponto + espaço;
- Para tabelas codificadas, o cabeçalho deve estar em negrito;
- A citação do tipo autor/data no corpo do texto deve ser: sobrenome do autor, ano;
- Para citação no sistema numérico no corpo do texto: número entre parênteses e sobrescrito;
- Notas de rodapé no corpo do texto: se identificadas com número devem estar em sobrescrito, mas não entre parênteses;
- Citação direta longa (quote): recuo de 4 cm da margem esquerda.
Exemplo:
Dados iniciais:

Autores e afiliação:

Resumo simples + palavras-chave:

Resumo estruturado + palavras-chave:

Figuras:

Tabelas:
Citação do tipo autor/data:

Citação numérica:

Citação direta longa:

Como usar o Markup
Introdução
Este manual tem como objetivo apresentar o uso do programa de marcação Markup
Sugestão de Atribuição de “ID”
O atributo “ID” é usado para identificar alguns elementos, tornando possível estabelecer referências cruzadas entre sua chamada no decorrer do texto e o elemento em si, como figuras, tabelas, afiliações etc. Para composição do “ID” combine o prefixo do tipo do elemento e um número inteiro, como segue:
| Elemento XML | Descrição | Prefixo | Exemplo |
|---|---|---|---|
| aff | Afiliação | aff | aff1, aff2, … |
| app | Apêndice | app | app1, app2, … |
| author-notes/fn | fn-group/fn | Notas de rodapé do artigo | fn | fn1, fn2, … |
| boxed-text | Caixa de texto | bx | bx1, bx2, … |
| corresp | Correspondência | c | c1, c2, … |
| def-list | Lista de Definições | d | d1, d2, … |
| disp-formula | Equações | e | e1, e2, … |
| fig | Figuras | f | f1, f2, … |
| glossary | Glossário | gl | gl1, gl2, … |
| media | Media | m | m1, m2, … |
| ref | Referência bibliográfica | B | B1, B2, … |
| sec | Seções | sec | sec1, sec2, … |
| sub-article | sub-artigo | S | S1, S2, … |
| supplementary-material | Suplemento | suppl | suppl1, suppl2, … |
| table-wrap-foot/fn | Notas de rodapé de tabela | TFN | TFN1, TFN2, … |
| table-wrap | Tabela | t | t1, t2, … |
Dados Básicos
Estando o arquivo formatado de acordo com o manual Preparação de Arquivos para o Programa Markup e aberto no programa Markup, selecione a tag [doc]:
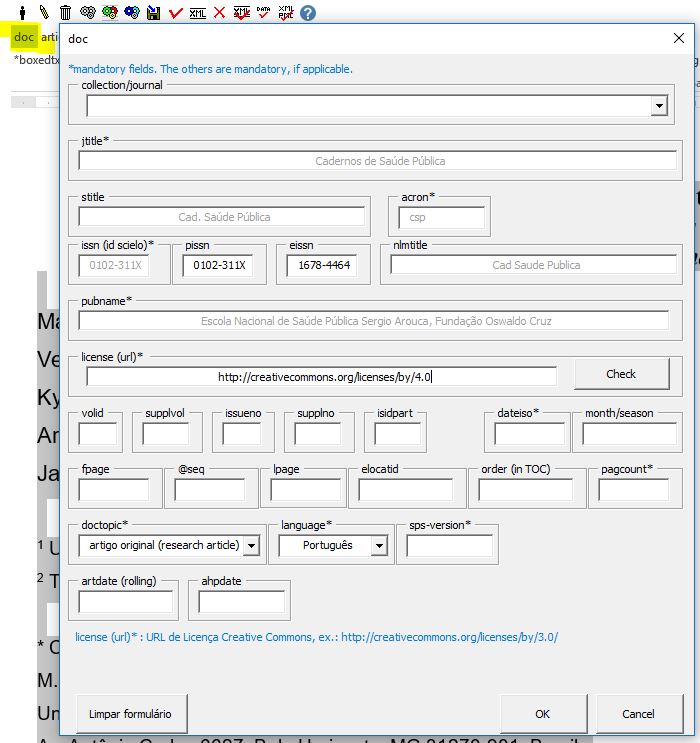
Ao clicar em [doc] o programa abrirá um formulário para ser completado com os dados básicos do artigo:
Ao selecionar o periódico no campo “collection/journal” o programa preencherá alguns dados automaticamente, tais como: ISSNs, título abreviado, acrônimo, entre outros. Os demais dados serão preenchidos manualmente, de acordo com as orientações abaixo:
| Campo | Descrição |
|---|---|
| license | Se não for inserido automaticamente, preencher com a URL da licença Creative Commons adotada pelo periódico. Consultar licenças em: http://docs.scielo.org/projects/scielo-publishing-schema/pt_BR/latest/tagset/elemento-license.html |
| volid | Inserir volume, se houver. Para ahead of print, não incluir volume |
| supplvol | Caso seja um suplemento de volume incluir sua parte ou número correspondente. Por exemplo, para o vol.12 supl.A, preencha esse campo com “A” |
| issueno | Insira o número do fascículo. Caso seja um artigo para publicação em ahead of print, insira “ahead” neste campo |
| supplno | Caso seja um suplemento de fascículo, incluir sua parte ou número correspondente. Por exemplo, para o n.37, supl.A, preencha esse campo com “A” |
| isidpart | Usar em casos de press release, incluindo a sigla “pr” |
| dateiso | Data de publicação formada por ano, mês e dia (YYYYMMDD). Preencher sempre com o último mês da periodicidade. Por exemplo, se o periódico é bimestral preencher “20140600”. Use “00” para mês e dia nos casos em que não são identificados. Por exemplo: “20140000” |
| month/season | Entre o mês ou mês inicial + barra + mês final, em inglês (três letras) e ponto, exceto para May, June e July. Por exemplo: May/June, July/Aug. |
| fpage | Número da primeira página do documento. Para artigo em ahead of print, incluir “00” |
| @seq | Para artigos que iniciam na mesma página de um artigo anterior, incluir a sequência com letra. Por exemplo: “23b” |
| lpage | Inserir o número da última página do documento |
| elocatid | Incluir paginação eletrônica. Neste caso não preencher fpage e lpage |
| order (in TOC) | Incluir a ordem do artigo no sumário do fascículo. Deve ter, no mínimo, dois dígitos. Por exemplo, se o artigo for o primeiro do sumário, preencha este campo com “01” e assim por diante |
| doctopic* | Informar o tipo de documento a ser marcado. Por exemplo: artigo original, resenha, carta, comentário etc. No caso de ahead of print, incluir sempre o tipo “artigo original”, exceto para errata |
| language* | Informe o idioma principal do texto a ser marcado |
| sps-version* | Identifica a versão do SciELO Publishing Schema (http://docs.scielo.org/projects/scielo-publishing-schema/pt_BR/latest/) usada no processo de marcação (a versão atual é 1.5) |
| artdate (rolling) | Obrigatório completar com a data formada por ano, mês e dia (YYYYMMDD) quando for um artigo de um periódico que usa o modelo de publicação contínua, onde os artigos são publicados à medida em que ficam prontos |
| ahpdate | Indicar a data de publicação de um artigo publicado em ahead of print |
Note
Os campos que apresentam um asterisco ao lado são obrigatórios.
Front
Tendo preenchido todos os campos, ao clicar em “Ok” será aberta uma janela perguntando se o arquivo está na formatação adequada para efetuar a marcação automática:

Ao clicar em “Sim”, o programa efetuará a marcação automática dos elementos básicos do documento.

Note
Caso o arquivo não esteja na formatação recomendada em Preparação de Arquivos para o Programa Markup, o programa não identificará corretamente os elementos.
Após a marcação automática é necessário completar a marcação dos elementos básicos.
Doctitle
Confira o idioma inserido em [doctitle] para títulos traduzidos e se necessário, corrija. Para corrigir, selecione a tag cujo atributo precisa ser corrigido e clique no botão “Markup: Editar atributos” (lápis) para editá-lo:

Faça o mesmo para os demais títulos traduzidos.
Autores
Alguns autores apresentam mais que um label ao lado do nome, porém o programa não faz a marcação automática de mais que um label. Para isso, selecione o label do autor e o identifique com o elemento [xref].

Por se tratar de referência cruzada (xref) de afiliação, o tipo de xref (ref-type) selecionado foi o “affiliation” e o rid (relacionado ao “ID”) “aff3” para relacionar o label 3 à afiliação correspondente.
O programa Markup não faz a marcação automática de função de autor como, por exemplo, o cargo exercido. Para isso é necessário selecionar a informação que consta ao lado do nome do autor, ir para o nível inferior do elemento [author] e identificar esse dado com a tag [role]. Veja:


Note
O programa não identifica automaticamente símbolos ou letras como label, que devem ser marcados manualmente, observando o tipo de referência cruzada a ser incluída.
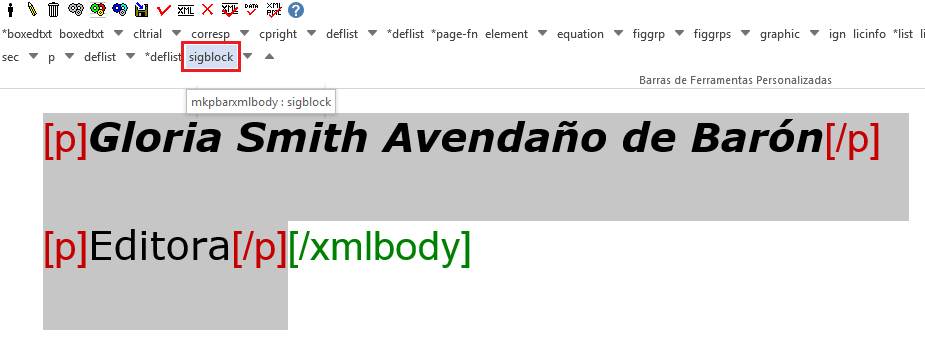
Sig-block
Geralmente arquivos Editoriais, Apresentações etc possuem ao final do texto a assinatura do autor ou editor. Para identificar a assinatura do autor, seja em imagem ou texto, é necessário selecionar a assinatura e identificar com a tag [sigblock] (no nível inferior da tag [xmlbody]):
Após isso, selecione apenas a assinatura e faça a identificação com a tag [sig]:
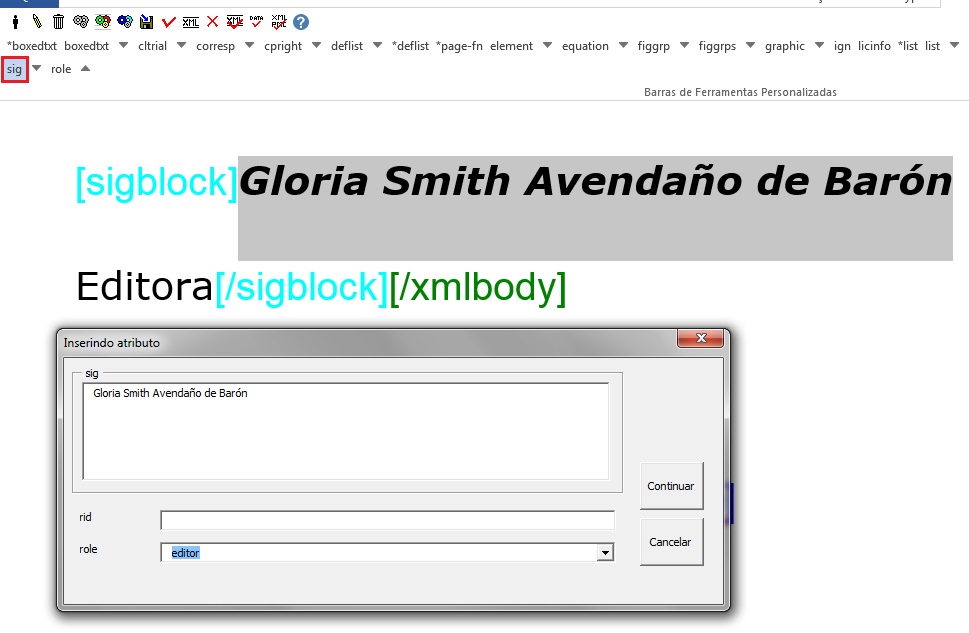
Note
Algumas assinaturas apresentam ao lado o cargo ou função do autor. Para a identificação de [sig], não considerar a função.
Faça então a idenficação da assinatura, identificando [fname] e [surname]. Abaixo o resultado da identificação de assinatura do autor/editor:

On Behalf
O elemento [on-behalf] é utilizado quando um autor exerce papel de representante de um grupo ou organização. Para identificar esse dado, verifique se a informação do representante do grupo está na mesma linha do autor. Exemplo:
Fernando Augusto Proietti 2 Interdisciplinary HTLV Research Group
O programa identificará o autor “Fernando Augusto Proietti” da seguinte forma:

Agora selecione o nome do grupo ou organização e identifique com a tag: [onbehalf]:

Contrib-ID
Autores que apresentam registro no ORCID ou no Lattes devem inserir o link de registro ao lado do nome, após o label do autor:

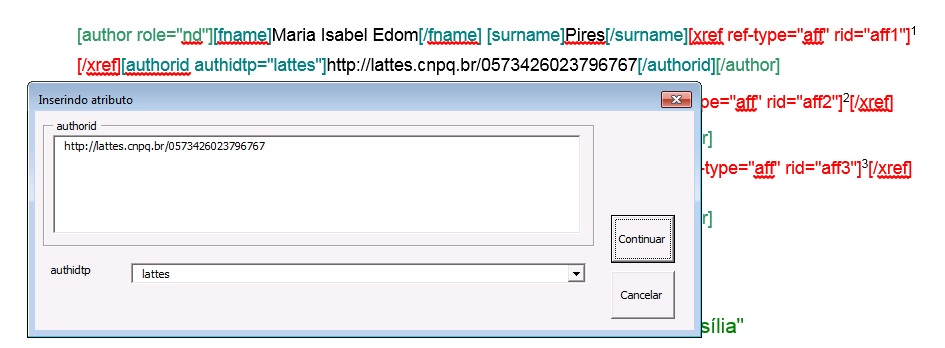
Ao fazer a marcação de [doc] o programa identificará automaticamente todos os dados iniciais do documento, inclusive marcará em [author] o link de registro do autor. Ainda que o programa inclua o link na tag [author], será necessário completar a marcação desse dado.
Para isso, entre no nível de [author], selecione o link do autor e clique em [author-id]. Na janela aberta pelo programa, selecione o tipo de registro do autor: se lattes ou ORCID e clique em “Continuar”.
Afiliações
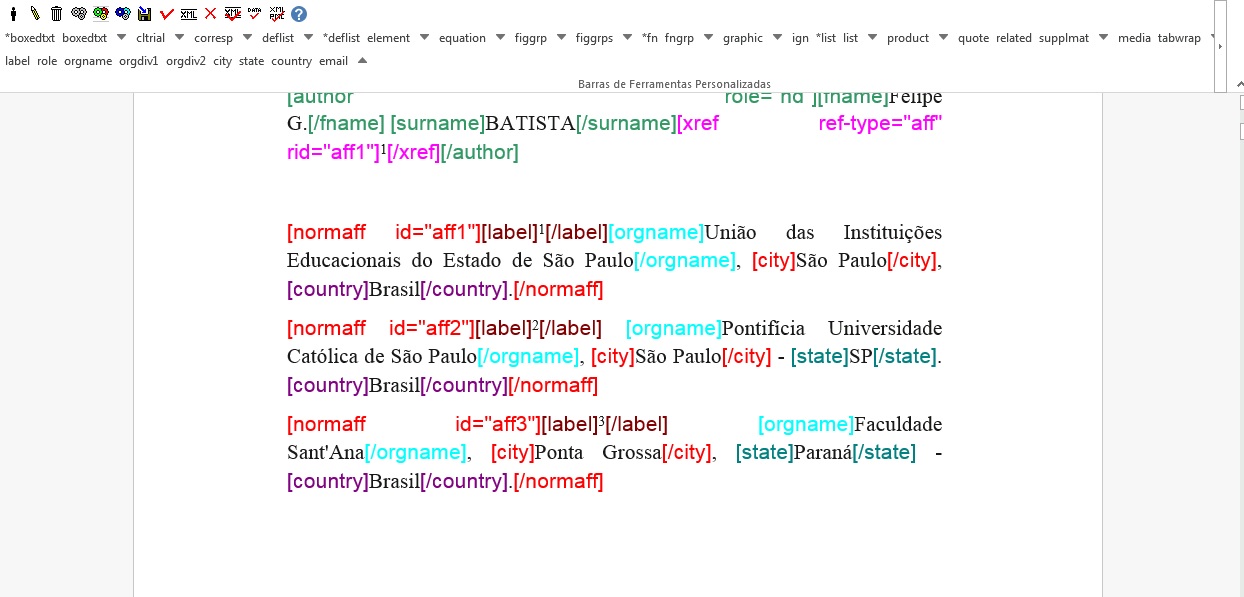
O programa Markup faz a identificação apenas de grupo de dados de cada afiliação com o elemento [normaff], ou seja, o detalhamento das afiliações não é feito automaticamente. Complete a marcação de afiliações identificando: instituição maior [orgname], divisão 1 [orgdiv1], divisão 2 [orgdiv2], cidade [city], estado [state] (esses 4 últimos, se presentes) e o país [country].
Para fazer a identificação dos elementos acima vá para o nível inferior do elemento [normaff] e faça o detalhamento de cada afiliação.
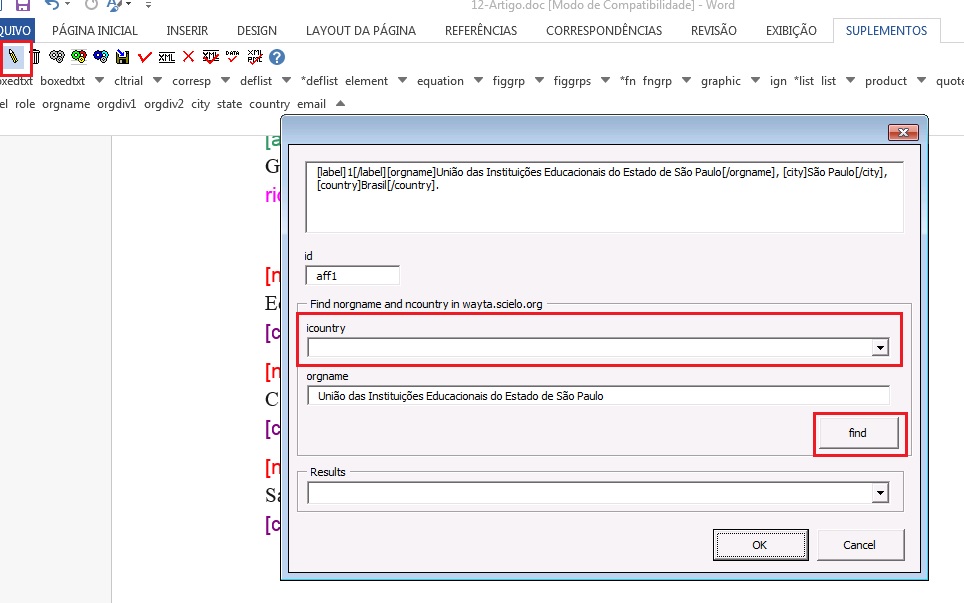
Após o detalhamento de afiliações, será necessário verificar se a instituição marcada e país correspondente possuem forma normalizada pelo SciELO. Para isso, selecione o elemento [normaff] e clique no botão “Markup: Editar atributos” (lápis) para editar os atributos. O programa abrirá uma janela para normalização dos elementos indicados nos campos em branco.
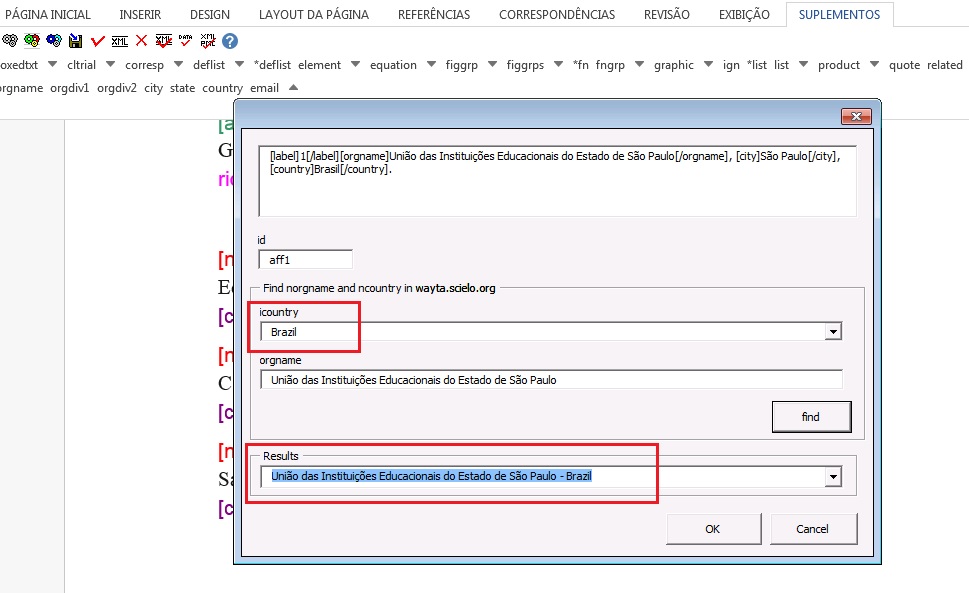
No campo “icountry” selecione o país da instituição maior (orgname), em seguida clique em “find” para encontrar a instituição normalizada. Ao fazer esse procedimento, o programa Markup consultará nossa base de dados de instituições normalizadas e verificará se a instituição selecionada consta na lista.

Note
Faça a busca pelo idioma de origem da instituição, exceto para línguas não latinas, quando a consulta deverá ser feita em inglês. Caso a instituição não exista na lista do Markup, selecione o elemento “No match found” e clique em “OK”.
Resumos
Os resumos devem ser identificados manualmente. Para marcação de resumos simples (sem seções) e para os resumos estruturados (com seções) utilizar o elemento [xmlabstr]. Na marcação, selecione o título do resumo e o texto e em seguida marque com o botão [xmlabstr].
Resumo sem Seção:
Selecionando:

Quando clicar em [xmlabstr] o programa abrirá uma janela onde deve-se selecionar o idioma do resumo marcado:
Marcação:
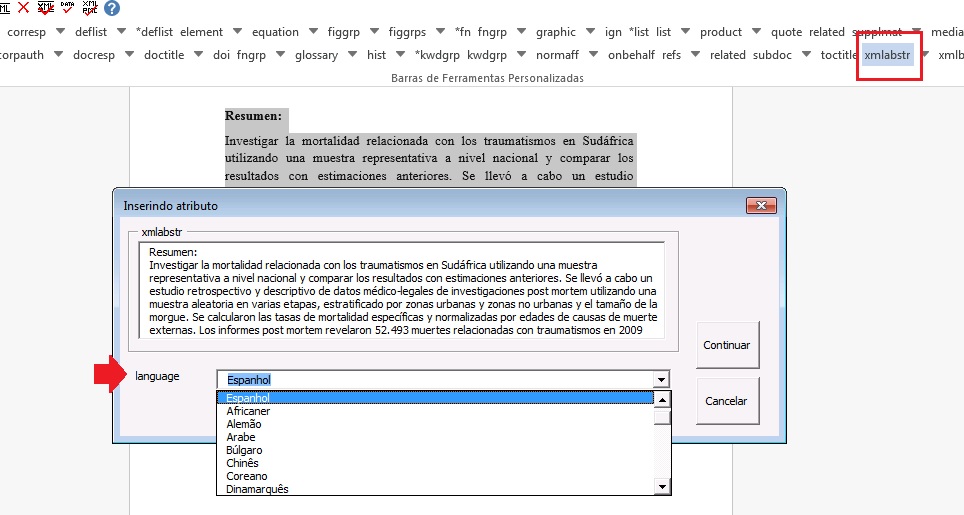
Resultado:

Já em resumos estruturados, o programa também marcará cada seção do resumo e seus respectivos parágrafos.
Resumo com Seção:
Siga os mesmos passos descritos para resumo sem seção:
Selecionando:

Marcação:
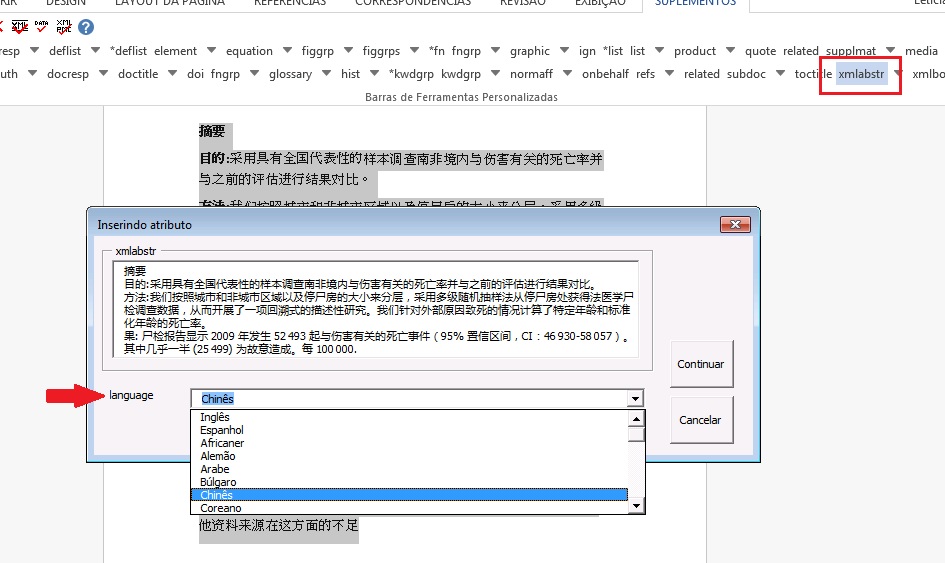
Resultado:

Keywords¶
O programa Markup apresenta dois botões para identificação de palavras-chave, [*kwdgrp] e [kwdgrp]. O botão [*kwdgrp], com asterisco, é utilizada para identificação automática de cada palavra-chave e do título. Para isso, selecione toda a informação – inclusive o título – e identifique os dados com o elemento [*kwdgrp].
Marcação Automática:
Selecionando:
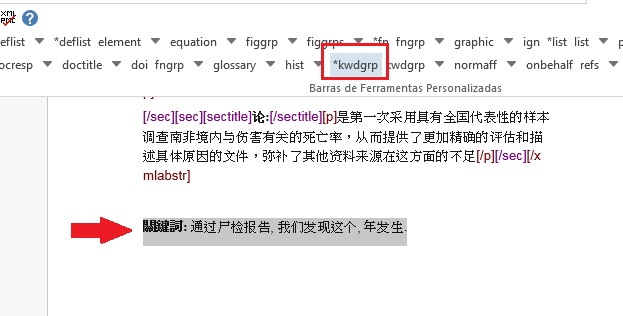
Ao clicar em [*kwdgrp] o programa abrirá uma janela para seleção do idioma das palavras-chave marcadas:
Marcação:
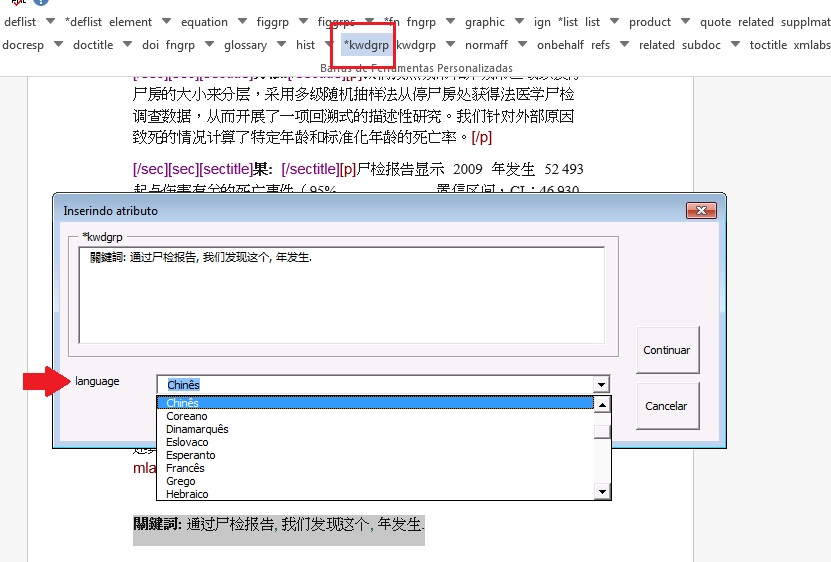
Resultado:

Marcação Manual:
Caso a marcação automática não ocorra conforme o esperado, pode-se marcar o grupo de palavras-chave manualmente. Selecione o grupo de palavras-chave e marque com o elemento [kwdgrp].
Marcação:
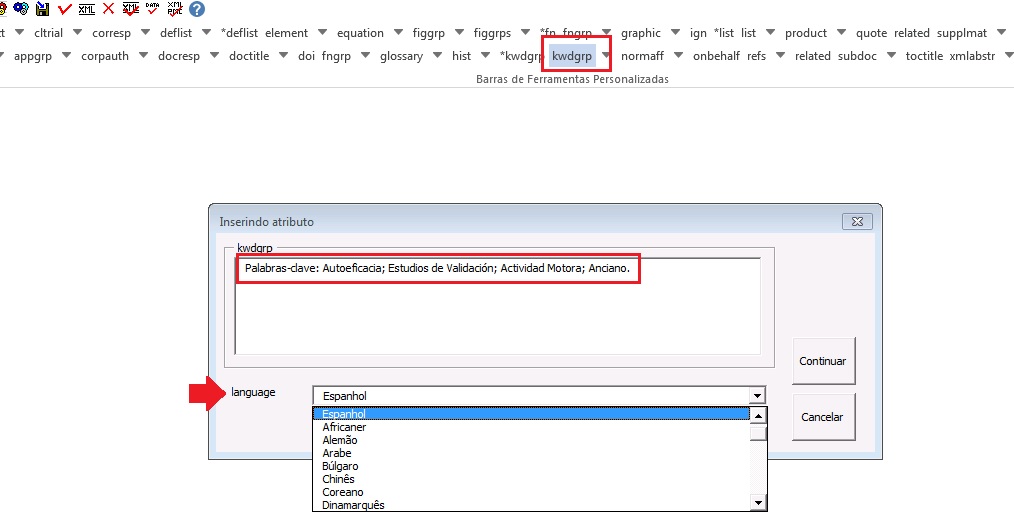
Em seguida, faça a identificação de item por item. Para tanto, selecione o título das palavras-chave e identifique com o elemento [sectitle]:

Na sequência, selecione palavra por palavra e marque com o elemento [kwd]:
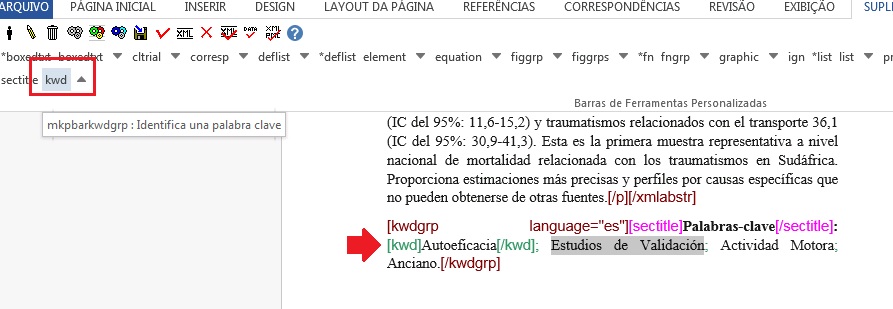
Note
Quando estiver fazendo a marcação manual das palavras-chave, note que o separador não deverá ser inserido dentro da tag [kwd] .
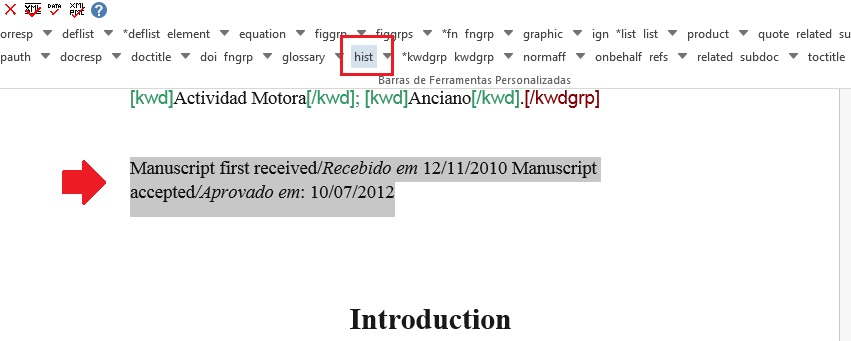
History
O elemento [hist] é utilizado para marcar o histórico do documento. Selecione todo o dado de histórico e marque com o elemento [hist]:
Selecione, então, a data de recebimento e marque com o elemento [received]. Confira a data ISO indicada no campo “dateiso” e corrija, se necessário. A estrutura da data ISO esperada nesse campo é ANO MÊS DIA. Veja:
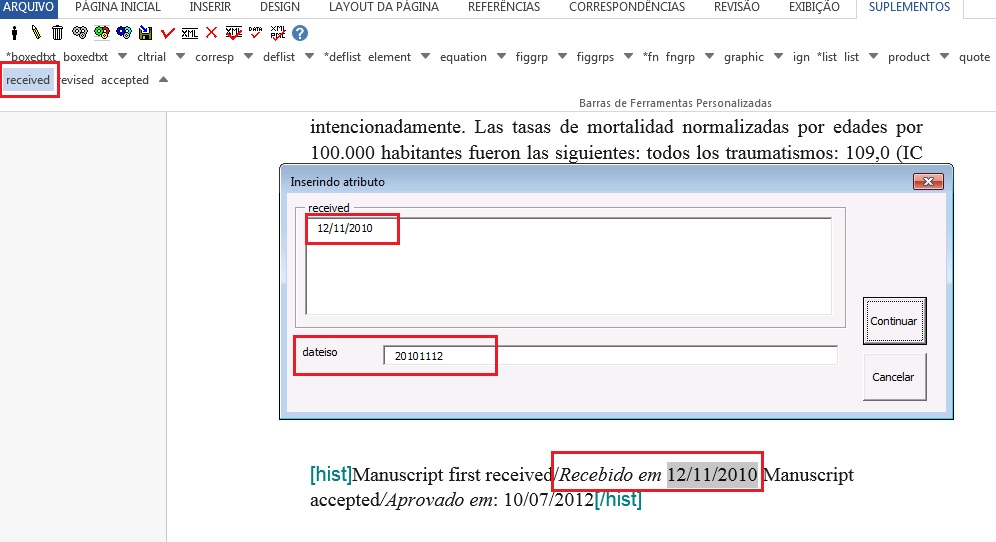
Caso haja a data de revisão, selecione-a e marque com o elemento [revised]. Faça o mesmo para a data de aceite, selecionando o elemento [accepted]. Confira a data ISO indicada no campo “dateiso” e corrija, se necessário.
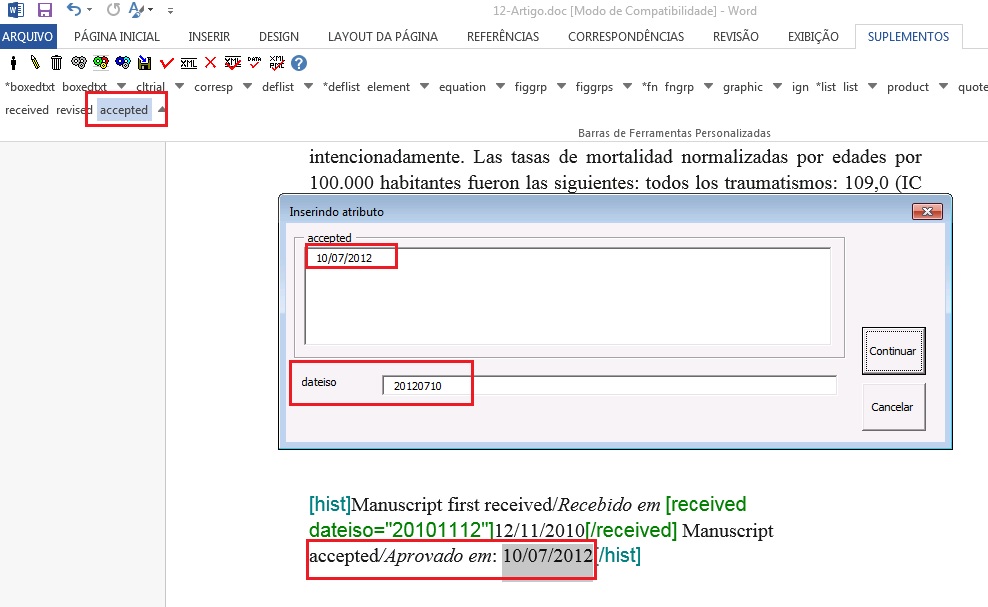
Correspondência
Com o elemento [corresp] é possível marcar os dados de correspondência do autor. Esse elemento possui um subnível para identificação do e-mail do autor. Selecione toda a informação de correspondência e marque com o elemento [corresp]. Será apresentada uma janela para marcação do ID de correspondência que, nesse caso, deve ser “c” + o número de ordem da correspondência.
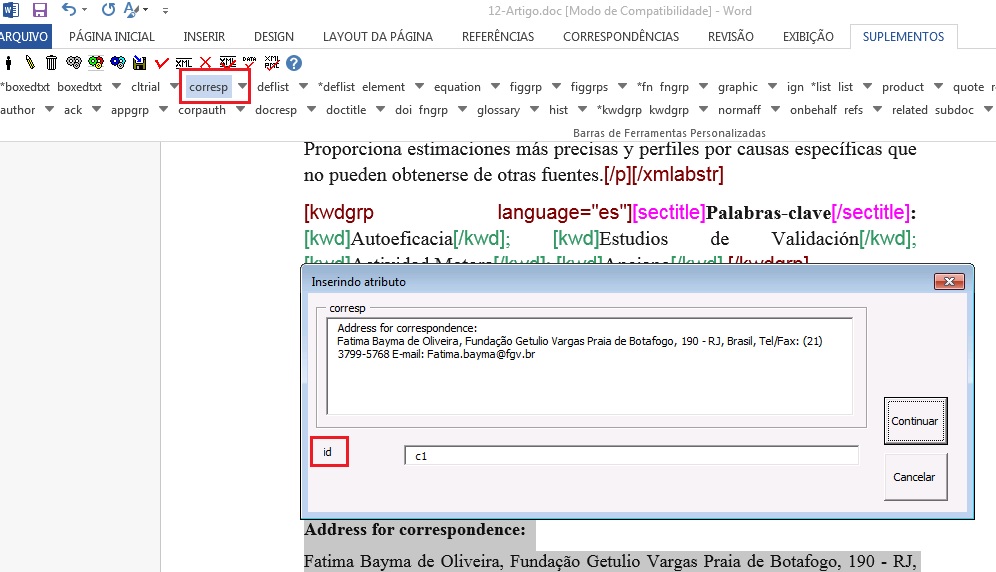
Selecione o e-mail do autor correspondente e marque com o elemento [email].

Ensaio Clínico
Arquivos que apresentam informação de ensaio clínico com número de registro, devem ser marcados com o elemento [cltrial]:
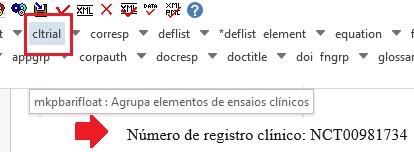
Na janela aberta pelo programa, preencha o campo de URL da base de dados onde o Ensaio foi indexado no campo “cturl” e preencha o campo “ctdbid” selecionando a base correspondente. Para encontrar a URL do ensaio clínico faça uma busca na internet pelo número de registro.
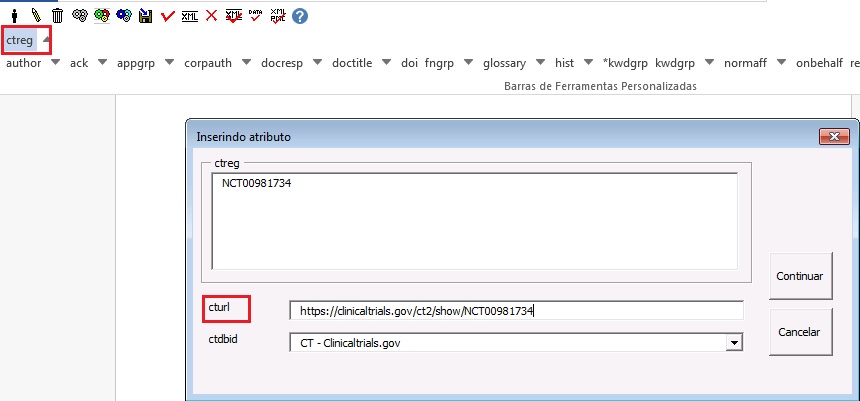
Resultado:

Note
Comumente a informação de Ensaio clínico está posicionada abaixo dos resumos ou palavras-chave.
Referências
As referências bibliográficas são marcadas elemento a elemento e seu formato original é mantido para apresentação no site do SciELO.
O programa marcará todas as referências selecionadas com o elemento [ref] do tipo [book]. A alteração do tipo de referência será manual ou automática, dependendo do tipo de elemento marcado, conforme será observado mais adiante.
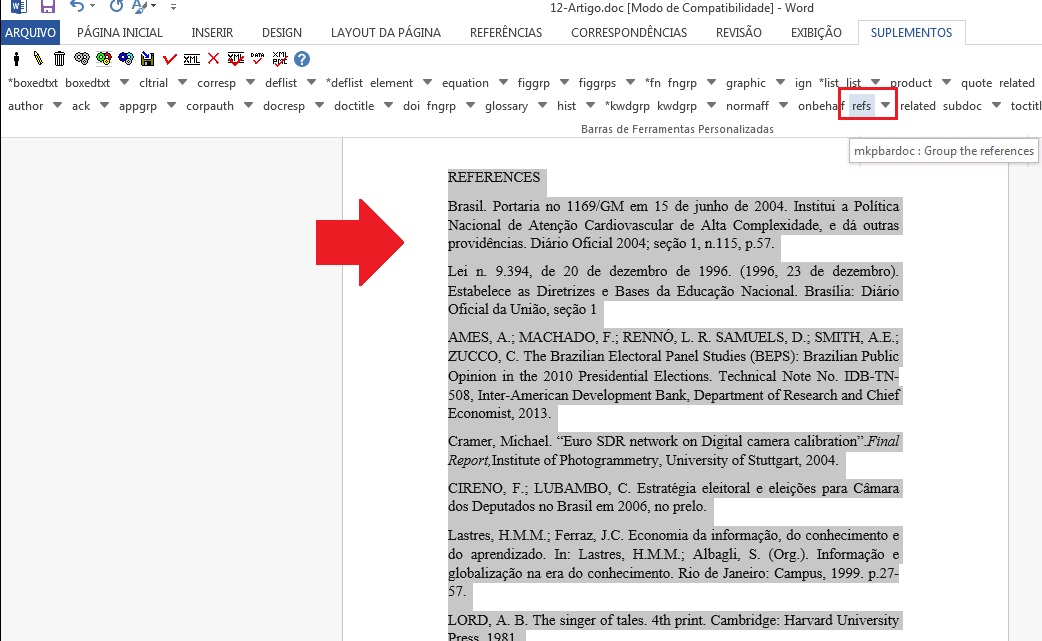
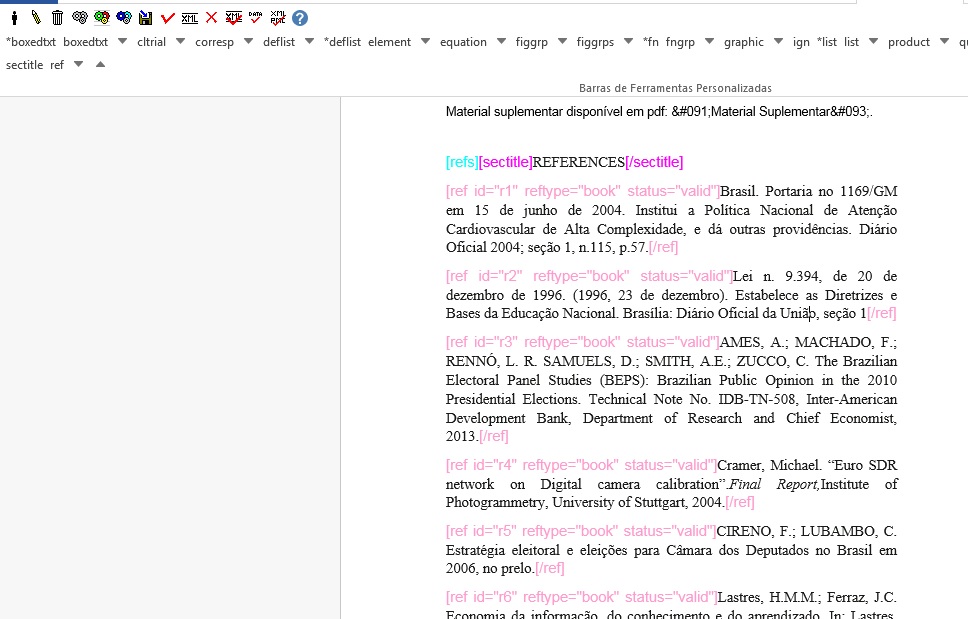
Tipos de Referências
A partir da marcação feita, alguns tipos de referência serão alterados automaticamente sem intervenção manual (ex.: tese, conferência, relatório, patente e artigo de periódico); já para os demais casos, será necessária a alteração manual. Para alterar o tipo de referência clique no elemento [ref], em seguida, no lápis “Editar Atributos” e em “reftype” para selecionar o tipo correto.
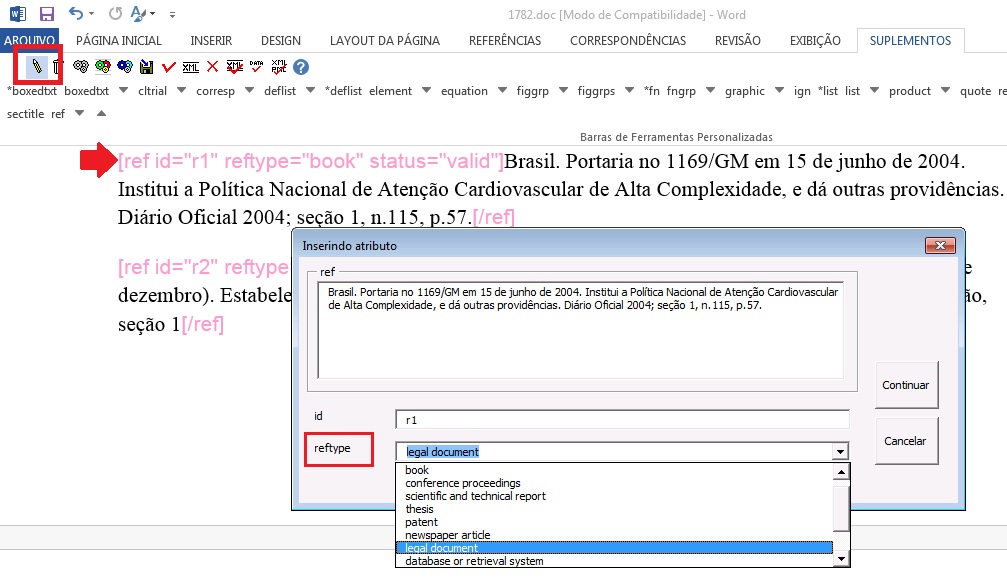

Recomenda-se a edição de “reftype” somente após marcar todos os elementos da [ref], pois dependendo dos elementos marcados o “reftype” pode ser alterado automaticamente pelo Markup.
Note
Uma referência deve ter sua tipologia sempre baseada no seu conteúdo e nunca no seu suporte. Por exemplo, uma lei representa um documento legal, portanto o tipo de referência é “legal-doc”, mesmo que esteja publicado em um jornal ou site. Uma referência de artigo de um periódico científico, mesmo que publicado em um site possui o tipo “journal”. É importante entender estes aspectos nas referências para poder interpretar sua tipologia e seus elementos. Nem toda referência que possui um link é uma “webpage”, nem toda a referência que possui um volume é um “journal”, livros também podem ter volumes.
Abaixo seguem os tipos de referência suportados por SciELO e a marcação de cada [ref].
Thesis
Utilizada para referenciar monografias, dissertações ou teses para obtenção de um grau acadêmico, tais como livre-docência, doutorado, mestrado, bacharelado, licenciatura etc. A seleção do elemento [thesgrp] determinará a alteração do tipo [book] para [thesis]. Ex:
PINHEIRO, Fernanda Domingos. Em defesa da liberdade: libertos e livres de cor nos tribunais do Antigo Regime português (Mariana e Lisboa, 1720-1819). Tese de doutorado, Departamento de História, Instituto de Filosofia e Ciências Humanas, Universidade Estadual de Campinas, 2013

Confproc
Utilizada para referenciar documentos relacionados à eventos: atas, anais, convenções, conferências entre outros. Ao marcar o elemento [confgrp] o programa alterará o tipo de referência para [confproc]. Ex.:
FABRE, C. Interpretation of nominal compounds: combining domain-independent and domain-specific information. In: INTERNATIONAL CONFERENCE ON COMPUTATIONAL LINGUISTICS (COLING), 16, 1996, Stroudsburg. Proceedings… Stroudsburg: Association of Computational Linguistics, 1996. v.1, p.364-369.

Report
Utilizada para referenciar relatórios técnicos, normalmente de autoria institucional. Ao marcar o elemento [reportid] o programa alterará o tipo de referência para [report]. Ex.:
AMES, A.; MACHADO, F.; RENNÓ, L. R. SAMUELS, D.; SMITH, A.E.; ZUCCO, C. The Brazilian Electoral Panel Studies (BEPS): Brazilian Public Opinion in the 2010 Presidential Elections. Technical Note No. IDB-TN-508, Inter-American Development Bank, Department of Research and Chief Economist, 2013.

Note
Nos casos em que não houver número de relatório, a alteração do tipo de referência deverá ser feita manualmente.
Patent
Utilizada para referenciar patentes; a patente representa um título de propriedade que confere ao seu titular o direito de impedir terceiros explorarem sua criação.. Ex.:
SCHILLING, C.; DOS SANTOS, J. Method and Device for Linking at Least Two Adjoinig Work Pieces by Friction Welding, U.S. Patent WO/2001/036144, 2005.

Book
Utilizada para referenciar livros ou parte deles (capítulos, tomos, séries e etc), manuais, guias, catálogos, enciclopédias, dicionários entre outros. Ex.:
LORD, A. B. The singer of tales. 4th. Cambridge: Harvard University Press, 1981.

Book no prelo
Livros finalizados, mas ainda não publicados apresentam a informação “no prelo”, “forthcomming” ou ““in press”” normalmente ao final da referência. Nesse caso, a marcação será feita conforme indicado abaixo:
CIRENO, F.; LUBAMBO, C. Estratégia eleitoral e eleições para Câmara dos Deputados no Brasil em 2006, no prelo.

Book Chapter
Divisão de um livro (título do capítulo e seus respectivos autores, se houver, seguido do título do livro e seus autores) numerado ou não
Lastres, H.M.M.; Ferraz, J.C. Economia da informação, do conhecimento e do aprendizado. In: Lastres, H.M.M.; Albagli, S. (Org.). Informação e globalização na era do conhecimento. Rio de Janeiro: Campus, 1999. p.27-57.

journal
Utilizada para referenciar publicações seriadas científicas, como periódicos, boletins e jornais, editadas em unidades sucessivas, com designações numéricas e/ou cronológicas e destinada a ser continuada indefinidamente. Ao marcar [arttile-title] o programa alterará o tipo de referência para [journal]. Ex.:
Cardinalli, I. (2011). A saúde e a doença mental segundo a fenomenologia existencial. Revista da Associação Brasileira de Daseinsanalyse, São Paulo, 16, 98-114.

Nas referências abaixo, seu tipo deverá ser alterado manualmente de [book] para o tipo correspondente.
legal-doc
Utilizada para referenciar documentos jurídicos, incluem informações sobre, legislação, jurisprudência e doutrina. Ex.:
Brasil. Portaria no 1169/GM em 15 de junho de 2004. Institui a Política Nacional de Atenção Cardiovascular de Alta Complexidade, e dá outras providências. Diário Oficial 2004; seção 1, n.115, p.57.

Newspaper
Utilizada para referenciar publicações seriadas sem cunho científico, como revistas e jornais. Ex.:
TAVARES de ALMEIDA, M. H. “Mais do que meros rótulos”. Artigo publicado no Jornal Folha de S. Paulo, no dia 25/02/2006, na coluna Opinião, p. A. 3.

Database
Utilizada para referenciar bases e bancos de dados. Ex.:
IPEADATA. Disponível em: http://www.ipeadata.gov.br. Acesso em: 12 fev. 2010.

Software
Utilizada para referenciar um software, um programa de computador. Ex.:
Nelson KN. Comprehensive body composition software [computer program on disk]. Release 1.0 for DOS. Champaign (IL): Human Kinetics, c1997. 1 computer disk: color, 3 1/2 in.

Webpage
Utilizada para referenciar, web sites ou informações contidas em blogs, twiter, facebook, listas de discussões dentre outros.
Exemplo 1
UOL JOGOS. Fórum de jogos online: Por que os portugas falam que o sotaque português do Brasil é açucarado???, 2011. Disponível em <http://forum.jogos.uol.com.br/_t_1293567>. Acessado em 06 de fevereiro de 2014.

Exemplo 2
BANCO CENTRAL DO BRASIL. Disponível em: www.bcb.gov.br.

Other
Utilizada para referenciar tipos não previstos pelo SciELO. Ex.:
INAC. Grupo Nacional de Canto e Dança da República Popular de Moçambique. Maputo, [s.d.].

“Previous” em Referências
Há normas que permitem que as obras que referenciam a mesma autoria repetidamente, sejam substituídas por um traço sublinear equivalente à seis espaços. Ex.:
______. Another one bites the dust: Merck cans hep C fighter Victrelis as new meds take flight [Internet]. Washington: FiercePharma; 2015.
Ao fazer a marcação de [refs] o programa duplicará a referência com previous da seguinte forma:
[ref id=”r16” reftype=”book”] [text-ref]______. Another one bites the dust: Merck cans hep C fighter Victrelis as new meds take flight [Internet]. Washington: FiercePharma; 2015[/text-ref]. *______. Another one bites the dust: Merck cans hep C fighter Victrelis as new meds take flight [Internet]. Washington: FiercePharma; 2015*[/ref]
Note
Em referências que apresentam o elemento [text-ref], o dado a ser marcado deverá ser o que consta após o [/text-ref]. Nunca fazer a marcação da referência que consta em [text-ref][/text-ref].
Para identificação de referências com esse tipo de dado, selecione os traços sublineares e identifique com a tag [*authors] com asterisco. O programa recuperará o nome do autor previamente marcado e fará a identificação automática do grupo de autores, identificando o sobrenome e o primeiro nome.
Marcação Automática
O programa Markup dispõe de uma funcionalidade que otimiza o processo de marcação das referências bibliográficas que seguem a norma Vancouver. Caso haja adaptações na norma, o programa não fará a identificação corretamente.
Selecione todas as referências

Clique no botão “Markup: Marcação Automática 2”

Apesar do programa fazer a marcação automática das referências, será necessário analisar atentamente referência por referência afim de verificar se algum dado deixou de ser marcado ou foi marcado incorretamente. Se houver algum erro a ser corrigido, entre no nível de [ref] em “Barras de Ferramentas Personalizadas” e faça as correções e/ou inclua as marcações faltantes.
Note
O uso da marcação automática em referências só é possível caso as referências bibliográficas estejam de acordo com a norma Vancouver, seguindo-a literalmente. Para as demais normas tal funcionalidade não está disponível.
Referência numérica
Alguns periódicos apresentam referências bibliográficas numeradas, as quais são referenciadas assim no corpo do texto. O número correspondente à referência também deve ser marcado. Após a marcação do grupo de referências, desça um nível em [ref], selecione o número da referência e marque com o elemento [label]:
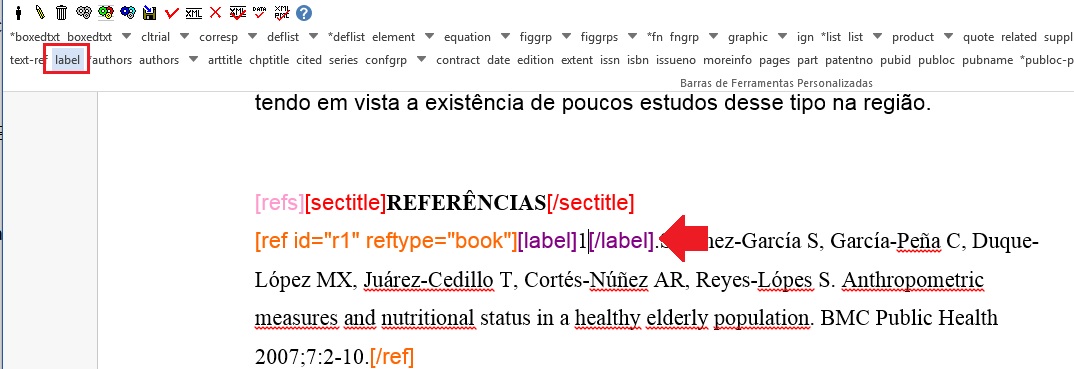
Note
O programa Markup não faz a identificação automática desse dado.
Notas de Rodapé
As notas de rodapé podem aparecer antes do corpo do texto ou depois. Não há uma posição específica dentro do arquivo .doc. Entretando é necessário avaliar a nota indicada, pois dependendo do tipo de nota inserido em fn-type, o programa gera o arquivo .xml com informações de notas de autores em <front> ou em <back>. Para mais informações sobre essa divisão consultar na documentação SPS os itens <http://docs.scielo.org/projects/scielo-publishing-schema/pt_BR/1.2-branch/tagset.html#notas-de-autor> e <http://docs.scielo.org/projects/scielo-publishing-schema/pt_BR/1.2-branch/tagset.html#notas-gerais>.
Selecione nota e marque com o elemento [fngrp].
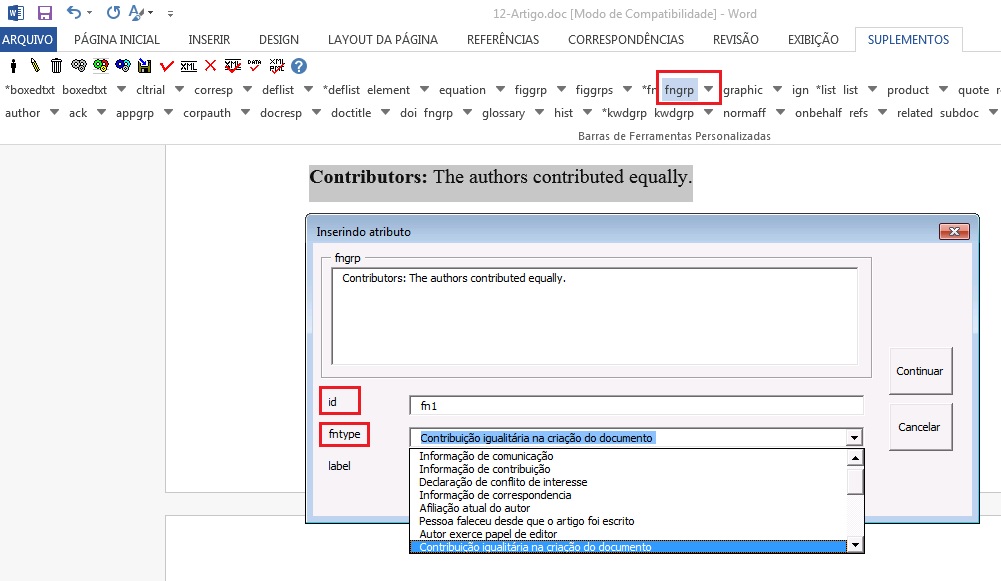
Caso a nota apresente um título ou um símbolo, selecione a informação e identifique com o elemento [label]:
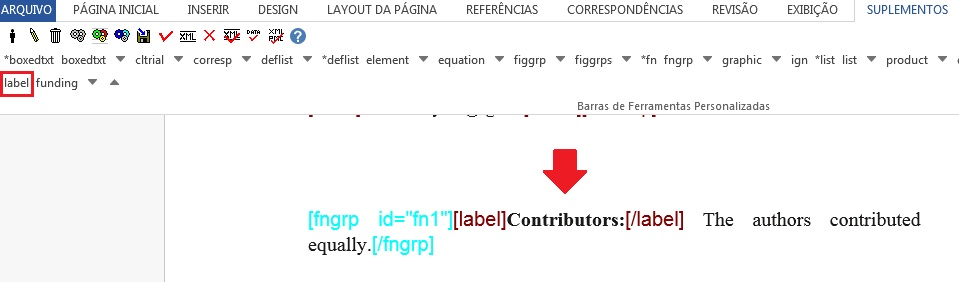
Tipos de notas
Suporte sem Informação de Financiamento
Para notas de rodapé que apresentam suporte de entidade, instituição ou pessoa física sem dado de financiamento e número de contrato, selecione a nota do tipo “Pesquisa na qual o artigo é baseado foi apoiado por alguma entidade”:
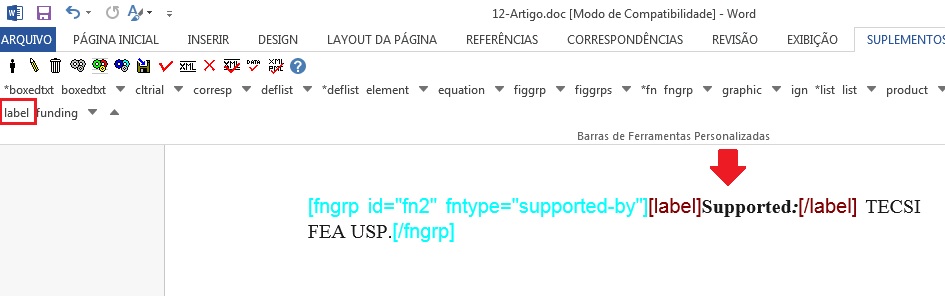
Suporte com Dados de Financiamento
Para notas de rodapé que apresentam dados de financiamento com número de contrato, selecione nota do tipo “Declaração ou negação de recebimento de financiamento em apoio à pesquisa na qual o artigo é baseado”. Nesse caso, será preciso marcar os dados de financiamento com o elemento [funding]:
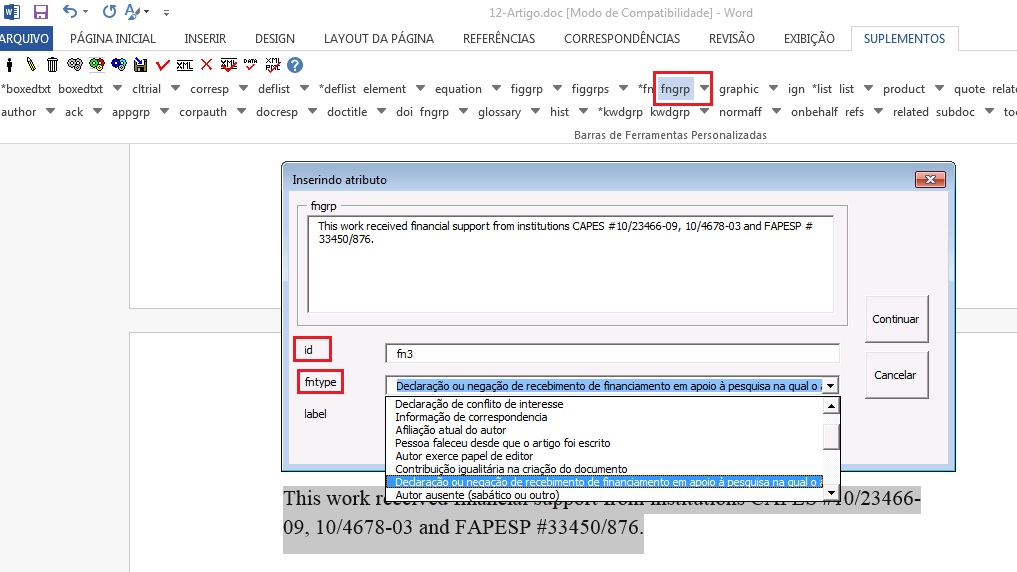
O próximo passo será selecionar o primeiro grupo de instituição financiadora + número de contrato e marcar com o elemento [award].
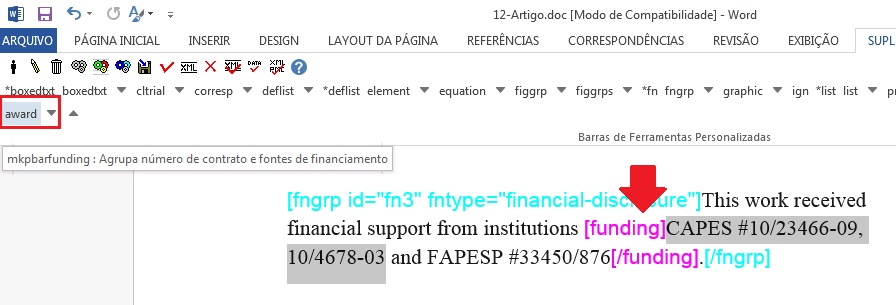
Em seguida, selecione a instituição financiadora e marque com o elemento [fundsrc]:
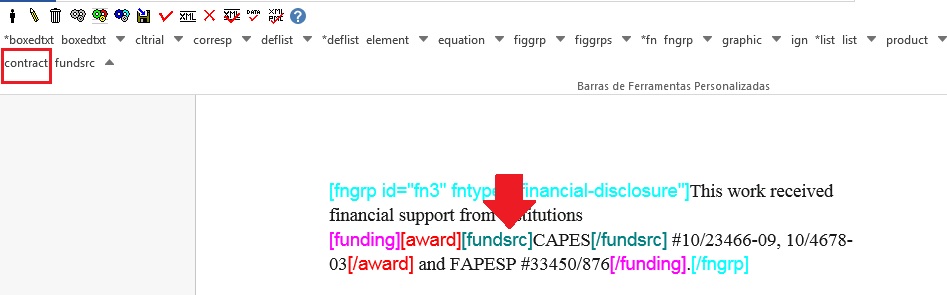
Depois selecione cada número de contrato e identifique com o elemento [contract]:
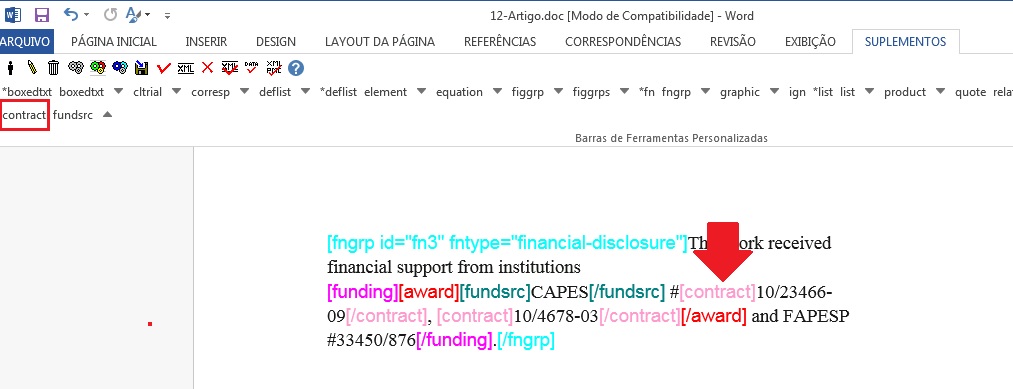
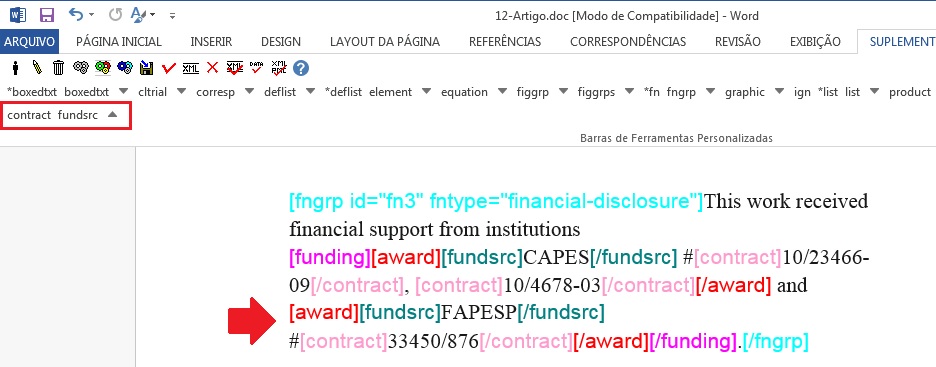
Caso a nota de rodapé apresente mais que uma instituição financiadora e número de contrato, faça a marcação conforme o exemplo abaixo:
Notas de Rodapé - Identificação Automática
Para notas de rodapé que estão posicionadas ao fim de cada página no documento, com formatação de notas de rodapé do Word, é possível fazer a marcação automática do número referenciado no documento e sua nota respectiva.
As chamadas de nota de rodapé no corpo do texto deverão estar com uma formatação simples: em formato numérico e sobrescrito. Já as notas, deverão estar em formato de nota de rodapé do Word com um espaço antes da nota.

Estando formatado corretamente, clique com o mouse em qualquer parágrafo e em seguida clique na tag [*fn].

Ao clicar em [*fn] o programa fará a marcação automática de [xref] no corpo do texto e também da nota ao pé da página.

Apêndices
A marcação de apêndices, anexos e materiais suplementares deve ser feita pelo elemento [appgrp]:

Selecione todo o grupo de apêndice, inclusive o título, se existir, e clique em [appgrp]:
Selecione apêndice por apêndice e identifique com o elemento [app]
Note
o id deve ser sempre único no documento.
Caso o apêndice seja de figura, tabela, quadro etc, selecione o título de apêndice e marque com o elemento [sectitle]. Utilize os botões flutuantes (tabwrap, figgrp, *list, etc) do programa Markup para identificação do objeto que será marcado.
botões flutuantes

Exemplo, selecione a figura com seu respectivo label e caption e marque com o elemento [figgrp]
Note
Assegure-se de que o id da figura de apêndice é único no documento.
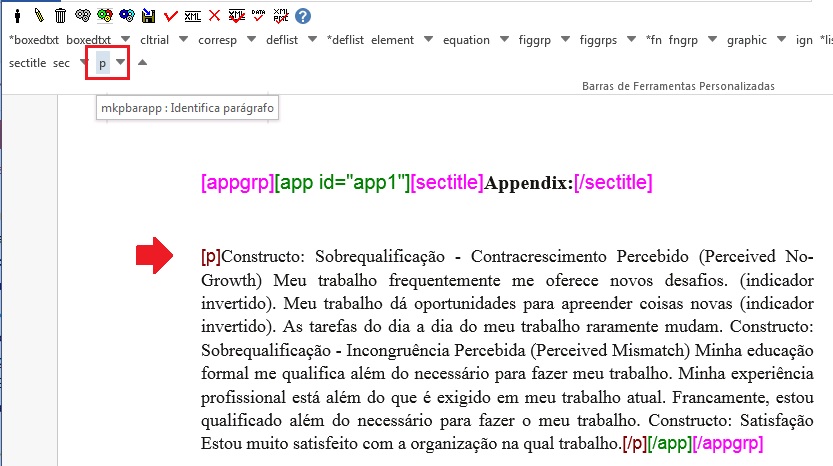
Para apêndices que apresentam parágrafos, selecione o título do apêndice e marque com o elemento [sectitle]
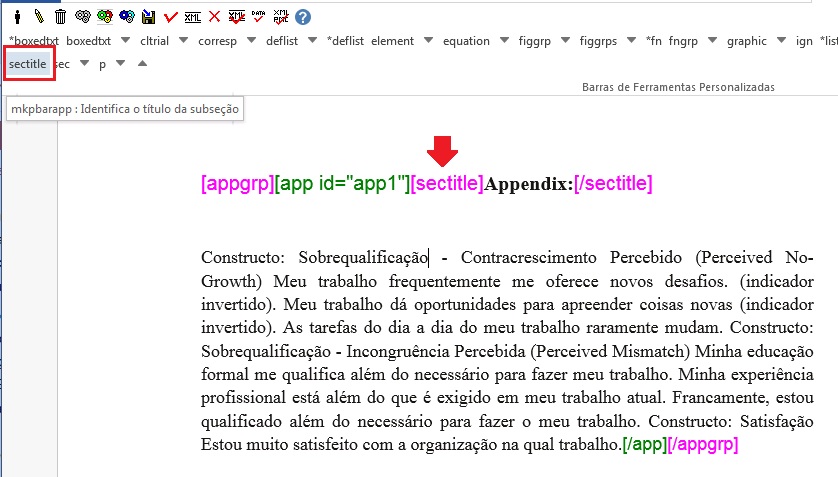
Selecione o parágrafo e marque com o elemento [p]
Agradecimentos
A seção de agradecimento, geralmente, encontra-se entre o final do corpo do texto e as referências bibliográficas. Para marcação automática dos elementos de agradecimento selecione todo o texto, inclusive o título desse item, e marque com o elemento [ack].
selecionando [ack]

Resultado esperado

Comumente os agradecimentos apresentam dados de financiamento, com número de contrato e instituição financiadora. Quando presentes, marque os dados com o elemento [funding].

Selecione o primeiro conjunto de instituição e número de contrato e marque com o elemento [award]:
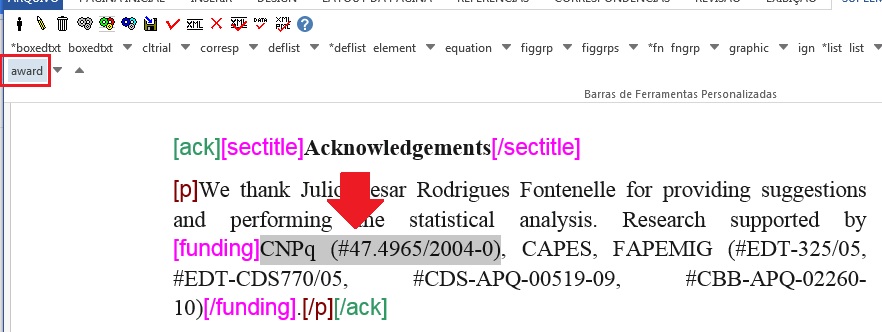
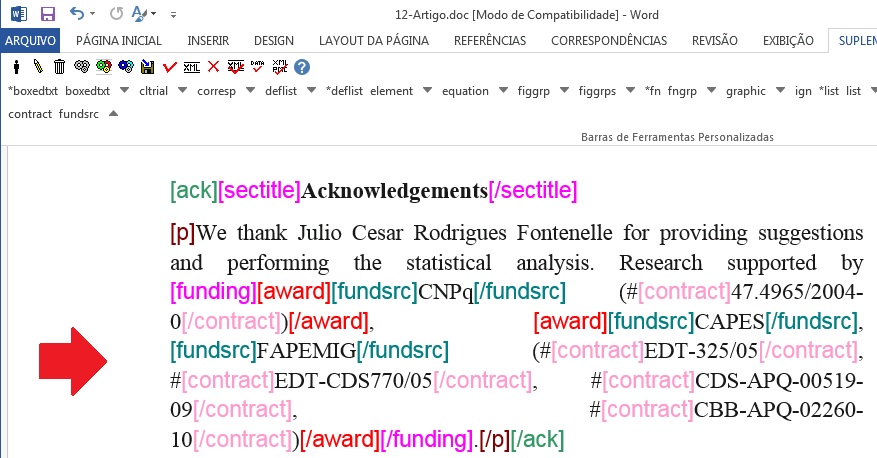
Selecione agora a instituição financiadora e marque com o elemento [fundsrc]:

Note
Caso haja mais que uma instituição financiadora para o mesmo número de contrato, selecione cada instituição em um [fundsrc]
Marque o número de contrato com o elemento [contract]:

Quando houver mais de uma instituição financiadora e número de contrato, marcar conforme segue:
Glossário
Glossários são incluídos nos documentos após referências bibliográficas, em apêndices ou caixas de texto. Para marcá-lo, selecione todos os itens que a compõe e marque com o elemento [glossary]. Selecione todos os itens novamente e marque com o elemento lista-definição. Segue exemplo de marcação de glossário presente após referências bibliográficas:
Selecione todos os dados de glossário e marque com o elemento Lista de Definição:
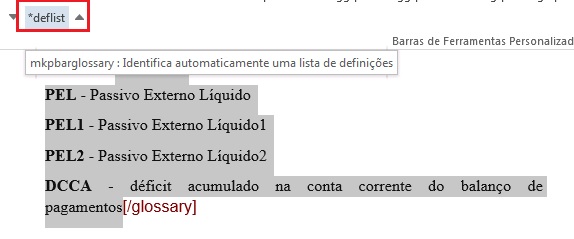
Abaixo o resultado da marcação de glossário:

xmlbody
Tendo formatado o corpo do texto de acordo com o ítem Formatação do Arquivo e após a marcação das referências bibliográficas, é possível iniciar a marcação do [xmlbody].
Selecione todo o corpo do texto e clique no botão [xmlbody], confira as informações de seções, subseções, citações etc as quais são apresentadas na caixa de diálogo e, se necessário, corrija e clique em “Aplicar”.

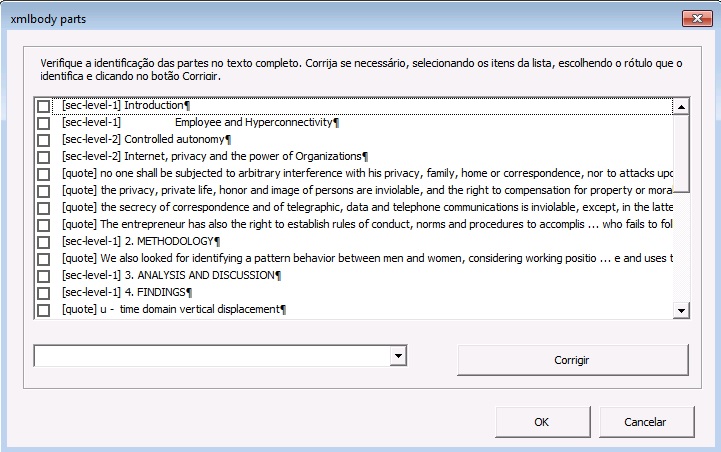
Note
Caso haja alguma informação incorreta, selecione o item a ser corrigido na janela, clique no menu dropdown ao lado do botão “Corrigir”, selecione a opção correta e clique em “Corrigir”. Confira novamente e clique em “Aplicar”.
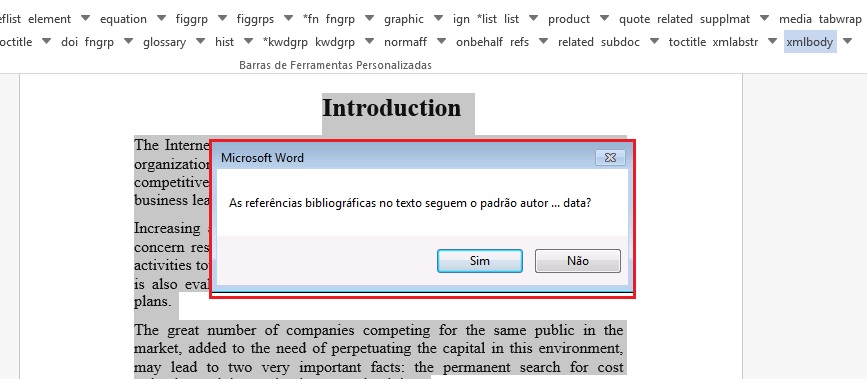
Ao clicar em “Aplicar” o programa perguntará se as referências no corpo do texto obedecem o padrão de citação author-data. Se o documento apresenta esse padrão clique em [sim], caso contrário, clique em [não].

Sistema numérico

É a partir da formatação do documento indicada no Formatação do Arquivo que o programa marca automaticamente seções, subseções, parágrafos, referências de autores no corpo do texto, chamadas de figuras e tabelas, equações em linha etc.

Verifique se os dados foram marcados corretamente e complete a marcação dos elementos ainda não identificados no documento.
Seções e Subseções
Após a marcação automática do [xmlbody], certifique-se de que os tipos de seções foram selecionados corretamente.

Em alguns casos, a marcação automática não identifica a seção corretamente. Nesses casos, selecione a seção, clique no lápis “Editar Atributos” e indique o tipo correto de seção.
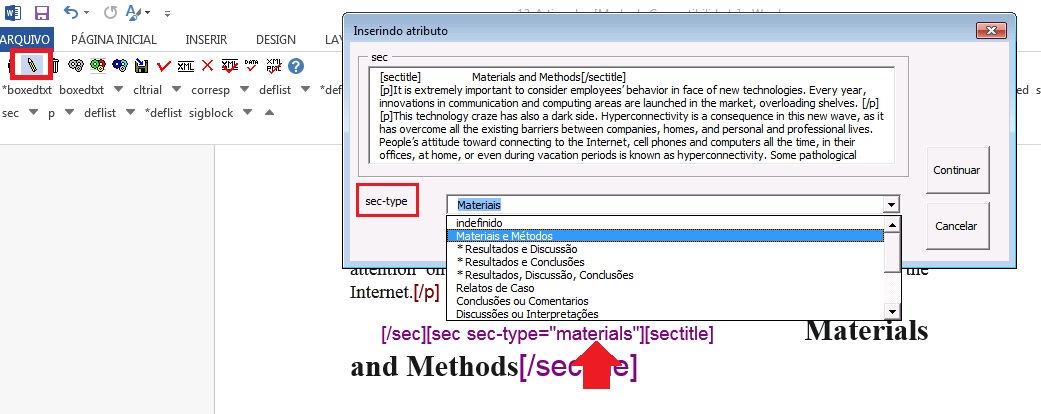
Resultado
Note
Referência Cruzada de Referências Bibliográficas
Referências no sistema autor-data serão identificados automaticamente no corpo do texto somente se o sobrenome do autor e a data estiverem marcados em Referências Bibliográficas e, apenas se o sobrenome do autor estiver presente no corpo do texto igual ao que foi marcado em [Refs]. Há alguns casos que o programa Markup não irá fazer a marcação automática de [xref] do documento. Ex.:
Citações de autor
Sobrenome do autor + “in press” ou derivados:

Autor corporativo:

Para identificar o [xref] das citações que não foram marcadas automaticamente, primeiramente verifique qual o id da referência bibliográfica não identificada, em seguida selecione a citação desejada e marque com o elemento [xref].
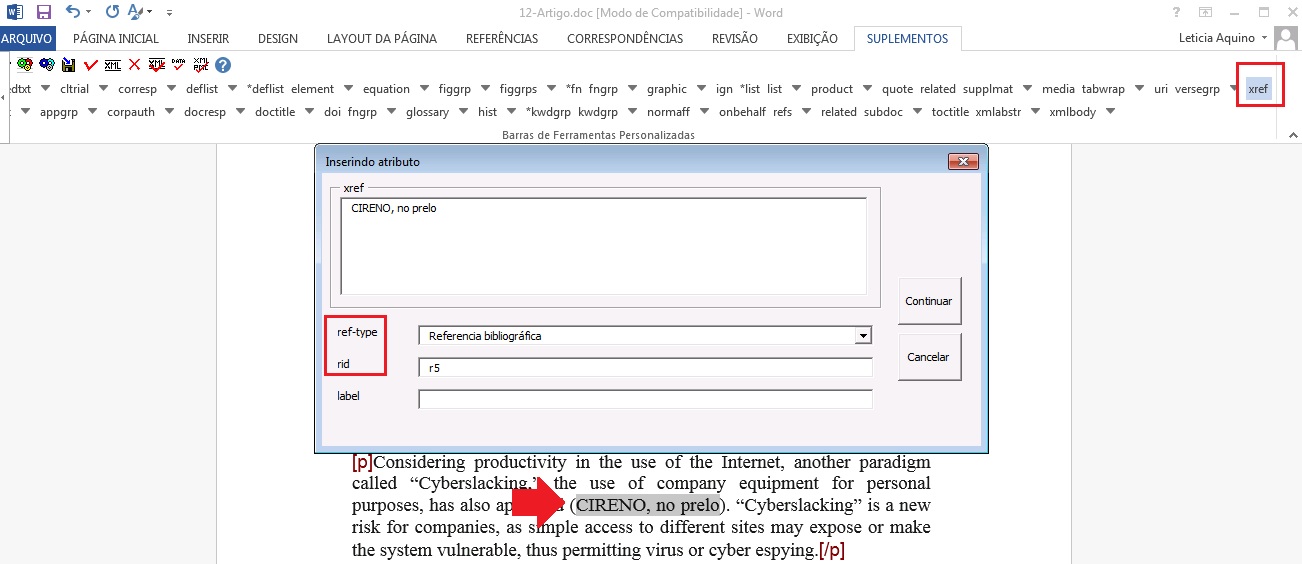
Preencha apenas os campos “ref-type” e “rid”. Em “ref-type” selecione o tipo de referência cruzada que será feito, nesse caso “Referencia Bibliográfica”, em seguida indique o id correspondente à referência bibliográfica citada. Confira e clique no botão [Continuar].

Note
Não insira hiperlink no dado a ser marcado.
Chamada de Quadros, Equações e Caixas de Texto:
A marcação das referências cruzadas de quadros, equações e caixas de texto segue as mesmas etapas descritas em referências bibliográficas.
Quadro:
Selecione [ref-type] do tipo figura e indique a sequência do ID no documento para este elemento.

Equações:
Selecione [ref-type] do tipo equação e indique a sequência do ID no documento para este elemento.

Caixa de Texto:
Selecione [ref-type] do tipo caixa de texto e indique a sequência do ID no documento para este elemento.

Parágrafos
Os parágrafos são marcados automaticamente no corpo do texto ao fazer a identificação de [xmlbody]. Caso o programa não tenha marcado um parágrafo ou caso a marcação automática tenha identificado um parágrafo com o elemento incorreto, é possível fazer a marcação manual desse dado. Para isso, selecione o parágrafo desejado, verifique se o parágrafo pertence a alguma seção ou subseção e encontre o elemento [p] nos níveis de [sec] ou [subsec].

Resultado

Figuras
Ao fazer a marcação de [xmlbody] o programa identifica automaticamente as imagens com o elemento “graphic”.
Para marcar o grupo de dados da figura, selecione a imagem, sua legenda (label e caption) e fonte, se houver e marque com o elemento [figgrp].
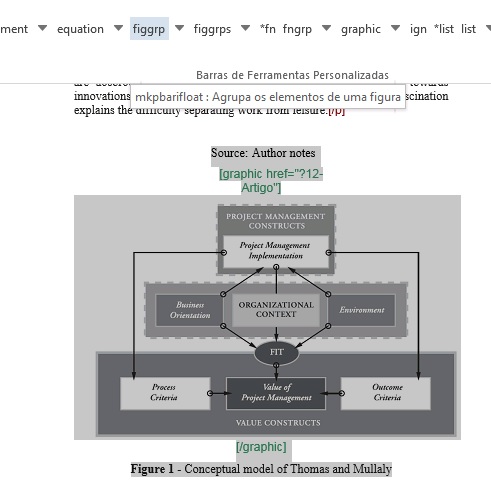
- Preencha “id” da figura na janela aberta pelo programa.
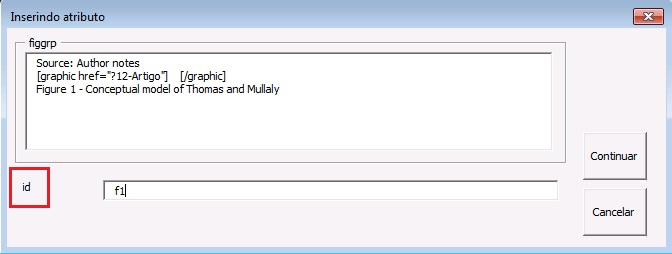
Certifique-se de que o id de figura é único no documento.
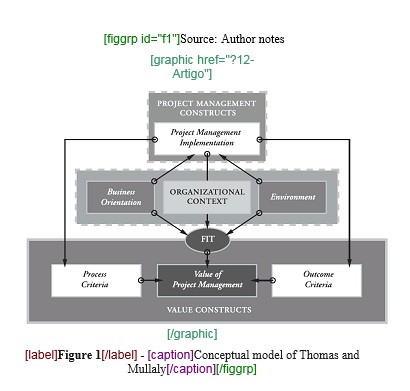
Note
A marcação completa de figura é de extrema importância. Se a figura não for marcada com o elemento [figgrp] e seus respectivos dados, o programa não gerará o elemento [fig] correspondente no documento.
- Após a marcação de [figgrp] caso a imagem apresente informação de fonte, selecione o dado e identifique com o elemento [attrib]:
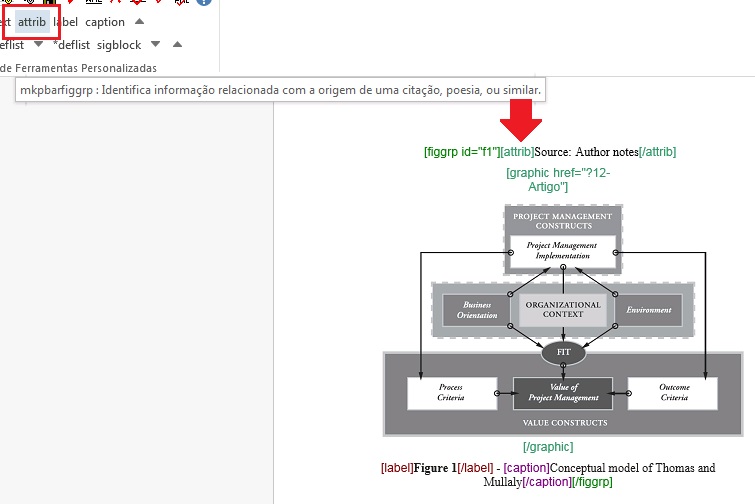
Note
A marcação de label e caption será automática se estiver conforme as instruções dadas em Formatação do Arquivo, com label e caption abaixo da imagem no arquivo .doc. A informação de fonte deve estar acima da imagem. Veja o exemplo da imagem acima.
Tabelas
As tabelas podem ser apresentadas como imagem ou em texto. As tabelas que estão como imagem devem apresentar o label, caption e notas (essa última, se existir) em texto, para que todos os elementos sejam marcados. As tabelas devem estar, preferencialmente, em formato texto, usandos-se figuras para tabelas complexas (com células mescladas, símbolos, fórmulas, imagens etc).
Tabelas em Imagem
Ao fazer a marcação de [xmlbody] o programa identifica automaticamente o “graphic” da tabela. Selecione todos os dados da tabela (imagem, label, caption e notas de rodapé, se houver) e identifique com o elemento [tabwrap].
Mesmo estando na forma de figura, o id do elemento deverá ser o indicado para tabelas (t1, t2, t3 …). Certifique-se de que o id de tabela é único no documento.
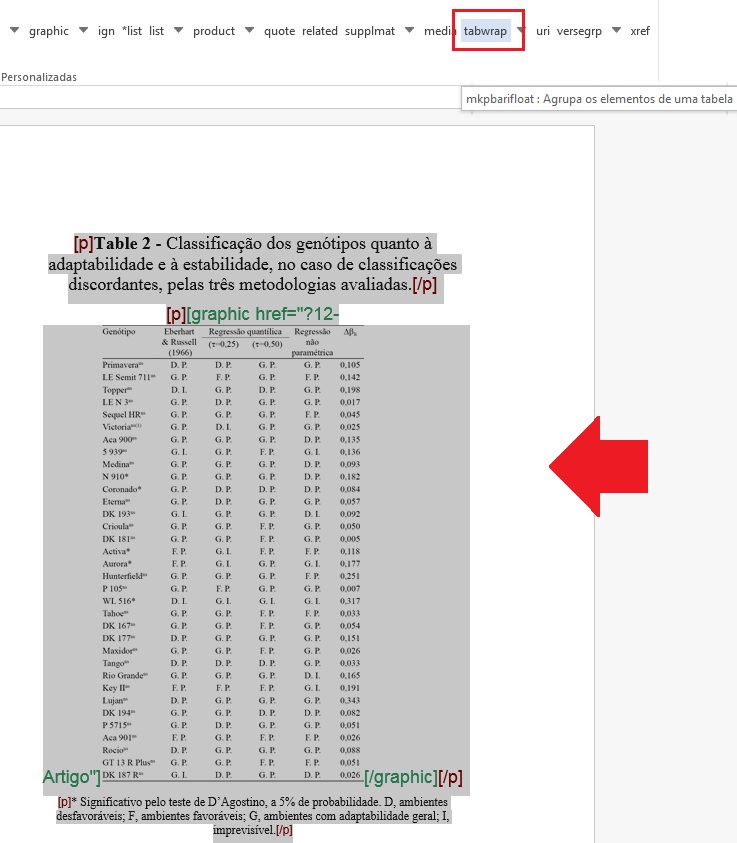
- Preencha o “id” da tabela na janela aberta pelo programa.
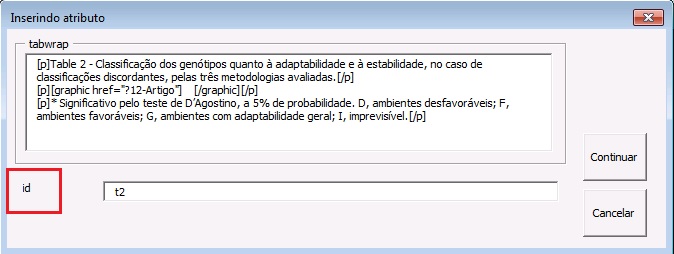
Certifique-se de que o id da tabela é único no documento.
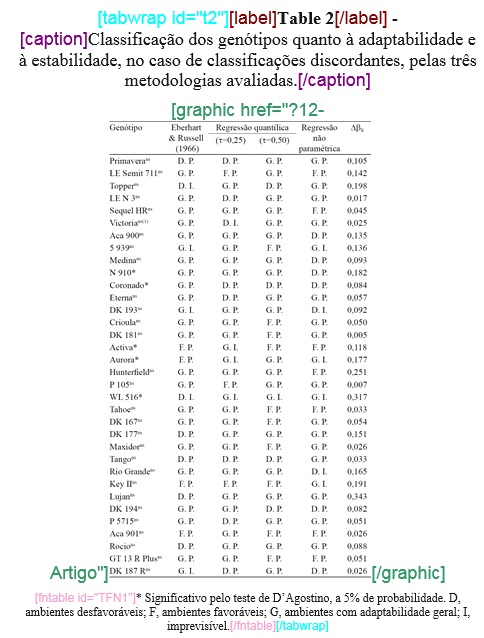
Note
O programa faz a marcação automática de label, caption e notas de rodapé de tabela.
Tabelas em Texto
O programa também codifica tabelas em texto. Para isso, selecionte toda a informação de tabela (label, caption, corpo da tabela e notas de rodapé, se houver) e marque com o elemento [tabwrap].
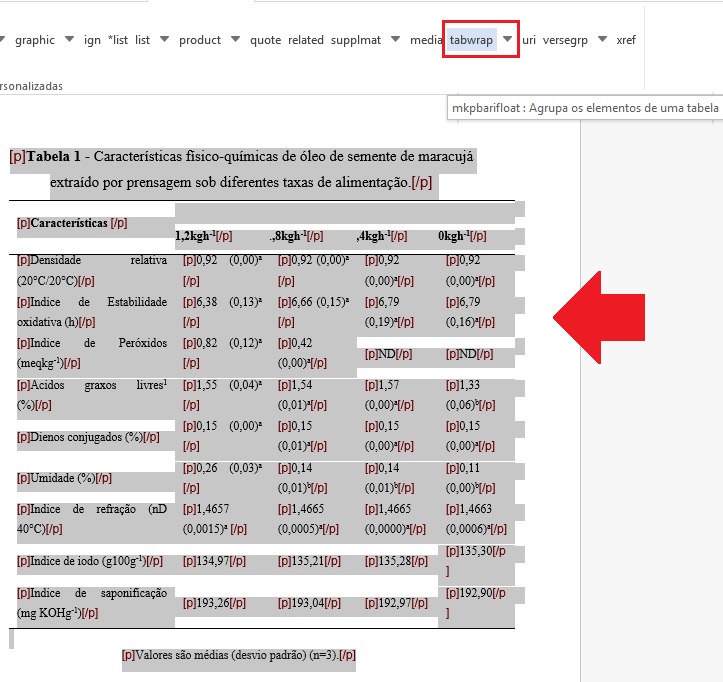
Note
O cabeçalho das colunas da tabela deve estar em negrito. Essa formatação é essencial para que o programa consiga fazer a identificação correta de [thead] e os elementos que o compõe.
- Preencha “id” da tabela na janela aberta pelo programa.
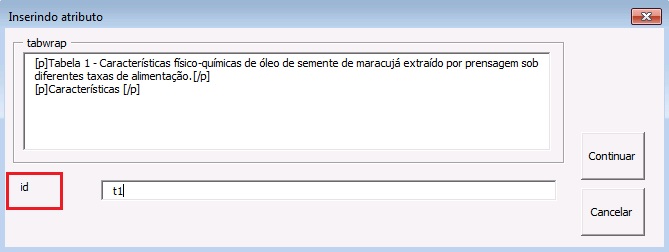
Certifique-se de que o id de tabela é único no documento.
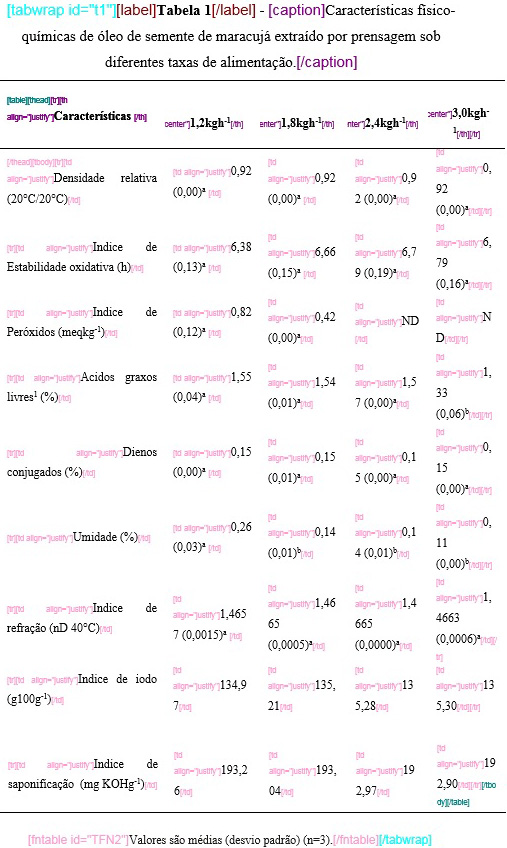
Note
Tabelas irregulares, com células mescladas ou com tamanhos extensos possivelmente apresentarão problemas de marcação. Nesse caso alguns elementos deverão ser identificados manualmente por meio do programa Markup ou no XML quando este for gerado.
Equações
Há dois tipos de equações que o programa suporta: as equações em linha (em meio a um parágrafo) e as equações em parágrafo.
Equação em linha
As equações em linha devem ser inseridas no parágrafo como imagem. A marcação é feita automaticamente pelo programa ao fazer a identificação de [xmlbody].

Se o programa não fizer a marcação automática da equação em linha, é possível fazer a marcação manualmente. Para isso selecione a equação em linha e clique no elemento [graphic].
No campo “href” insira o nome do arquivo:
O resultado será:
Equações
As equações disponíveis como parágrafos devem ser identificadas com o elemento [equation]
Preencha do “id” da equação na janela aberta pelo programa. Certifique-se de que o id da equação é único no documento.
Ao fazer a marcação da equação, o programa identifica o elemento [equation]. Caso haja informação de número da equação, identifique-o com o elemento [label].
Caixa de Texto
As caixas de texto podem apresentar figuras, equações, listas, glossários ou um texto. Para marcar esse elemento, selecione toda a informação de caixa de texto, inclusive o label e caption, e identifique com o botão [*boxedtxt]:
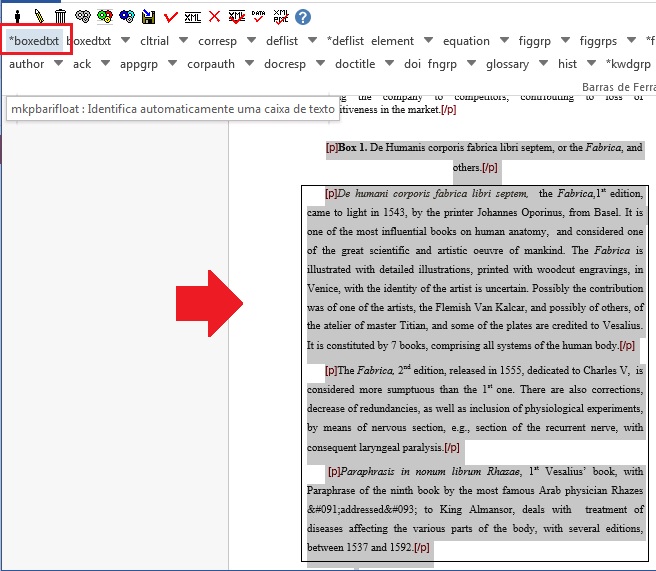
Preencha o campo de ID da caixa de texto na janela que se abrirá após a seleção de [*boxedtxt]. Certifique-se de que o id de boxed-text é unico no documento.
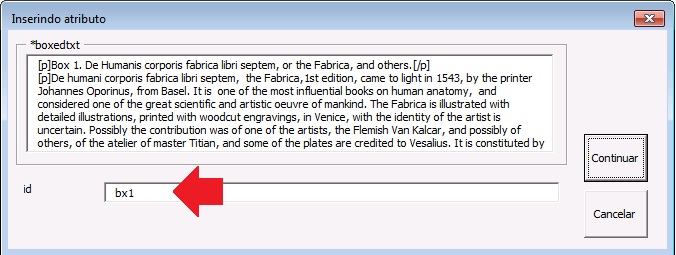
Utilizando o botão [*boxedtxt] o programa faz a marcação automática de título da caixa de texto e também dos parágrafos:

Caso a caixa de texto apresente uma figura, uma tabela, listas etc, é possível também utilizar o elemento [*boxedtxt] e depois fazer a marcação desses objetos através das tags flutuantes do programa.
Marcação de Versos
Para identificar versos ou poemas no corpo do texto, selecione toda a informação, inclusive título e autoria, se existir, e identifique com o elemento [versegrp]:
O programa identificará cada linha como [verseline]. Caso o poema apresente título, exclua a marcação de verseline, selecione o título e marque com o elemento [label]. A autoria do poema deve ser marcada com o elemento [attrib].


Citações Diretas
As citações são marcadas automaticamente no corpo do texto, ao fazer a marcação de [xmlbody], desde que esteja com a formatação adequada.

Caso o programa não faça a marcação automática, selecione a citação desejada e em seguida marque com o elemento [quote]:

O resultado deve ser:
Listas
Para identificar listas selecione todos os itens e marque com o elemento [*list]. Selecione o tipo de lista na janela aberta pelo programa:
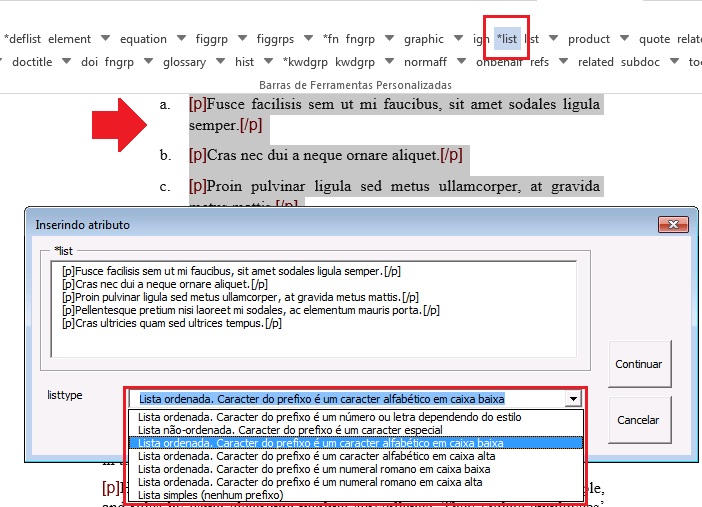
Verifique os tipos possíveis de lista em elemento-list e selecione o tipo mais adequado:

Note
O programa Markup não faz a marcação de sublistas. Para verificar como marcar sublistas, consulte a documentação “Markup_90_O_que_ha_novo.pdf” item “Processos Manuais”.
O atributo @list-type especifica o prefixo a ser utilizado no marcador da lista. Os valores possíveis são:
| Valor | Descrição |
|---|---|
| order | Lista ordenada, cujo prefixo utilizado é um número ou letra dependendo do estilo. |
| bullet | Lista desordenada, cujo prefixo utilizado é um ponto, barra ou outro símbolo. |
| alpha-lower | Lista ordenada, cujo prefixo é um caractere alfabético minúsculo. |
| alpha-upper | Lista ordenada, cujo prefixo é um caractere alfabético maiúsculo. |
| roman-lower | Lista ordenada, cujo prefixo é um numeral romano minúsculo. |
| roman-upper | Lista ordenada, cujo prefixo é um numeral romano maiúsculo. |
| simple | Lista simples, sem prefixo nos itens. |
Lista de Definição
Para marcar listas de definições selecione todos os dados, inclusive o título se existir, e marque com o elemento [*deflist]
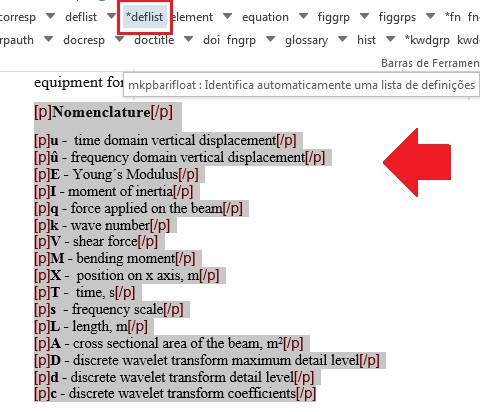
Na janela aberta pelo programa, preencha o campo de “id” da lista. Certifique-se de que o id é único no documento.
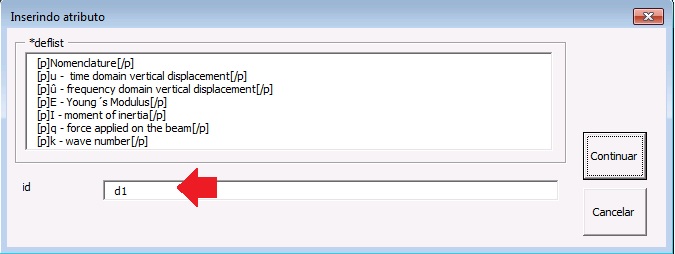
Após isso, confirme o título da lista de definição e em seguida a marcação do título:
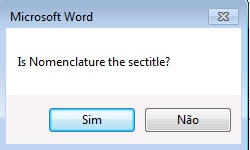
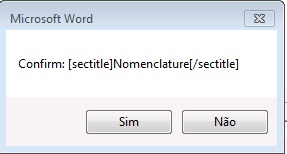
Ao finalizar, verifique se a marcação automática de cada termo da lista de definição estão de acordo com o modelo abaixo.

Note
O programa faz a marcação automática de cada item da lista de definições apenas se a lista estiver com a formatação requerida pelo SciELO: com o termo em negrito, hífen como separador e a definição do termo sem formatação.
Caso o programa não faça a marcação automática da lista de definições, é possível identificar os elementos manualmente.
- Selecione toda a lista de denifições e marque com o elemento [deflist], sem asterisco:

- Marque o título com o elemento [sectitle] (apenas se houver informação de título):
- Selecione o termo e a definição e marque com o elemento [defitem]:

- Selecione apenas o termo e marque com o elemento [term]:

- O próximo passo será selecionar a definição e identificar com o elemento [def]:
Faça o mesmo para os demais termos e definições.
Material Suplementar
A marcação de materiais suplementares deve ser feita pelo elemento [supplmat]. A indicação de Material suplementar pode estar em linha, como um parágrafo “solto” no documento ou como apêndice.
Objeto Suplementar em [xmlbody]
Selecione todo o dado de material suplementar, incluindo label e caption, se existir, e marque com o elemento [supplmat]:
Na janela aberta pelo programa, preencha o campo de “id”, o qual deverá ser único no documento, e o campo “href” com o nome do arquivo .doc:
Na sequência, faça a marcação do label do material suplementar. Selecione todo o grupo de dados da figura e marque com o elemento [figgrp]. A marcação deverá ser conforme o exemplo abaixo:

Material Suplementar em Linha
Selecione a informação de material suplementar e marque com o elemento [supplmat]:
Na janela aberta pelo programa, preencha o campo de “id”, o qual deverá ser único no documento, e o campo “href” com o nome do pdf suplementar exatamente como consta na pasta “src”.
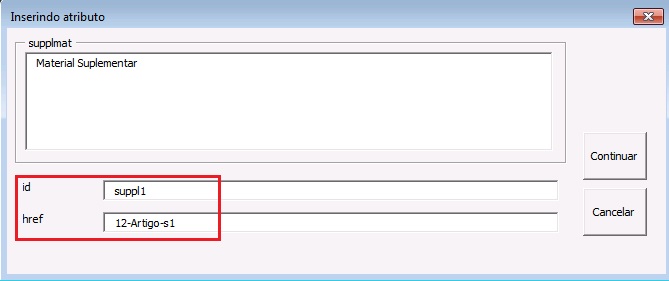
A marcação deverá ser conforme abaixo:

Note
Antes de iniciar a marcação de material suplementar certifique-se de que o PDF suplementar foi incluído na pasta “src” comentado em Estrutura de Pastas.
Material Suplementar em Apêndice
Nesse caso, marca-se, primeiramente, o objeto com o elemento [appgrp] e em seguida com os elementos de [app].
Selecione novamente todo dado de material suplementar e marque com o elemento [app]. Em seguida, marque o label do material com o elemento [sectitle]:
Selecione o material suplementar e identifique com o elemento [supplmat]:
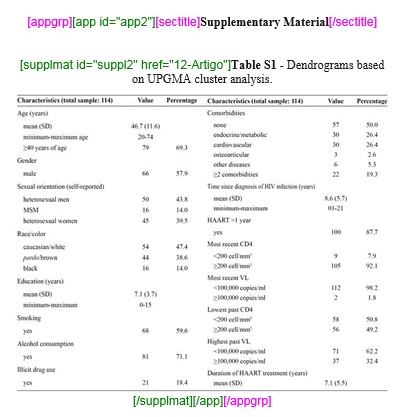
Após a marcação de [supplmat] marque o objeto do material com as tags flutuantes:
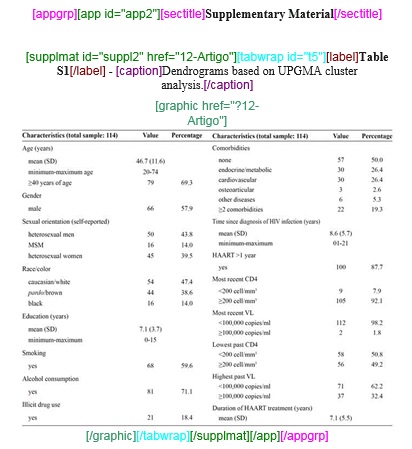
Sub-article
Tradução
Arquivos traduzidos apresentam uma formatação específica. Veja abaixo os itens que devem ser considerados:
- O arquivos de idioma principal devem seguir a formatação indicada em Formatação do Arquivo
- Após a última informação do arquivo principal - ainda no mesmo .doc ou .docx - insira a tradução do arquivo.
A tradução do documento deve ser simplificada:
-
- Inserir apenas as informações que apresentam tradução, por exemplo:
-
- Seção - se houver tradução;
- Autores e Afiliações - apenas se houver afiliação traduzida;
- Resumos - se houver tradução;
- Palavras-chave - se houver tradução;
- Correspondência - se houver tradução;
- Notas de autor ou do arquivo - se houver tradução;
- Corpo do texto.
- Título é mandatório;
- Não inserir novamente referências bibliográficas;
- Manter as citações bibliográficas no corpo do texto conforme constam no PDF.
Verificar modelo abaixo:

Identificando Arquivos com Traduções
Com o arquivo formatado, faça a identificação do documento pelo elemento [doc] e complete as informações. A marcação do arquivo de idioma principal não muda, siga as orientações anteriores para a marcação dos elementos.

Note
É fundamental que o último elemento do arquivo como um todo seja o elemento [/doc]. Certifique-se disso.
Finalizado a marcação do arquivo de idioma principal selecione toda a tradução e marque com o elemento [subdoc]. Na janela aberta pelo programa, preencha os campos a seguir:
- ID - Identificador único do arquivo: S + nº de ordem;
- subarttp - selecionar o tipo de artigo: “tradução”;
- language - idioma da tradução do arquivo.
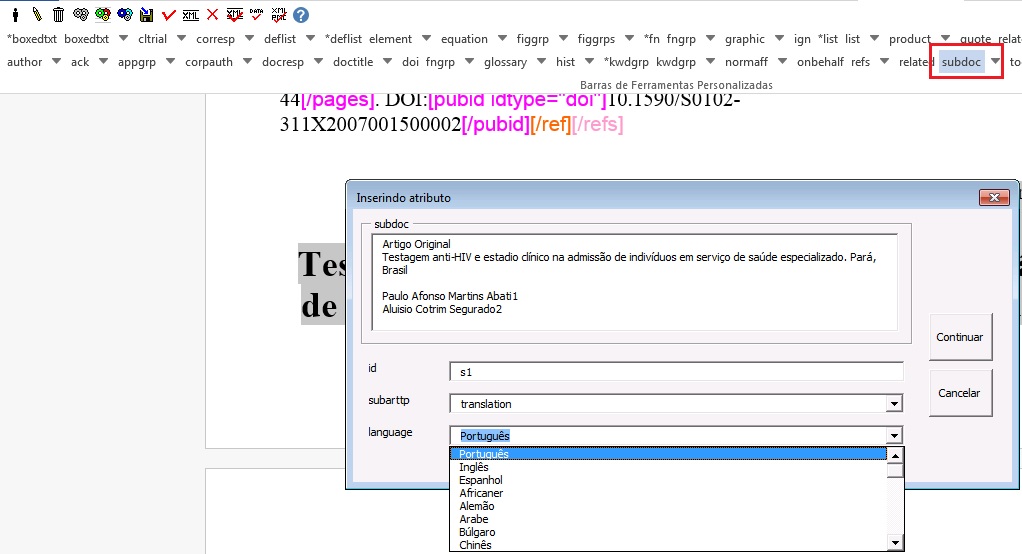
Agora, no nível de [subdoc], faça a marcação dos elementos que compõem a tradução do documento:
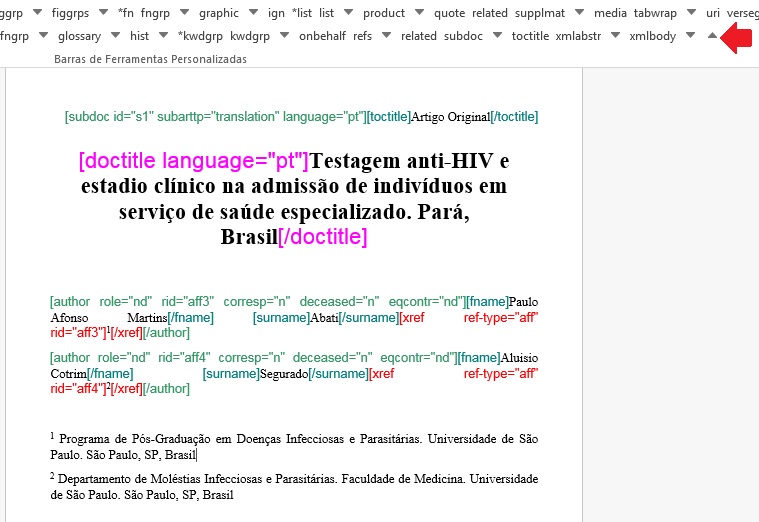
Note
O programa Markup não faz a identificação automática do arquivo traduzido.
Afiliação traduzida
A marcação de afiliação traduzida não segue o padrão de marcação do artigo de idioma principal. As afiliações traduzidas não devem apresentar o detalhamento orientado anteriormente em afiliações. Em [subdoc] selecione a afiliação traduzida e identifique com o elemento [afftrans]:
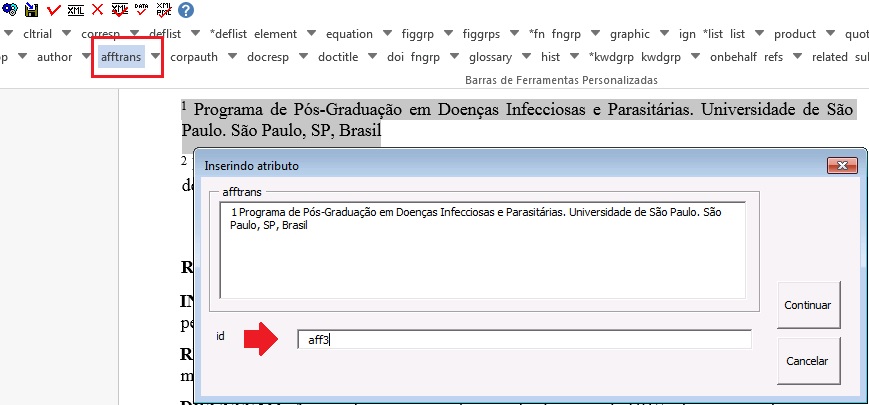
Tendo identificado todos os dados iniciais da tradução, siga com a marcação do corpo do texto.
Attention
O ID dos autores e afiliações devem ser únicos. Portanto, não inserir o mesmo ID do idioma principal.
Identificando ‘body’ de tradução
A marcação do corpo do texto segue a mesma orientação anterior. Selecione todo o corpo do texto e marque com o elemento [xmlbody] do nível [subdoc].
O programa fará a marcação automática das referências cruzadas no corpo do texto inserindo o ‘rid” correspondente ao ‘id’ das referências bibliográficas marcadas no artigo principal.

Nesse caso mantenha o RID inserido automaticamente. Figuras, Tabelas, Equações, Apêndices etc devem apresentar ID diferente do inserido no arquivo principal. Para isso, dê continuidade nos IDs. Por exemplo:
Artigo principal apresenta 2 figuras:
Note
O ID da última figura é: ‘f2’.
No artigo traduzido também é apresentado 2 figuras:
Perceba que foi dado sequência nos IDs das figuras. Considere a regra para: Autores e suas respectivas afiliações, figuras, tabelas, caixas de texto, equações, apêndices etc.
Note
Caso haja mais de uma tradução no artigo, cmarcá-las separadamente com o elemento [subdoc].
Carta e Resposta
A Carta e resposta também devem estar em um único arquivo .doc ou .docx.
- A carta deve seguir a formatação indicada em Formatação do Arquivo
- Após a última informação da carta - ainda no mesmo .doc ou .docx - insira a resposta do arquivo.
A resposta deve estar no mesmo documento que a carta. Verifique abaixo quais são os dados que devem estar presentes na resposta:
- Inserir seção;
- Autores e Afiliações, se existente;
- Correspondência, se existente;
- Notas de autor ou do arquivo, se existente;
- Título é mandatório;
- Referências Bibliográficas, se a resposta apresentar.
Veja o modelo abaixo:
[imagem]
Identificando Carta e Resposta
Com o arquivo formatado, faça a identificação do documento pelo elemento [doc] e complete as informações. Obs.: Em [doctopic] selecione o tipo “carta”. A marcação da carta não muda, siga as orientações anteriores para a identificação dos elementos.
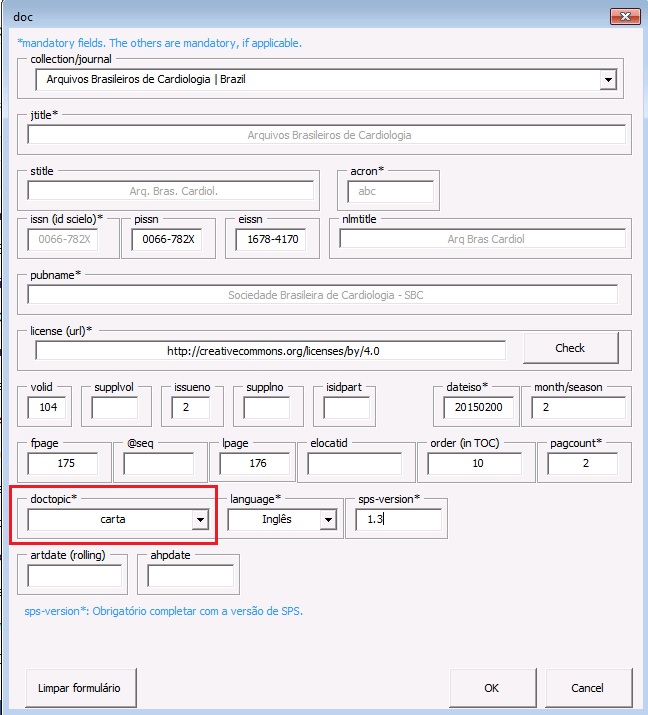
Note
É fundamental que o último elemento do arquivo como um todo seja o elemento [/doc]. Certifique-se disso.
Finalizada a marcação da carta, selecione toda a resposta e marque com o elemento [subdoc]. na janela aberta pelo programa, inclua os campos:
- ID - Identificador único do arquivo: S + nº de ordem;
- subarttp - selecionar o tipo de artigo: “reply”;
- language - idioma da resposta da carta.
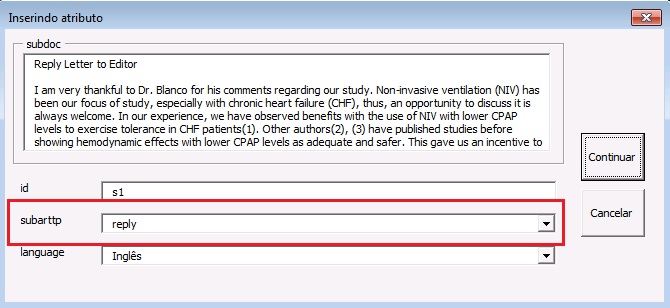
Note
O programa Markup não faz a identificação automática da resposta.
No nível de [subdoc], faça a marcação dos elementos que compõem a resposta do documento:

Note
Os dados como: afiliações e autores, objetos no corpo do texto e referencias bibliográficas devem apresentar IDs sequenciais, seguindo a ordem da carta. Exemplo, se a última afiliação da carta foi aff3, no documento de resposta a primeira afiliação será aff4 e assim por diante.
Errata
Para marcar uma errata, verifique primeiramente se o arquivo está formatado corretamente conforme orientações abaixo:
- 1ªlinha: DOI
- 2ªlinha: Seção “Errata” ou “Erratum”
- 3ªlinha: título “Errata” ou “Erratum” (de acordo com o PDF)
- pular 2 linhas
- corpo do texto

Marcando a errata
Abra a errata no Markup e identifique com o elemento [doc]. Ao abrir o formulário, selecione o título do periódico e confira os metadados que são adicionados automaticamente. Complete os demais campos e, em [doctopic], selecione o valor “errata” e clique em [OK] O programa marcará automaticamente os elementos básicos da errata como: seção, número de DOI e título:
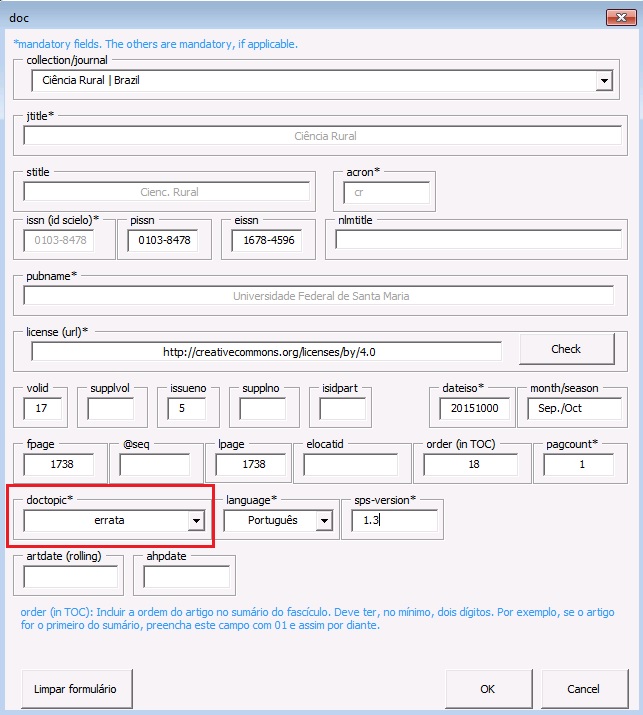
Para finalizar a marcação da errata, verifique se todos os elementos foram identificados corretamente e siga com a marcação. Selecione o corpo do texto e identifique com o elemento [xmlbody]:

Insira o cursor do mouse antes do elemento [toctitle], e clique no botão [related]. Na janela aberta pelo programa, preencha os campos: [reltp] ‘tipo de relação’ com o valor “corrected-article” e [pid-doi] ‘numero do PID ou DOI relacionado’ com o número de DOI do artigo que será corrigido e clique em [Continuar]:
O programa insere o elemento [related] o qual fará link com o artigo que apresenta erro:

Note
A versão mais recente do programa Markup aceita os tipos: DOI, PID, SciELO-PID e SciELO-AID.
Ahead Of Print
O arquivo Ahead Of Print (AOP) deve apresentar formatação indicada no ítem Formatação do Arquivo. Como arquivos em AOP não apresentam seção, volume, número e paginação, após o número de DOI deixar uma linha em branco e em seguida inserir o título do documento:

No preenchimento do formulário para Ahead Of Print, deve-se inserir o valor “00” para os campos: [fpage], [lpage], [volume] e [issue].
Em [dateiso] insira a data de publicação completa: Ano+Mês+Dia; já no campo [season], insira o mês de publicação. O total de página, [pagcount*], para arquivos AOP deve ser sempre “1”:
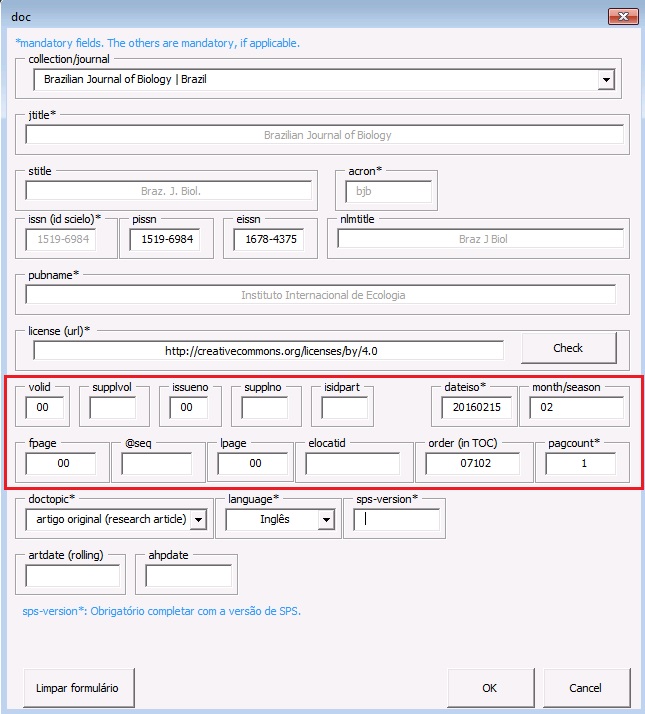
Selecione o valor “artigo original” para o campo [doctopic].
No campo [order] deve ser inserido 5 dígitos que obedecem a uma regra SciELO. Verifique abaixo a regra para construir o identificador do Ahead Of Print:
Para a construção do ID de AOP será utilizado uma parte da numeração do lote e outra da ordem do documento.
1 - Copie os três primeiros dígitos do lote
Exemplo lote da bjmbr número 7 de 2015 = lote 0715 usar: 071
2- Insira os dois últimos dígitos que representará a quantidade de artigos no lote.
| Exemplo lote bjmbr 0715 possui 5 artigos: | |
|---|---|
| 1414-431X-bjmbr-1414-431X20154135.xml | -> usar: 01 |
| 1414-431X-bjmbr-1414-431X20154316.xml | -> usar: 02 |
| 1414-431X-bjmbr-1414-431X20154355.xml | -> usar: 03 |
| 1414-431X-bjmbr-1414-431X20154363.xml | -> usar: 04 |
| 1414-431X-bjmbr-1414-431X20154438.xml | -> usar: 05 |
O campo order deverá apresentar o valor de order da seguinte forma:
3 primeiros dígitos do lote + 2 dígitos da quantidade do lote
Arquivo 1:
Arquivo 2:

etc.
Em [ahpdate] insira a mesma data que consta em [dateiso]. Após preencher todos os dados, clique em [Ok].
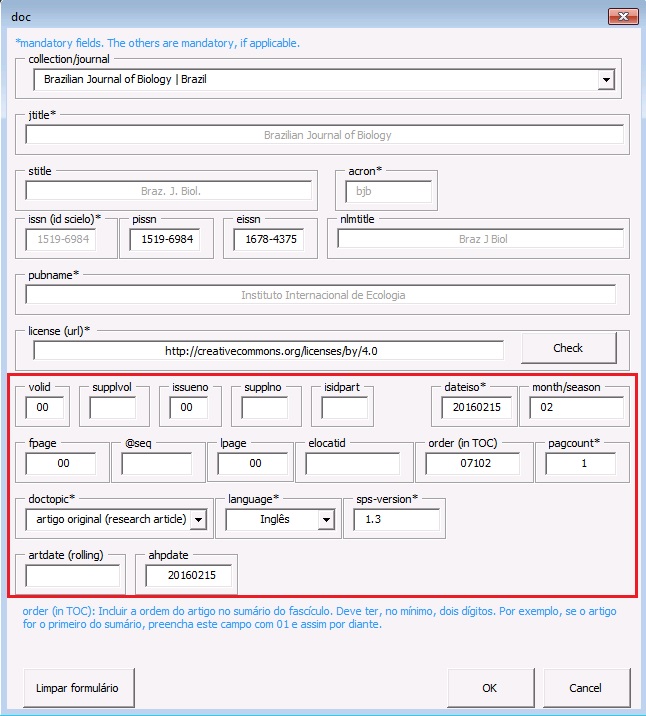
Note
Ao gerar o arquivo .xml o programa inserirá automaticamente o elemento <subject> com o valor “Articles”, conforme recomendado pelo SciELO PS.
Publicação Contínua (Rolling Pass)
O arquivo Rolling Pass deve apresentar formatação indicada no ítem Formatação do Arquivo.
Antes de preencher formulário para Rolling Pass, deve-se saber o formato de publicação adotado pelo periódico, os quais podem ser:
Volume e número

Volume

Número

O campo [order] é composto por uma ordem que determinará a seção dos arquivos e também a ordem de publicação. Portanto, primeiramente defina cada centena para uma seção, por exemplo:
- Editorials: 0100
- Original Articles: 0200
- Review Article: 0300
-
- Letter to the Author: 0400
- …
Os artigos deverão apresentar um ID único dentro de sua seção, portanto recomendamos que seja criado uma planilha como a que apresento nesse momento para acompanhar qual ID já foi utilizado. Exemplo:
Original Articles
- 1234-5678-rctb-v10-0239.xml 0100
- 1234-5678-rctb-v10-0328.xml 0101
-
- 1234-5678-rctb-v10-0356.xml 0102
- …
O identificador eletrônico do documento deve ser inserido no campo [elocatid].
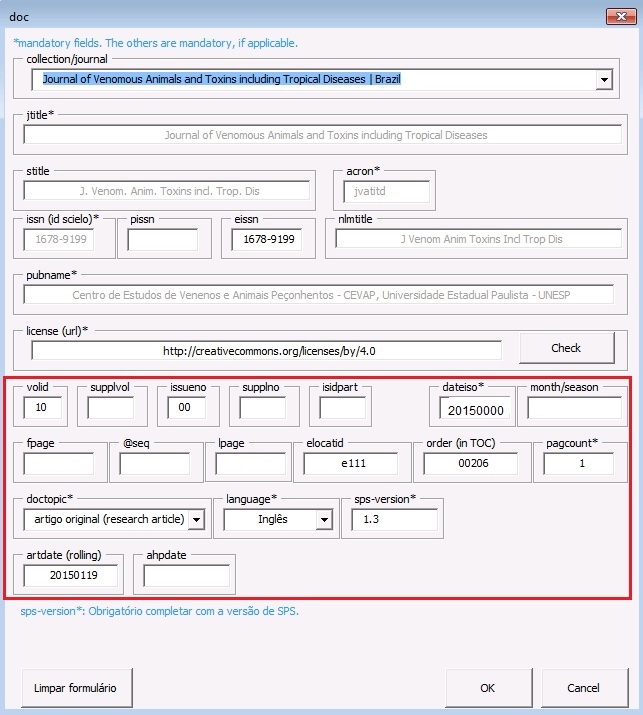
Note
Arquivos Rolling Pass apresentam elocation. Dessa forma, não deve-se preencher dados correspondentes a [fpage] e [lpage].
Resenha
As resenhas geralmente apresentam um dado a mais que os arquivos comuns: a referência bibliográfica do livro resenhado. A formatação do documento deve seguir a mesma orientação disponível em Formatação do Arquivo , incluindo-se referência bibliográfica do item resenhado antes do corpo do texto.
Verifique modelo abaixo:

Identificando Resenhas
Com o arquivo formatado, faça a identificação do documento pelo elemento [doc] e complete as informações. Em [doctopic] selecione o tipo “resenha (book review)”. A marcação dos dados iniciais é semelhante às orientações anteriores, excetuando-se a marcação da referência do livro resenhado.
Para marcar a referência do livro, selecione toda a referência e marque com o elemento [product]. Na janela aberta pelo programa, insera o tipo de referência bibliográfica em [prodtype]:
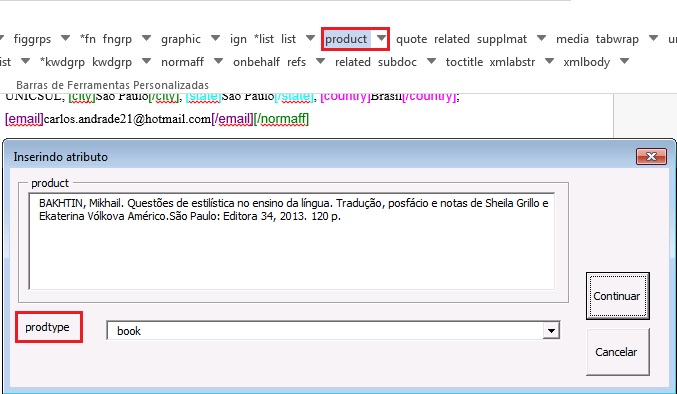
Na sequência, faça a marcação da referência usando os elementos apresentados no programa:
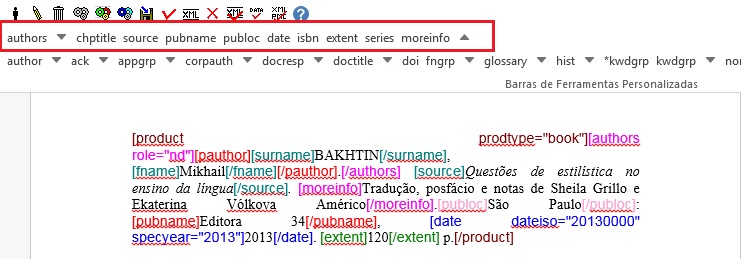
Finalize a marcação do arquivo e gere o XML.
Note
O programa não apresenta todos os elementos para marcação de referência bibliográfica no elemento [product]. Marque apenas os dados da referência com os elementos disponibilizados pelo programa.
Artigos em Formato Abreviado
O formato abreviado de marcação é utilizados somente nos casos de inserção de números retrospectivos na coleção do periódico. O arquivo no formato abreviado apresentará os dados básicos do documento (título do artigo, autores, afiliação, seção, resumo, palavras-chave e as referências completas). O corpo do texto de um arquivo no formato abreviado deve ser suprimido, substituindo o texto por dois parágrafos:
Texto completo disponível apenas em PDF.
Full text available only in PDF format.

Identificando Formato Abreviado
Com o arquivo formatado, faça a identificação do documento pelo elemento [doc] e complete as informações dos dados iniciais de acordo com os dados do arquivo.
A marcação de arquivos no formato abreviado não exige uma ordem de marcação entre referências bibliográficas e [xmlbody]. Faça a marcação de referências bibliográficas de acordo com a orientação do item _referencias:

A marcação dos parágrafos deve ser feita pelo elemento [xmlbody], selecionando os dois parágrafos e clicando em [xmlbody]:

Note
A única informação que não será marcada no arquivo de ‘Formato Abreviado’ será o corpo do texto, o qual estará disponível no PDF.
Press Releases
Por ser um texto de divulgação que visa dar mais visibilidade a um número ou artigo publicado em um periódico, o press realise não segue a mesma estrutura de um artigo científico. Dessa forma, não possue seção, número de DOI e, não há obrigatoriedade de inclusão de afiliação de autor. Uma vez aprovados, os Press Releases poderão ser formatados para uma marcação mais otimizada.
- 1ª linha do arquivo: correspondente ao número de DOI, deve ficar em branco;
- 2ª linha do arquivo: correspondente à seção do documento, deve ficar em branco;
- 3ª linha do arquivo: insira o título do Press Release;
- 4ª linha do arquivo: pular;
- 5ª linha do arquivo: Insira o nome do autor do Press Release;
- 6ª linha do arquivo: pular;
- 7ª linha do arquivo: inserir afiliação (caso não exista, deixar linha em branco);
- 8ª linha do arquivo: pular
- Insira o texto do arquivo Press Release, incluindo a assinatura do autor (assinatura se houver).
Identificando o Press Release
Com o arquivo formatado, faça a identificação do documento pelo elemento [doc] e considere os seguintes itens para arquivo PR:
- Nos campos ‘volid’ e ‘issue’ insira o número correspondente ao número que o Press Release está relacionado e em ‘isidpart’ insira a informação ‘pr’ qualificando o arquivo como um Press Release;
- Em [doctopic] selecione o tipo “Press Release”;
- Caso o Press Release esteja relacionado a um número, insira a informação “00001” no campo [order] para que o Press Release seja posicionado corretamente no sumário eletrônico; caso o Press Release seja de artigo, apenas insira a informação “01”.
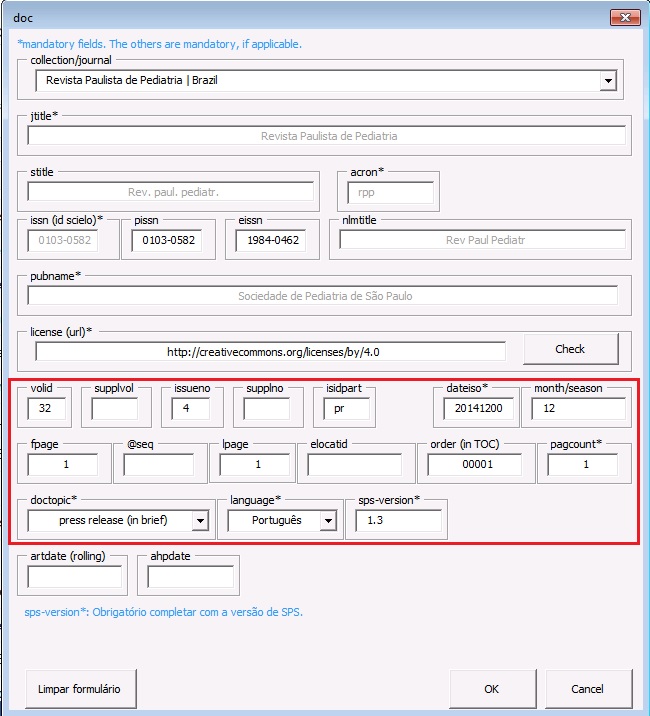
Ao clicar em [OK] o programa marcará automaticamente todos os dados iniciais, pulando número de DOI e os demais dados que o Press Release não apresenta.
Complete demais dados do Press Relase como: [xref] de autores, normalização de afiliações (esses dois últimos, se houver), corpo do texto com o elemento [xmlbody] e identificação de assinatura de autor com o elemento [sigblock].

Caso o Press Release esteja relacionado a artigo específico, será necessário relacioná-lo ao artigo em questão. Dessa forma, insira o cursor do mouse após o elemento [doc] e clique no elemento [related]. O programa abrirá uma janela onde deverá ser preenchidos os campos ‘reltp’ (tipo de relação) e o campo ‘pid-doi’. No campo ‘reltp’ selecione o valor ‘press-release’; já em ‘pid-doi’ insira o número de DOI do artigo relacionado.
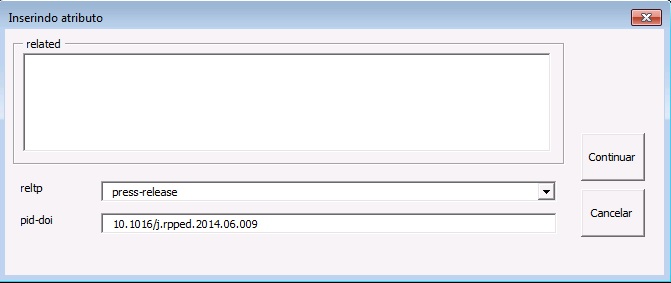
Note
A identificação pelo elemento [related] deve ser realizada apenas para Press Releases relacionado a um “artigo”.
Processos Manuais
O programa de marcação atende mais 80% das regras estabelecidas no SciELO Publishing Schema. Há alguns dados que devem ser marcados manualmente, seja no próprio programa Markup, seja diretamente no arquivo xml gerado pelo programa.
Afiliação com mais de uma instituição
O programa Markup não realiza marcação de afiliações com mais que uma instituição. Nesse caso, o dado será incluído diretamente no arquivo .xml. Abra o arquivo .xml em um editor de XML e inclua o elemento <aff> com um ID diferente do que já consta no documento:

Note
A afiliação incluída manualmente não deve apresentar <label> e <institution content-type=”original”>, já que seus dados para apresentação no site já estão disponíveis na afiliação marcada no programa.
Verifique a segunda instituição da afiliação original e copie para a afiliação nova fazendo a marcação do dado com o elemento <institution content-type=”orgname”> e <institution content-type=”normalized”>:

Caso essa instituição apresente divisões, faça a marcação do dado conforme as demais já feitas no documento. Em seguida, marque seu país correspondente com o elemento <country country=”xx”>:

O próximo passo será relacionar essa afiliação <aff id=”affx”> com o autor correspondente. Considerando que o autor não apresenta mais que um label, insira a tag <xref> fechada:
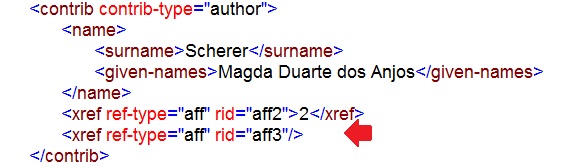
Salve o documento .xml e valide o arquivo.
Tipo de Mídia
O programa Markup faz também a identificação de mídias como:
- vídeos
- áudios
- filmes
- animações
Desde que seus arquivos estejam disponíveis na pasta “src” com o mesmo nome do arquivo .doc, acrescentado de hífen e o ID da mídia. Exemplo:
Artigo12-m1.wmv
A marcação da mídia no corpo do texto deve ser feita através do elemento [media]. Na janela aberta pelo programa, preencha os campos “id” e “href”. No campo “id” insira o prefixo “m” + o número de ordem da mídia. Exemplo: m1.
Já em “href” insira o nome da mídia com a extensão: “Artigo12-m1.wmv”.
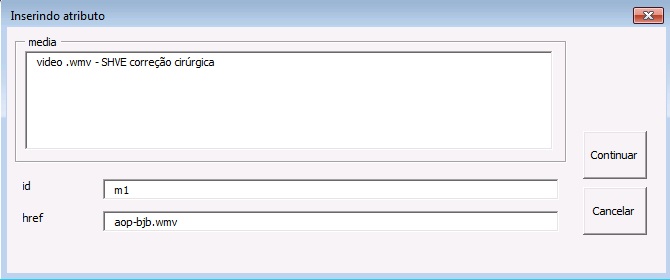
Feito isso gere o arquivo .xml.
Com o arquivo .xml gerado verifique se há erros e corrija, se necessário, os atributos que qualificam o tipo de mídia. O Programa apresenta os atributos:
- mime-subtype - especifica o tipo de mídia como “video” ou “application”.
- mimetype - especifica o formato da mídia.
É possível que o programa insira valores incorretos nos atributos mencionados acima. Exemplo:

Para corrigir, exclua o valor “x-ms-wmv” e insira apenas “wmv” que é o formato do vídeo. Caso o atributo @mimetype apresente valor diferente de “application” ou “video”, corrija o dado.
Identificação de sublistas
O programa Markup não faz a identificação de sublistas, portanto é necessário utilizar um editor de XML para ajustar os itens de sublista. Há dois métodos para a marcação manual de sublistas:
Método 1:
Ainda no programa Markup, selecione toda a lista e identifique com a tag [*list] e gere o arquivo .xml. Com o arquivo .xml gerado, encontre a lista e faça a seguinte alteração:
Primeiramente, encontre os itens de sublista:

Adicione o elemento <list> acima do primeiro item <list-item> da sublista:
Recorte o elemento </list-item> que consta acima da tag <list> da sublista:
Cole o elemento </list-item> recortado logo abaixo da tag </list> da sublista:
Caso a sublista apresente um marcador diferente do inserido na lista, é possível adicionar o atributo @list-type na tag <list> da sublista e inserir algum dos valores abaixo:
- order
- bullet
- alpha-lower
- alpha-upper
- roman-lower
- roman-upper
- simple
Método 2:
Caso a lista e sublista não tenham sido marcadas no programa Markup, é possível que ao gerar o arquivo .xml a lista tenha sido identificada como parágrafos. Portanto será necessário fazer a identificação manual da lista e da sublista.
Primeiramente, retire todos os parágrafos da lista e sublista e a envolva com o elemento <list> acrescentando o atributo @list-type= com o valor correspondente ao marcador da lista:

Agora insira o elemento <list-item> e <p> para cada item da lista:

Identifique os itens de sublista:
Adicione um elemento <list> acima do primeiro elemento <list-item> da sublista:
Recorte o elemento </list-item> que consta acima do elemento <list> da sublista:
Agora cole o elemento </list-item> recortado logo abaixo de </list> da sublista:
Legendas Traduzidas
O Programa Markup não faz a marcação de figuras ou tabelas com legendas traduzidas. Para fazer essa marcação é necessário utilizar um editor de XML. Verifique a marcação de legendas de tabelas e de figuras abaixo:
Tabelas
Abra o arquivo .xml em um editor de sua preferência e localize a tabela que apresenta a legenda traduzida.
Insira o elemento <table-wrap-group> envolvendo toda a tabela, desde <table-wrap>:

Apague o @id=”xx” de <table-wrap> e insira o atributo de idioma @xml:lang=”xx” com a sigla correspondente ao idioma principal da tabela. Em seguida, insira um @id único para o <table-wrap-group>:

Insira um novo elemento <table-wrap> com <label>, <caption> e <title> logo abaixo de <table-wrap-group> com o atributo de idioma @xml:lang=”xx” correspondente ao idioma da tradução. E insira a legenda traduzida em <title>:

Note
Para tabelas codificadas o processo é o mesmo.
Figuras
Abra o arquivo .xml em um editor de sua preferência e localize a figura que apresenta a legenda traduzida.
Insira o elemento <fig-group> envolvendo toda a figura, desde <fig>:

Apague o @id=”xx” de <fig> e insira o atributo de idioma @xml:lang=”xx” com a sigla correspondente ao idioma principal da figura. Em seguida, insira um @id único para o <fig-group>:

Insira um novo elemento <fig> com <label>, <caption> e <title> logo abaixo de <fig-group> com o atributo de idioma @xml:lang=”xx” correspondente ao idioma da tradução. E insira a legenda traduzida em <title>:

Autores sem label
Alguns autores não apresentam label em autor e em afiliação. Para marcar o dado, faça a marcação tradicional do autor no programa Markup e insira em afiliação o ID de cada autor. Após gerar o arquivo .xml do documento, abra-o em um editor de XML e insira a <xref> fechada de cada autor.

Gerando o Arquivo .xml
Após a identificação de todos os dados do documento .doc, o próximo passo é gerar o arquivo .xml.
Antes de qualquer coisa, salve o arquivo marcado clicando no botão “Markup: Salvar”:

Em seguida clique no botão “Markup: Gerar o XML”:

Relatórios
Ao gerar o arquivo .xml o programa Markup apresenta três relatórios: Relatório de Erros de Arquivos, Relatório de Estilos SciELO e Relatório de Erros de Conteúdo. Abaixo a função de cada relatório apresentado.
Relatório de Erros de Arquivos
Ao clicar em “Markup: Gerar o XML” o programa apresenta um Relatório com as informações das alterações feitas no documento.

O resultado disso, é um relatório que apresenta as ações do programa ao gerar o XML a partir do arquivo .doc. O programa altera o nome do arquivo que, em .doc, era apresentado como “12-Artigo.doc” para ISSN-acronimo-volume-numero-paginação.xml e as imagens são extraídas do documento já com a nomeação convertida para o padrão SciELO.
Relatório de Estilos SciELO
Em seguida clique no botão ao lado “Relatório de Estilos SciELO” e verifique se há algum erro no documento:

O programa apresentará um relatório parecido com o que segue abaixo:

Veja que o relatório de erros não apresenta nenhum erro. Isso porque o xml gerado está de acordo com a estrutura de estilos requerida.
Relatório de Erros de Conteúdo
Feita a verificação no Relatório de Estilos SciELO, o próximo passo é gerar o relatório de erros de dados/conteúdo.
Esse relatório é exatamente o mesmo que o programa Package Maker gera. Portanto, para verificar o manual de uso para validação e verificação dos erros apresentados, vá para o projeto Package Maker e confira as funcionalidades dessa ferramenta.
Pastas Geradas
Ao gerar o arquivo .xml o programa Markup cria 6 pastas no mesmo nível que “src” e “scielo_markup”, conforme segue:
pasta erros:
Nessa pasta há o relatório de erros de cada um dos arquivos .xml. O arquivo final .rep apresenta os possíveis erros de estilo e o final .contents de conteúdo. São os mesmos relatórios apresentados no programa de marcação.
pmc_package:
Para revistas que apresentam o título abreviado NLM, o programa retira os elementos de especificação SciELO e mantém apenas os elementos necessários para envio ao PMC. Os elementos que são retirados do documento XML para envio ao PMC são: detalhamento em afiliação, informação de financiamento em <funding-group> e <mixed-citation>.
pmc_package_zips:
Ao validar o pacote pmc_package o programa, automaticamente, zipa a pasta que está pronta para envio.
scielo_package:
No momento da validação do pacote XML o programa verifica as entidades (numéricas ou alfa-numéricas) que existem no documento e, automaticamente, converte para o caractere correspondente, evitando futuros problemas de entidades. O ideal é utilizar os arquivos .xml validados nessa pasta em vez de utilizar os xmls do pacote.
scielo_package_zips:
Ao validar o pacote scielo_package o programa, automaticamente, zipa a pasta já com a nomeação padrão SciELO que está pronta para envio.
work:
é uma pasta de arquivos temporários usadas para a geração do resultado. Ela pode ser apagada se desejado, mas também pode ser usada para fins de suporte.
Essa estrutura de pastas é a mesma apresentada se o usuário utilizar o programa Package Maker. Para verificar os relatórios apresentados, basta entrar na pasta “errors” e abrir o documento com extensão: “.contents.html”.
Como validar o pacote XML SPS
Package Maker - Como usar?
Para utilizar o programa Package Maker clique no meu Iniciar do Windows, procure a pasta do Programa Markup que foi istalado em sua máquina e com o mouse verifique os itens disponíveis na pasta. Clique no botão XML Package Maker
Agora clique no botão “Choose Folder” para escolher a pasta que contém os arquivos que serão validados
E clique em XML Package Maker.
Resultados
- Para arquivos XML SciELO (verifique a pasta scielo_package e/ou scielo_package_zips)
- Para arquivos XML PMC (verifique a pasta pmc_package)
- Para Relatório de arquivos (verifique a pasta errors)
A pasta que é gerada pelo XPM “ISSN-acronimo-volume-numero_xml_package_maker_result” estará disponível no mesmo nível da pasta que foi utilizada para gerar o pacote:
Relatórios
Depois de validar e gerar os pacotes os relatórios serão disponibilizados automaticamente em um Web Browser.
Relatório Resumido
Estatísticas de Validação
É apresentado o total de Erros fatais (Fatal Errors), erros (Errors), e alertas (Warnings), encontrados em todo o pacote.
- FATAL ERRORS
- Representa os erros relacionados aos indicadores bibliométricos.
- ERRORS
- Representa outros tipos de erros.
- WARNINGS
- Representa algo que precisa de mais atenção.
Relatório Detalhado
Relatório Detalhado - Validações do Pacote
Primeiro de tudo O XPM valida alguns dados do pacote:
- Elementos que apresentam o mesmo valor em todos os arquivos XML, tais como:
- journal-title
- journal id NLM
- journal ISSN
- publisher name
- issue label
- issue pub date
- Elementos que apresentam um valor único em cada arquivo XML, tais como:
- doi
- elocation-id, if applicable
- fpage and fpage/@seq
- order (used to generated article PID)
Exemplo de Erros Fatais (Fatal Error) por apresentar valor diferente para o elemento <publisher-name>
Exemplo de Erros Fatais (Fatal Error) por apresentar valores diferentes em <pub-date>
Exemplo de Erros Fatais (Fatal Error) pois é requerido um valor único
Relatório Detalhado - Validação do Documento
O documento é apresentado em uma Tabela.
As colunas ‘order’, ‘aop pid’, ‘toc section’, ‘@article-type’ estão destacadas, pois contém dados importantes.
A coluna reports possui botões para abrir/fechar o relatório detalhado de cada documento.
Cada linha possui um dado do documento:
Relatório Detalhado - Validações
Clique em **Validação de Conteúdo” para verificar os problemas apresentados. O relatório detalhado é apresentado abaixo da linha.
Arquivos/Pastas
Apresenta os Arquivos e Pastas que foram gerados e validados.
Visão Geral do Pacote
Visão Geral do Pacote - idiomas
Apresenta os elementos que contém o atributo de idioma @xml:lang.
Visão Geral do Pacote - dados
Apresenta os dados encontrados no documento: publicação e histórico. Apresenta o tempo esperado entre: data de recebido e aceito, aceito e publicado, aceito e a data atual.
Visão Geral do Pacote - afiliações
Visão Geral do Pacote - Referências
Relatórios Fonte
Perguntas Frequentes Sobre a Adoção de XML
SPS
1. Onde encontro as apresentações das reuniões sobre a produção de XML e o “Processo de Adoção do novo Sistema de Marcação de texto completo”?
- As apresentações de todas as reuniões realizadas desde 2012, sobre o “Processo de Adoção do novo Sistema de Marcação de texto completo do SciELO” estão disponíveis no site SciELO Eventos:
- <http://eventos.scielo.org/>
2. Como podemos ter mais informações sobre o XML?
Nas reuniões realizadas com editores de periódicos SciELO foram realizadas apresentações e fornecidos esclarecimentos sobre as principais características do XML (eXtensible Markup Language). As apresentações estão disponíveis em:
Além das apresentações em reuniões, foi publicado um post no blog SciELO em Perspectiva esclarecendo as principais razões da adoção dessa linguagem de marcação. Consulte em:
<http://blog.scielo.org/blog/2014/04/04/xml-porque/#.U1j4tT95iig>
3. Quais as características do XML a ser enviado ao SciELO?
O arquivo XML que o SciELO necessita deve estar em conformidade com o SciELO Publishing Schema (SciELO PS). Para um maior entendimento sobre o SciELO PS, consulte a documentação detalhada disponível em:
<http://docs.scielo.org/projects/scielo-publishing-schema/>
4 . Como conheço os elementos adotados pelo XML-SciELO?
O guia de uso dos elementos e atributos do SciELO Publishing Schema descreve o estilo de marcação adotado pelo projeto SciELO para a submissão de documentos no formato XML. Essa documentação é composta pela DTD JATS 1.0 + especificações PMC + Estilo SciELO, que são regras que especializam aspectos da especificação. Verificar em:
<http://docs.scielo.org/projects/scielo-publishing-schema/>
Processo Editorial
5. Com esse novo processo de produção da revista em XML, a diagramação do periódico impresso sofrerá alterações?
A diagramação do impresso poderá continuar da mesma forma como é realizada atualmente.
6 . Posso usar os arquivos XML na página da minha revista?
Sim. O editor pode disponibilizar o arquivo xml não só na página SciELO, mas também em seu próprio site.
Tecnologia / Ferramentas
7. Existe a possibilidade de gerar o arquivo XML SciELO PS a partir do InDesign?
Ainda não temos mecanismos eficaz para produzir arquivos XML com a estrutura requerida a partir do InDesign. No momento a SciELO disponibiliza um programa de marcação que possibilita identificar todas as informações de um arquivo em .doc e/ou em .html. Verificar em:
<http://docs.scielo.org/projects/scielo-pc-programs/en/latest/>
8. O SciELO oferece algum software que auxilie os editores a produzir os artigos em XML?
O SciELO desenvolveu algumas ferramentas para validação do XML segundo SciELO Publishing Schema. Caso o editor não possua nenhuma ferramenta para a geração de XML, poderá usar os programas de marcação e produção do XML, bem como, ferramentas de validação utilizadas no processo de produção e publicação segundo SciELO PS (ver item 10. Existe algum programa onde eu possa verificar se meu arquivo XML está compatível com o solicitado pelo SciELO?). O programa de Marcação, desenvolvido por SciELO, funciona apenas em Windows, ou seja, não há a possibilidade de utilizar o programa com diferentes sistemas operacionais como Linux, por exemplo. Ele é um suplemento do Word, o qual encontra-se disponível em:
<http://docs.scielo.org/projects/scielo-pc-programs/en/latest/download.html>
Mais informação sobre os programas e ferramentas utilizadas podem ser encontradas em:
<http://docs.scielo.org/projects/scielo-pc-programs/en/latest/>
9. Há algum manual de instruções para a utilização desse programa?
Sim, verifique a documentação online de instrução de uso do programa Markup disponibilizada em:
<http://docs.scielo.org/projects/scielo-pc-programs/en/latest/pt_how_to_generate_xml.html>
10. Existe algum programa onde eu possa verificar se meu arquivo XML está compatível com o solicitado pelo SciELO?
Sim. O SciELO desenvolveu duas ferramentas que ajudam na validação do arquivo .xml. Veja abaixo os programas disponíveis:
Package Maker: este programa está disponível no FTP SciELO produtos (xpm-4.0.090.EXE). Para instalar o programa consultar o link [1]. Este programa apresenta um relatório de erros informando possíveis problemas no XML, renomeia arquivos de acordo com o padrão SciELO PS e separa em pacotes. Verifique no link [2] o manual de uso do validador.
StyleChecker: é uma ferramenta web que fornece relatório detalhado sobre a conformidade de um dado XML em relação à especificação SciELO PS [3].
[1] <http://docs.scielo.org/projects/scielo-pc-programs/en/latest/installation.html#installation>
[2] <http://docs.scielo.org/projects/scielo-pc-programs/en/latest/xml_package_maker.html>
[3] <http://manager.scielo.org/tools/validators/stylechecker/>
11 . SciELO disponibiliza modelos de arquivos XML compatíveis com as especificações de SciELO PS?
Não temos estes modelos disponíveis.
Produção de XML por terceiros
12. Existem empresas que prestam serviços de produção de XML conforme o padrão requisitado por SciELO? Como posso localizar essas empresas?
Sim. Existem algumas empresas parceiras que são certificadas pelo SciELO e que prestam serviços de produção de arquivos XML segundo o SciELO Publishing Schema. Disponibilizamos o contato dessas empresas em: <http://www.scielo.org/php/level.php?lang=pt&component=56&item=58>
Publicação no SciELO Brasil
13 . Como é o processo de certificação SciELO para a produção de XML?
As empresas que se propõem a prestar serviços de marcação de textos em XML segundo o SciELO PS têm que submeter o material produzido a uma avaliação inicial. Entretanto, a amostra enviada deve seguir o padrão SciELO e todos os arquivos devem ter sido validados pelas ferramentas Package Maker e StyleChecker. Para obter mais informações sobre a certificação SciELO, verifique os requisitos disponíveis no site SciELO.org:
<http://www.scielo.org/php/level.php?lang=pt&component=56&item=59>
14 . SciELO poderá receber arquivos XML de prestadores que não são parceiros SciELO?
As empresas que decidem prestar serviços de marcação de textos em XML segundo o SciELO Publishing Schema, devem nos enviar um pacote de amostra com pelo menos 5 arquivos para uma avaliação inicial. Uma vez aprovados, a empresa será avaliada periodicamente, a cada seis meses. Para obter mais informações sobre a certificação SciELO, consulte o link disponível abaixo:
<http://www.scielo.org/php/level.php?lang=pt&component=56&item=59>
Note
As empresas serão aprovadas somente se os arquivos .xml forem validados pelas ferramentas StyleChecker e Package Maker. Caso os arquivos não sejam validados por essas ferramentas, as empresas deverão aguardar 6 meses para fazer um novo envio do pacote .xml. Essa validação é de extrema importância e é um procedimento contínuo. Portanto, mesmo com a certificação SciELO, a validação deverá ser feita a cada envio. Entretanto, antes de enviar o pacote para o SciELO envie um e-mail para scielo@scielo.org e para producao@scielo.org com cópia para conversao@scielo.org informando que foi produzido o primeiro pacote .xml e que ainda não possuem certificação.
15 . Produzi meu arquivo XML, posso enviar para SciELO verificar?
Utilize primeiramente as ferramentas de validação (ver item 10. Existe algum programa onde eu possa verificar se meu arquivo XML está compatível com o solicitado pelo SciELO?). Caso não consiga identificar e/ou corrigir os problemas apresentados, você deve consultar ou enviar suas dúvidas a lista de discussão scielo-xml@googlegroups.com, a qual será respondida em até 72 horas.
16. Qual o prazo para o meu número estar disponível no site SciELO?
O prazo para a publicação no site é de 10 a 15 dias, considerando o último e-mail de confirmação de recebimento do pacote de dados. Esse prazo leva em consideração o tempo de verificação do material recebido, correções eventualmente necessárias e tempo de processamento.
How to update the local web site
The publishing workflow uses SGML Files and/or XML Files as input and generates the local website according to SciELOWeb site.
Data from SGML and XML files can be published on the same SciELO Web site.
title and issue databases
issue and title databases must be updated in serial folder.
This databases are managed by Title Manager.
If you have replaced Title Manager by SciELO Manager, you have to run specifics programs to update (Delorean) these databases.
Other option is having updated copies of these databases.
SGML files and/or XML files
In serial folder, you must have the folders/files resulting of SGML Markup workflow and/or XML Markup workflow.
For SGML, the input files must be in:
- serial/<acron>/<volnum>/markup
- serial/<acron>/<volnum>/body
For XML, the input files must be in:
- ??/<acron>/<volnum>/markup_xml/scielo_package
XML Converter/ Converter
Use Converter to generate the base folder from the SGML files.
Use XML Converter to generate the base folder from the XML files.
GeraPadrao
Run GeraPadrao.bat script to generate de local website.
Support
Before You Ask
Try to find an answer by reading the manual. Give us feedback which parts is not clear enough. Try to find an answer by searching the maillist archives.
Questions about SciELO PC Programs (Markup, Title Manager, Converter, etc)
http://groups.google.com/group/scielo-discuss
It is the forum to discuss questions and make suggestions related to the programs or other subjects related to SciELO Methodology.
How to subscribe
Send an e-mail to: scielo-discuss+subscribe@googlegroups.com
How to unsubscribe
Send an e-mail to: scielo-discuss+unsubscribe@googlegroups.com
Questions about SciELO XML / SciELO Publishing Schema
http://groups.google.com/group/scielo-xml
It is the forum to discuss questions and make suggestions related to SciELO XML / SciELO Publishing Schema.
How to subscribe
Send an e-mail to: scielo-xml+subscribe@googlegroups.com
How to unsubscribe
Send an e-mail to: scielo-xml+unsubscribe@googlegroups.com
Perguntas Frequentes Sobre a Adoção de XML
SPS
1. Onde encontro as apresentações das reuniões sobre a produção de XML e o “Processo de Adoção do novo Sistema de Marcação de texto completo”?
- As apresentações de todas as reuniões realizadas desde 2012, sobre o “Processo de Adoção do novo Sistema de Marcação de texto completo do SciELO” estão disponíveis no site SciELO Eventos:
- <http://eventos.scielo.org/>
2. Como podemos ter mais informações sobre o XML?
Nas reuniões realizadas com editores de periódicos SciELO foram realizadas apresentações e fornecidos esclarecimentos sobre as principais características do XML (eXtensible Markup Language). As apresentações estão disponíveis em:
Além das apresentações em reuniões, foi publicado um post no blog SciELO em Perspectiva esclarecendo as principais razões da adoção dessa linguagem de marcação. Consulte em:
<http://blog.scielo.org/blog/2014/04/04/xml-porque/#.U1j4tT95iig>
3. Quais as características do XML a ser enviado ao SciELO?
O arquivo XML que o SciELO necessita deve estar em conformidade com o SciELO Publishing Schema (SciELO PS). Para um maior entendimento sobre o SciELO PS, consulte a documentação detalhada disponível em:
<http://docs.scielo.org/projects/scielo-publishing-schema/>
4 . Como conheço os elementos adotados pelo XML-SciELO?
O guia de uso dos elementos e atributos do SciELO Publishing Schema descreve o estilo de marcação adotado pelo projeto SciELO para a submissão de documentos no formato XML. Essa documentação é composta pela DTD JATS 1.0 + especificações PMC + Estilo SciELO, que são regras que especializam aspectos da especificação. Verificar em:
<http://docs.scielo.org/projects/scielo-publishing-schema/>
Processo Editorial
5. Com esse novo processo de produção da revista em XML, a diagramação do periódico impresso sofrerá alterações?
A diagramação do impresso poderá continuar da mesma forma como é realizada atualmente.
6 . Posso usar os arquivos XML na página da minha revista?
Sim. O editor pode disponibilizar o arquivo xml não só na página SciELO, mas também em seu próprio site.
Tecnologia / Ferramentas
7. Existe a possibilidade de gerar o arquivo XML SciELO PS a partir do InDesign?
Ainda não temos mecanismos eficaz para produzir arquivos XML com a estrutura requerida a partir do InDesign. No momento a SciELO disponibiliza um programa de marcação que possibilita identificar todas as informações de um arquivo em .doc e/ou em .html. Verificar em:
<http://docs.scielo.org/projects/scielo-pc-programs/en/latest/>
8. O SciELO oferece algum software que auxilie os editores a produzir os artigos em XML?
O SciELO desenvolveu algumas ferramentas para validação do XML segundo SciELO Publishing Schema. Caso o editor não possua nenhuma ferramenta para a geração de XML, poderá usar os programas de marcação e produção do XML, bem como, ferramentas de validação utilizadas no processo de produção e publicação segundo SciELO PS (ver item 10. Existe algum programa onde eu possa verificar se meu arquivo XML está compatível com o solicitado pelo SciELO?). O programa de Marcação, desenvolvido por SciELO, funciona apenas em Windows, ou seja, não há a possibilidade de utilizar o programa com diferentes sistemas operacionais como Linux, por exemplo. Ele é um suplemento do Word, o qual encontra-se disponível em:
<http://docs.scielo.org/projects/scielo-pc-programs/en/latest/download.html>
Mais informação sobre os programas e ferramentas utilizadas podem ser encontradas em:
<http://docs.scielo.org/projects/scielo-pc-programs/en/latest/>
9. Há algum manual de instruções para a utilização desse programa?
Sim, verifique a documentação online de instrução de uso do programa Markup disponibilizada em:
<http://docs.scielo.org/projects/scielo-pc-programs/en/latest/pt_how_to_generate_xml.html>
10. Existe algum programa onde eu possa verificar se meu arquivo XML está compatível com o solicitado pelo SciELO?
Sim. O SciELO desenvolveu duas ferramentas que ajudam na validação do arquivo .xml. Veja abaixo os programas disponíveis:
Package Maker: este programa está disponível no FTP SciELO produtos (xpm-4.0.090.EXE). Para instalar o programa consultar o link [1]. Este programa apresenta um relatório de erros informando possíveis problemas no XML, renomeia arquivos de acordo com o padrão SciELO PS e separa em pacotes. Verifique no link [2] o manual de uso do validador.
StyleChecker: é uma ferramenta web que fornece relatório detalhado sobre a conformidade de um dado XML em relação à especificação SciELO PS [3].
[1] <http://docs.scielo.org/projects/scielo-pc-programs/en/latest/installation.html#installation>
[2] <http://docs.scielo.org/projects/scielo-pc-programs/en/latest/xml_package_maker.html>
[3] <http://manager.scielo.org/tools/validators/stylechecker/>
11 . SciELO disponibiliza modelos de arquivos XML compatíveis com as especificações de SciELO PS?
Não temos estes modelos disponíveis.
Produção de XML por terceiros
12. Existem empresas que prestam serviços de produção de XML conforme o padrão requisitado por SciELO? Como posso localizar essas empresas?
Sim. Existem algumas empresas parceiras que são certificadas pelo SciELO e que prestam serviços de produção de arquivos XML segundo o SciELO Publishing Schema. Disponibilizamos o contato dessas empresas em: <http://www.scielo.org/php/level.php?lang=pt&component=56&item=58>
Publicação no SciELO Brasil
13 . Como é o processo de certificação SciELO para a produção de XML?
As empresas que se propõem a prestar serviços de marcação de textos em XML segundo o SciELO PS têm que submeter o material produzido a uma avaliação inicial. Entretanto, a amostra enviada deve seguir o padrão SciELO e todos os arquivos devem ter sido validados pelas ferramentas Package Maker e StyleChecker. Para obter mais informações sobre a certificação SciELO, verifique os requisitos disponíveis no site SciELO.org:
<http://www.scielo.org/php/level.php?lang=pt&component=56&item=59>
14 . SciELO poderá receber arquivos XML de prestadores que não são parceiros SciELO?
As empresas que decidem prestar serviços de marcação de textos em XML segundo o SciELO Publishing Schema, devem nos enviar um pacote de amostra com pelo menos 5 arquivos para uma avaliação inicial. Uma vez aprovados, a empresa será avaliada periodicamente, a cada seis meses. Para obter mais informações sobre a certificação SciELO, consulte o link disponível abaixo:
<http://www.scielo.org/php/level.php?lang=pt&component=56&item=59>
Note
As empresas serão aprovadas somente se os arquivos .xml forem validados pelas ferramentas StyleChecker e Package Maker. Caso os arquivos não sejam validados por essas ferramentas, as empresas deverão aguardar 6 meses para fazer um novo envio do pacote .xml. Essa validação é de extrema importância e é um procedimento contínuo. Portanto, mesmo com a certificação SciELO, a validação deverá ser feita a cada envio. Entretanto, antes de enviar o pacote para o SciELO envie um e-mail para scielo@scielo.org e para producao@scielo.org com cópia para conversao@scielo.org informando que foi produzido o primeiro pacote .xml e que ainda não possuem certificação.
15 . Produzi meu arquivo XML, posso enviar para SciELO verificar?
Utilize primeiramente as ferramentas de validação (ver item 10. Existe algum programa onde eu possa verificar se meu arquivo XML está compatível com o solicitado pelo SciELO?). Caso não consiga identificar e/ou corrigir os problemas apresentados, você deve consultar ou enviar suas dúvidas a lista de discussão scielo-xml@googlegroups.com, a qual será respondida em até 72 horas.
16. Qual o prazo para o meu número estar disponível no site SciELO?
O prazo para a publicação no site é de 10 a 15 dias, considerando o último e-mail de confirmação de recebimento do pacote de dados. Esse prazo leva em consideração o tempo de verificação do material recebido, correções eventualmente necessárias e tempo de processamento.
Glossary
- Local server
- SciELO collection or instance
- Types of issues
- Sequential number
- Folders structure
- Programs folder
- Data folder
Local server
It’s a Windows computer where the PC Programs and SciELO website (local site) run.
SciELO collection or instance
SciELO Collection or instance is a website generated using SciELO Methodology, including the ones which do not use SciELO in their website name.
Examples of collections or instances: SciELO Brazil, SciELO Chile, SciELO Salud Pública, Rev@Enf, etc.
Types of issues
- regular or supplement
- number formed by articles and texts
- ahead
- manuscripts that were approved by editorial board but they are not in a definitive issue. There is an ahead number by year.
- review/provisional
- number whose purpose is to group accepted articles which are still under review, leaving only their metadata published. There is a review number by year. Note: at the site the name adopted is provisional
- pr (press release)
- number whose purpose is to group the press releases texts of a number or article. There is a pr number by issue.
Sequential number
The sequential number is a number formed by year (YYYY), followed by a number that gives the issue’s order within a year.
This number has two purposes:
- order of the issue within a year in the “all issues” page of the website
- forming PID.
Attention
DO NOT MODIFY THIS ITEM if the issue has already been published on the website.
By convention, the sequential number is:
- ahead = 50
- review/provisional = 75
- pr = from 100
Example:
| v.40 n.1 | 20091 |
| v.40 n.2 | 20092 |
| v.40 suppl. | 20093 |
| v.40 suppl.2 | 20094 |
| v.40 n.2 suppl.1 | 20095 |
| ahead | 200950 |
| review | 200975 |
| v.40 n.1 pr | 2009100 |
Folders Structure
SciELO PC Programs package has the folders:
- bin and xml_scielo, for programs
- serial, for data
You can install them in the same or different folders. BUT by CONVENTION, we recommend C:\scielo\bin and c:\scielo\serial.
Examples of the same folder:
- c:\scielo\bin… and c:\scielo\serial
- d:\scielo_v4.0\bin and d:\scielo_v4.0\serial
Examples of different folders:
- c:\scielo\bin… e d:\scieloserial
- d:\scielo-programs\bin… and d:\scielo-dataserial
Programs folder
It contains the programs. E.g.: \scielo\bin
Data folder
e.g.: \scielo\serial
In this folder are all data, all the databases.
- title: it contains data records related to the journal
- section: it contains data records of sections of the table of contents
- issue: it contains the records of journal’s issues
- code: it contains tables of codes/labels
- PubMed: is used in order to archive the XML files sent to PubMed
- ISI: is used in order to archive the XML files sent to ISI
- several Journal’s folder: which contains the issues of the journal
Journal’s folder
e.g.: \scielo\serial\<acronym>
It contains several folders, each one for each issue of the journal.
Issue folder
- It contains folders like:
-
- markup: articles and text files, with markup
- body: articles and text files, original, no markup
- pdf: articles and texts in PDF format
- img: image files extracted from the PDF files
- base: the databases generated by Converter from the files of markup and body folders.
- There are rules to name theses folders:
-
-
- Folders for regular numbers and supplements: v, followed by the volume number, s, followed by the supplement to volume, n, followed by the number issue, s, followed by the supplement number
-
- Examples:
-
- v31n1 (volume 31, number 1)
- v31n1s1 (volume 31, number 1, supplement 1)
- v31n1s0 (volume 31, number 1, supplement)
- v31s0 (volume 31, supplement)
- v31s1 (volume 31, supplement 1)
- v31nspe (volume 31, special number)
- v31n3a (volume 31, number 3A)
-
- Review / Provisional’s and ahead’s folder: publication’s year, n, followed by the word review or ahead
-
- Examples:
-
- 2009nahead
- 2010nreview
-
- Ex-review/provisional’s and ex-ahead’s folders: ex-, followed by publication’s year, n followed by the number. NOTE: Converter creates these folders, because it is only way to control data files which were review/provisional and/or ahead once.
-
- Examples:
-
- ex-2009nahead
- ex-2010nreview
-
- Press releases’ folders: it follows the same rules of regular numbers and supplements, review / provisional and ahead, adding pr at the end of the file name.
-
- Examples:
-
- v31n1pr (press release of volume 31, number 1)
- v31n1s1pr (press release of volume 31, number 1, supplement 1)
- v31n1s0pr (press release of volume 31, number 1, supplement)
- v31s0pr (press release of volume 31, supplement)
- v31s1pr (press release of volume 31, supplement 1)
- v31nspepr (press release of volume 31, special number)
- v31n3apr (press release of volume 31, number 3A)
-
List of codes
acquisition priority
| 1 | Indispensable |
| 2 | Dispensable because exists in the Country |
| 3 | Dispensable because exists in the Region |
alphabet of title
| A | Basic Roman |
| B | Extensive Roman |
| C | Cirillic |
| D | Japanese |
| E | Chinese |
| K | Korean |
| O | Another alphabet |
article status
| 1 | Available |
authidtp
| orcid | orcid |
| lattes | lattes |
blcktype
| ack | Acknowledge |
| nd | undefined |
corresp
| n | no |
| y | yes |
count
| 0 | 0 |
country
| AD | Andorra |
| AE | United Arab Emirates |
| AF | Afghanistan |
| AG | Antigua |
| AL | Albania |
| AN | Netherlands Antilles |
| AO | Angola |
| AQ | Antarctica |
| AR | Argentina |
| AS | American Samoa |
| AT | Austria |
| AU | Australia |
| BB | Barbados |
| BD | Bangladesh |
| BE | Belgium |
| BG | Bulgaria |
| BH | Bahrain |
| BI | Burundi |
| BM | Bermuda |
| BN | Brunei |
| BO | Bolivia |
| BR | Brazil |
| BS | Bahamas |
| BT | Bhutan |
| BU | Burma |
| BV | Bouvet Island |
| BW | Botswana |
| BY | Byelorussian RSS |
| BZ | Belize |
| CA | Canada |
| CC | Islas Cocos (Keeling) |
| CF | Central African Rep. |
| CG | Congo |
| CH | Switzerland |
| CI | Ivory Coast |
| CK | Islas Cook |
| CL | Chile |
| CM | Cameroon |
| CN | China |
| CO | Colombia |
| CR | Costa Rica |
| CS | Czechoslovakia |
| CT | Islas Canton y Enderbury |
| CU | Cuba |
| CV | Cape Verde |
| CX | Isla de Navidad |
| CY | Cyprus |
| DD | German Democratic Republic |
| DE | Germany, Federal Republic |
| DK | Denmark |
| DM | Dominica |
| DO | Dominican Republic |
| DZ | Algeria |
| EC | Ecuador |
| EG | Egypt |
| EH | Western Sahara |
| ES | Spain |
| ET | Ethiopia |
| FI | Filand |
| FJ | Fiji |
| FK | Falkland Islands(Malvinas) |
| FO | Islas Feroe |
| FR | France |
| GA | Gabon |
| GB | United Kingdom |
| GC | Guinea Ecuatorial |
| GD | Grenada |
| GF | French Guiana |
| GH | Ghana |
| GI | Gibraltar |
| GL | Greenland |
| GN | Guinea |
| GP | Guadeloupe |
| GR | Greece |
| GT | Guatemala |
| GU | Guam |
| GW | Guinea-Bissau |
| GY | Guyana |
| HK | Hong Kong |
| HM | Islas Heard y Mc Donald |
| HN | Honduras |
| HT | Haiti |
| HU | Hungary |
| HV | Upper Volta |
| ID | Indonesia |
| IE | Ireland |
| IL | Israel |
| IN | India |
| IQ | Iraq |
| IR | Iran |
| IS | Iceland |
| IT | Italy |
| JM | Jamaica |
| JO | Jordan |
| JP | Japan |
| JT | Isla Johnston |
| KD | Korea, Democratic People’s |
| KE | Kenya |
| KH | Kampuchea Democrática |
| KM | Kamoras Islands |
| KN | San Cristóbal-Nieves-Anguila |
| KP | Korea, Democratic People’s |
| KR | Korea, Republic of |
| KW | Kuwait |
| KY | Kayman Islands |
| LA | Republic |
| LB | Lebanon |
| LC | Saint Lucia |
| LD | Lao People’s Democratic |
| LI | Liechtenstein |
| LK | Sri Lanka |
| LR | Liberia |
| LS | Lesotho |
| LU | Luxembourg |
| LY | Libyan |
| MA | Morocco |
| MC | Monaco |
| MG | Madagascar |
| MI | Islas Midway |
| ML | Mali |
| MN | Mongolia |
| MO | Macau |
| MQ | Martinique |
| MR | Mauritania |
| MS | Montserrat |
| MT | Malta |
| MU | Mauritius |
| MV | Maldivas |
| MW | Malawi |
| MX | Mexico |
| MY | Malaysia |
| MZ | Mozambique |
| NA | Namibia |
| NC | New Caledonia |
| NE | Niger |
| NF | Norfolk Island |
| NG | Nigeria |
| NH | Nuevas Hébridas |
| NI | Nicaragua |
| NL | Netherlands |
| NO | Norway |
| NP | Nepal |
| NQ | Dronning Maud Land |
| NR | Nauru |
| NU | Isla Niue |
| NZ | New Zealand |
| OM | Oman |
| PA | Panama |
| PC | Pacific Islands |
| PE | Peru |
| PF | French Polynesia |
| PG | Papua New Guinea |
| PH | Philippines |
| PK | Pakistan |
| PL | Poland |
| PM |
|
| PN | Islas Pitcairn |
| PR | Puerto Rico |
| PT | Portugal |
| PU | Islands Miscellaneous |
| PY | Paraguay |
| QA | Qatar |
| RE | Réunion |
| RO | Romania |
| RW | Rwanda |
| SA | Saudi Arabia |
| SB | Islas Salomón Británico |
| SC | Seichelles |
| SD | Sudan |
| SE | Sweden |
| SG | Singapur |
| SH | St. Helena |
| SJ | Islas Svalbard y Jan Mayen |
| SK | Sikkim |
| SL | Sierra Leone |
| SM | San Marino |
| SN | Senegal |
| SO | Somalia |
| SR | Suriname |
| ST | Sao Tome and Principe |
| SU | URSS |
| SV | El Salvador |
| SY | Syrian Arab Republic |
| SZ | Swaziland |
| TC | Turks and Caicos Islands |
| TD | Chad |
| TG | Togo |
| TH | Thailand |
| TK | Islas Tokelau |
| TN | Tunisia |
| TO | Tonga |
| TR | Turkey |
| TT | Trinidad and Tobago |
| TW | Taiwan |
| TZ | Tanzania |
| UA | Ukrainian RSS |
| UG | Uganda |
| UP | United States Pacific |
| US | United States |
| UY | Uruguay |
| VA | Vatican City State |
| VC | Saint Vincent |
| VE | Venezuela |
| VG | British Virgin Islands |
| VN | Viet Nam |
| VU | Vanuatu |
| WF | Islas Wallis y Futuna |
| WK | Isla Wake |
| WS | Samoa |
| YD | Yemen, Democratic |
| YE | Yemen |
| YU | Iugoslavia |
| ZA | South Africa |
| ZM | Zambia |
| ZR | Zaire |
| nd | Not defined |
ctdbid
| ACTR | ACTR - Australian Clinical Trials Registry |
| CT | CT - Clinicaltrials.gov |
| ChiCTR | ChiCTR - Chinese Clinical Trial Register |
| ISRCTN | ISRCTN - International Standard Randomised Controlled Trial Number Register |
| NTR | NTR - Nederlands Trial Register |
| UMIN | UMIN - University Hospital Medical Information Network |
date
| Apr. | April |
| Aug. | August |
| Dec. | December |
| Feb. | February |
| Jan. | January |
| July | July |
| Jun. | June |
| Mar. | March |
| May | May |
| Nov. | November |
| Oct. | October |
| Sept. | September |
dateiso
| 00000000 | 00000000 |
deceased
| n | no |
| y | yes |
deposid
| 1 | Unicamp |
| 2 | Unifesp |
| 3 | Unesp |
| 4 | USP |
| 5 | ITA |
| 6 | UFSCar |
doctopic
| ab | abstracts |
| an | announcements |
| ax | annex |
| co | comments |
| cr | case report |
| ct | clinical trial |
| ed | editorial |
| er | correction |
| in | interview |
| le | letter |
| mt | methodology |
| oa | original article |
| pr | press release |
| pv | point-of-view |
| ra | review article |
| rc | recount |
| rn | research note |
| sc | brief communication |
| tr | technical report |
| up | update |
doctype
| addended-article | addended-article |
| addendum | addendum |
| article | article |
| au | audio |
| book | book |
| chapter | chapter |
| commentary-article | commentary-article |
| companion | companion |
| corrected-article | corrected-article |
| database | database |
| figure | figure |
| letter | letter |
| object-of-concern | object-of-concern |
| other-object | other object |
| other-related-type | other related type |
| other-source | other source |
| peer-review | peer-review |
| peer-reviewed-article | peer-reviewed-article |
| pr | press release |
| retracted-article | retracted-article |
| table | table |
| unknown |
|
| unknown-object | – objects – |
| unknown-related-type | – related types – |
| unknown-source | – sources – |
| vi | video |
eqcontr
| n | no |
| y | yes |
fntype
| abbr | Abbreviations |
| author | Some footnote type, other than those enumerated, but related to author. |
| com | Communicated-by information |
| con | Contributed-by information |
| conflict | Conflict of interest statements |
| corresp | Corresponding author information not identified separately, but merely footnoted |
| current-aff | Contributor’s current affiliation |
| deceased | Person has died since article was written |
| edited-by | Contributor has the role of an editor |
| equal | Contributed equally to the creation of the document |
| financial-disclosure | Statement of funding or denial of funds received in support of the research on which an article is based |
| on-leave | Contributor is on sabbatical or other leave of absence |
| other | Some footnote type, other than those enumerated. |
| participating-researchers | Contributor was a researcher for an article |
| present-address | Contributor’s current address |
| presented-at | Conference, colloquium, or other occasion at which this paper was presented |
| presented-by | Contributor who presented the material |
| previously-at | Contributor’s previous location or affiliation |
| study-group-members | Contributor was a member of the study group for the research |
| supplementary-material | Points to or describes supplementary material for the article |
| supported-by | Research upon which an article is based was supported by some entity |
frequency
| ? | Unknown |
| A | Annual |
| B | Bimonthly (every two months) |
| C | Semiweekly (twice a week) |
| D | Daily |
| E | Biweekly (every two weeks) |
| F | Semiannual (twice a year) |
| G | Biennial (every two years) |
| H | Triennial (every three years) |
| I | Three times a week |
| J | Three times a month |
| K | Irregular (known to be so) |
| M | Monthly |
| Q | Quarterly |
| S | Semimonthly (twice a month) |
| T | Three times a year |
| W | Weekly |
| Z | Other frequencies |
from
| 00000000 | 00000000 |
ftp
| art | article based - a PDF file for each article |
| iss | issue based - a PDF file for each issue |
| na | Not Available |
ftype
| audiogram | audiogram |
| cardiogram | cardiogram |
| cartoon | cartoon |
| chart | chart |
| chemical structure | chemical structure |
| dendrogram | dendrogram |
| diagram | diagram |
| drawing | drawing |
| exihibit | exihibit |
| graphic | graphic |
| illustration | illustration |
| map | map |
| medical image | medical image |
| other | other |
| photo | photo |
| photomicrograph | photomicrograph |
| plate | plate |
| polysomnogram | polysomnogram |
| schema | schema |
| workflow | workflow |
hcomment
| 0 | people can not comment |
| 1 | people can comment |
history
| D | Ceased |
| E | Not open access |
| S | Indexing interrupted by committee |
Note: history was replaced by historystatus
historystatus
id
| nd | Not defined |
idiom interface
| en | English |
| es | Spanish |
| pt | Portuguese |
illustrative material type
| gra | graphic |
| ilus | figure |
| map | map |
| nd | no illustrative material |
| tab | table |
indexing coverage
| BA | Biological Abstracts |
| EM | Excerpta Medica |
| IM | Index Medicus |
| LL | LILACS |
| SP | Salud Publica |
issn type
| CDROM | CD-ROM ISSN |
| DISKT | Diskette ISSN |
| ONLIN | On line ISSN |
| PRINT ISSN |
issue status
| 0 | Not available |
| 1 | Available |
| 2 | Partial available |
keyword priority level
| m | main |
| s | secondary |
language
| af | Afrikaans |
| ar | Arabic |
| bg | Bulgarian |
| ca | Catalan |
| zh | Chinese |
| cs | Czech |
| da | Danish |
| de | German |
| en | English |
| eo | Esperanto |
| es | Spanish |
| eu | Basque |
| fr | French |
| gl | Galician |
| gr | Greek |
| he | Hebrew |
| hi | Hindi |
| hu | Hungarian |
| ia | Interlingua |
| ie | Interlingue |
| in | Indonesian |
| it | Italian |
| ja | Japanese |
| ko | Korean |
| la | Latin |
| nl | Dutch |
| no | Norwergian |
| pl | Polish |
| pt | Portuguese |
| ro | Romanian |
| ru | Russian |
| sa | Sanskrit |
| sh | Serbo-Croat |
| sk | Slovak |
| sn | Slovenian |
| sv | Swedish |
| tr | Turkish |
| uk | Ukrainian |
| ur | Urdu |
| zz | Other |
license_text
| BY | <a rel=”license” href=”http://creativecommons.org/licenses/by/3.0/”><img alt=”Creative Commons License” style=”border-width:0” src=”http://i.creativecommons.org/l/by/3.0/80x15.png” /></a> All the contents of this journal, except where otherwise noted, is licensed under a <a rel=”license” href=”http://creativecommons.org/licenses/by/3.0/”>Creative Commons Attribution License</a> |
| BY-NC | <a rel=”license” href=”http://creativecommons.org/licenses/by-nc/3.0/”><img alt=”Creative Commons License” style=”border-width:0” src=”http://i.creativecommons.org/l/by-nc/3.0/80x15.png” /></a> All the contents of this journal, except where otherwise noted, is licensed under a <a rel=”license” href=”http://creativecommons.org/licenses/by-nc/3.0/”>Creative Commons Attribution License</a> |
| BY-NC-SA | <a rel=”license” href=”http://creativecommons.org/licenses/by-nc-sa/3.0/”><img alt=”Creative Commons License” style=”border-width:0” src=”http://i.creativecommons.org/l/by-nc-sa/3.0/80x15.png” /></a> All the contents of this journal, except where otherwise noted, is licensed under a <a rel=”license” href=”http://creativecommons.org/licenses/by-nc-sa/3.0/”>Creative Commons Attribution License</a> |
| nd | <p> </p> |
lictype
| nd | not defined |
| open-access | open access |
listtype
| alpha-lower | Ordered list. Prefix character is a lowercase alphabetical character |
| alpha-upper | Ordered list. Prefix character is an uppercase alphabetical character |
| bullet | Unordered or bulleted list. Prefix character is a bullet, dash, or other symbol |
| order | Ordered list. Prefix character is a number or a letter, depending on style |
| roman-lower | Ordered list. Prefix character is a lowercase roman numeral |
| roman-upper | Ordered list. Prefix character is an uppercase roman numeral |
| simple | Simple or plain list (No prefix character before each item) |
literature type
| C | Conference |
| M | Monograph |
| MC | Conference papers as Monograph |
| MP | Project papers as Monograph |
| MPC | Project and Conference papers as monograph |
| MS | Monograph Series |
| MSC | Conference papers as Monograph Series |
| MSP | Project papers as Monograph Series |
| N | Document in a non conventional form |
| NC | Conference papers in a non conventional form |
| NP | Project papers in a non conventional form |
| P | Project |
| S | Serial |
| SC | Conference papers as Periodical Series |
| SCP | Conference and Project papers as periodical series |
| SP | Project papers as Periodical Series |
| T | Thesis and Dissertation |
| TS | Thesis Series |
month
| 1 | Jan. |
| 10 | Oct. |
| 11 | Nov. |
| 12 | Dec. |
| 2 | Feb. |
| 3 | Mar. |
| 4 | Apr. |
| 5 | May |
| 6 | June |
| 7 | July |
| 8 | Aug. |
| 9 | Sept. |
no
| 0 | 0 |
orgdiv
| nd | nd |
orgdiv1
| nd | nd |
orgdiv2
| nd | nd |
orgdiv3
| nd | nd |
orgname
| nd | nd |
pages
| 0-0 | 0-0 |
pii
| nd | Not defined |
publication level
| CT | Scientific/technical |
| DI | Divulgation |
pubtype
| epub | electronic publication |
| ppub | print publication |
ref-type
| aff | Affiliation |
| app | Appendix |
| author-notes | Author notes |
| bibr | Bibliographic reference |
| boxed-text | Textbox or sidebar |
| chem | Chemical structure |
| contrib | Contributor |
| corresp | Corresponding author |
| disp-formula | Display formula |
| fig | Figure or group of figures |
| fn | Footnote |
| kwd | Keyword |
| list | List or list item |
| other | None of the items listed |
| plate | Plate |
| scheme | Scheme |
| sec | Section |
| statement | Statement |
| supplementary-material | Supplementary information |
| table | Table or group of tables |
rid
| nd | Not defined |
role
| coord | coordinator |
| ed | publisher |
| nd | Not defined |
| org | organizer |
| tr | translator |
scheme
| decs | Health Science Descriptors |
| nd | No Descriptor |
scielonet
| 1 | SciELO Brasil |
| 10 | SciELO Argentina |
| 11 | SciELO Biodiversidade |
| 12 | SciELO Bolivia |
| 13 | SciELO España |
| 14 | SciELO Jamaica |
| 15 | SciELO México |
| 16 | SciELO Perú |
| 17 | SciELO Portugal |
| 18 | SciELO Venezuela |
| 19 | SciELO Adolec |
| 2 | SciELO Chile |
| 20 | SciELO Social Sciences |
| 21 | SciELO Paraguay |
| 22 | SciELO Ecuador |
| 23 | SciELO Caribbean |
| 24 | SciELO South Africa |
| 3 | SciELO Salud Pública |
| 4 | SciELO BEEP |
| 5 | SciELO Ecler |
| 6 | SciELO Cuba |
| 7 | SciELO Colombia |
| 8 | SciELO Costa Rica |
| 9 | SciELO Uruguay |
sec-type
| cases | Cases/Case Reports |
| conclusions | Conclusions/Comment |
| discussion | Discussion/Interpretation |
| intro | Introduction/Synopsis |
| materials | Materials |
| materials|methods |
|
| methods | Methods/Methodology/Procedures |
| nd | undefined |
| results | Results/Statement of Findings |
| results|conclusions |
|
| results|discussion |
|
| results|discussion|conclusions |
|
| subjects | Subjects/Participants/Patients |
| supplementary-material | Supplementary materials |
standard
| apa | American Psychological Association |
| iso690 | iso 690/87 - international standard organization |
| nbr6023 | nbr 6023/89 - associação nacional de normas técnicas |
| other | other standard |
| vancouv | the vancouver group - uniform requirements for manuscripts submitted to biomedical journals |
state
| AC | Acre |
| AL | Alagoas |
| AM | Amazonas |
| AP | Amapá |
| BA | Bahia |
| CE | Ceará |
| DF | Distrito Federal |
| ES | Espírito Santo |
| FN | Fernando de Noronha |
| GO | Goiás |
| MA | Maranhão |
| MG | Minas Gerais |
| MS | Mato Grosso do Sul |
| MT | Mato Grosso |
| PA | Pará |
| PB | Paraíba |
| PE | Pernambuco |
| PI | Piauí |
| PR | Paraná |
| RJ | Rio de Janeiro |
| RN | Rio Grande do Norte |
| RO | Rondônia |
| RR | Roraima |
| RS | Rio Grande do Sul |
| SC | Santa Catarina |
| SE | Sergipe |
| SP | São Paulo |
status
| ? | Unknown |
| C | Current |
| D | Ceased |
| R | Reports only |
| S | Suspended |
stitle
| Acta Cir. Bras. | Acta Cirurgica Brasileira |
| Bragantia | Bragantia |
| Braz J Med Biol Res | Brazilian Journal of Medical and Biological Research |
| Braz. J. Chem. Eng. | Brazilian Journal of Chemical Engineering |
| Braz. J. Genet. | Brazilian Journal of Genetics |
| Braz. J. Phys. | Brazilian Journal of Physics |
| Cad. CEDES | Cadernos CEDES |
| Cad. Saúde Púbica | Cadernos de Saúde Pública |
| Ci. Inf. | Ciência da Informação |
| Ciênc. Tecnol. Aliment. | Ciência e Tecnologia de Alimentos |
| DELTA | DELTA: Documentação de Estudos em Lingüística Teórica e Aplicada |
| Dados | Dados |
| Educ. Soc. | Educação & Sociedade |
| Genet. Mol. Biol. | Genetics and Molecular Biology |
|
Journal of the Brazilian Chemical Society |
|
Journal of the Brazilian Computer Society |
|
Journal of Venomous Animals and Toxins |
| Mem. Inst. Oswaldo Cruz | Memórias do Instituto Oswaldo Cruz |
| Pesq. Vet. Bras. | Pesquisa Veterinária Brasileira |
| Psicol. USP | Psicologia USP |
| Rev Bras Cir Cardiovasc | Revista Brasileira de Cirurgia Cardiovascular |
| Rev Odontol Univ São Paulo | Revista de Odontologia da Universidade de São Paulo |
| Rev Panam Salud Publica | Revista Panamericana de Salud Pública |
| Rev. Fac. Educ. | Revista da Faculdade de Educação |
| Rev. Inst. Med. trop. S. Paulo | Revista do Instituto de Medicina Tropical de São Paulo |
| Rev. Microbiol. | Revista de Microbiologia |
| Rev. Saúde Pública | Revista de Saúde Pública |
| Rev. bras. Bot. | Revista Brasileira de Botânica |
| Rev. bras. Ci. Soc. | Revista Brasileira de Ciências Sociais |
| Rev. bras. Ci. Solo | Revista Brasileira de Ciência do Solo |
| Rev. bras. Geocienc. | Revista Brasileira de Geosciences |
| Rev. bras. Hist. | Revista Brasileira de História |
| Salud pública Méx | Salud Pública de México |
| Sci. agric. | Scientia Agricola |
study area
| Agricultural Sciences | Agricultural Sciences |
| Applied Social Sciences | Applied Social Sciences |
| Biological Sciences | Biological Sciences |
| Engineering | Engineering |
| Exact and Earth Sciences | Exact and Earth Sciences |
| Health Sciences | Health Sciences |
| Human Sciences | Human Sciences |
| Linguistics, Letters and Arts | Linguistic, Literature and Arts |
table of contents
| en | Table of Contents |
| es | Sumario |
| pt | Sumário |
to
| 00000000 | 00000000 |
toccode
| 1 | title |
| 2 | sectitle |
treatment level
| am | analytical of a monograph |
| amc | analytical of a monograph in a collection |
| ams | analytical of a monograph in a serial |
| as | analytical of a serial |
| c | collective level |
| m | monographic level |
| mc | monographic in a collection |
| ms | monographic series level |
usersubscription
| na | Not Available |
| reg | Electronic Registration |
| sub | Regular Subscription |
version
| 3.1 | 3.1 |
| 4.0 | 4.0 |