PRESERVAÇÃO DIGITAL
- ARCHIVEMATICA
- INSTALANDO O ARCHIVEMATICA NO ROCKY LINUX 9
- MIGRANDO O ARCHIVEMATICA PARA UM NOVO SERVIDOR
- DIAGRAMA ARCHIVEMATICA
- FLUXO DE PRESERVAÇÃO DIGITAL USANDO O ARCHIVEMATICA E O ATOM
- FLUXO DE PRESERVAÇÃO DIGITAL DO SCIELO DATA USANDO O ARCHIVEMATICA E O ATOM
- ATOM
- GERENCIAR PACOTES BAGIT
ARCHIVEMATICA
INSTALANDO O ARCHIVEMATICA NO ROCKY LINUX 9
Atualizando o sistema operacional:
sudo yum -y updateSe o seu ambiente usar SELinux, você precisará executar no mínimo os seguintes comandos. Configuração adicional pode ser necessária para sua configuração local.
# Allow Nginx to use ports 81 and 8001
sudo semanage port -m -t http_port_t -p tcp 81
sudo semanage port -a -t http_port_t -p tcp 8001
# Allow Nginx to connect the MySQL server and Gunicorn backends
sudo setsebool -P httpd_can_network_connect_db=1
sudo setsebool -P httpd_can_network_connect=1
# Allow Nginx to change system limits
sudo setsebool -P httpd_setrlimit 1Alguns repositórios extras precisam ser instalados para cumprir o procedimento de instalação.
sudo -u root yum install -y epel-release yum-utils
sudo -u root yum-config-manager --enable crbINSTALANDO OS REPOSITÓRIOS DO ELASTICSEARCH E O ARCHIVEMATICA
- Elasticsearch
sudo -u root rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
sudo -u root bash -c 'cat << EOF > /etc/yum.repos.d/elasticsearch.repo
[elasticsearch-6.x]
name=Elasticsearch repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF'- Archivematica
sudo -u root bash -c 'cat << EOF > /etc/yum.repos.d/archivematica.repo
[archivematica]
name=archivematica
baseurl=https://packages.archivematica.org/1.15.x/rocky9/
gpgcheck=1
gpgkey=https://packages.archivematica.org/GPG-KEY-archivematica-sha512
enabled=1
EOF'
sudo -u root bash -c 'cat << EOF > /etc/yum.repos.d/archivematica-extras.repo
[archivematica-extras]
name=archivematica-extras
baseurl=https://packages.archivematica.org/1.15.x/rocky9-extras
gpgcheck=1
gpgkey=https://packages.archivematica.org/GPG-KEY-archivematica-sha512
enabled=1
EOF'INSTALANDO O ELASTICSEARCH, MARIADB E GEARMAND
Serviços comuns como Elasticsearch, MariaDB e Gearmand devem ser instalados e habilitados antes da instalação do Archivematica.
sudo -u root yum install -y java-1.8.0-openjdk-headless mariadb-server gearmand
sudo -u root yum install -y elasticsearch
sudo -u root systemctl enable elasticsearch
sudo -u root systemctl start elasticsearch
sudo -u root systemctl enable mariadb
sudo -u root systemctl start mariadb
sudo -u root systemctl enable gearmand
sudo -u root systemctl start gearmandCRIANDO O BANCO DE DADOS DO ARCHIVEMATICA E DO STORAGE SERVICE
Agora que o MariaDB está instalado e funcionando, crie os bancos de dados Archivematica e Storage Service e configure as credenciais esperadas.
sudo -H -u root mysql -hlocalhost -uroot -e "DROP DATABASE IF EXISTS MCP; CREATE DATABASE MCP CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;"
sudo -H -u root mysql -hlocalhost -uroot -e "DROP DATABASE IF EXISTS storage_service; CREATE DATABASE SS CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;"
sudo -H -u root mysql -hlocalhost -uroot -e "CREATE USER 'archivematica'@'localhost' IDENTIFIED BY 'demo';"
sudo -H -u root mysql -hlocalhost -uroot -e "GRANT ALL ON MCP.* TO 'archivematica'@'localhost';"
sudo -H -u root mysql -hlocalhost -uroot -e "GRANT ALL ON storage_service.* TO 'archivematica'@'localhost';"Instale o serviço de armazenamento Archivematica Storage Service
sudo -u root yum install -y python-pip archivematica-storage-serviceAplique as migrações de banco de dados usando o usuário archivematica:
sudo -u archivematica bash -c " \
set -a -e -x
source /etc/sysconfig/archivematica-storage-service
cd /usr/lib/archivematica/storage-service
/usr/share/archivematica/virtualenvs/archivematica-storage-service/bin/python manage.py migrate
";Agora habilite e inicie o archivematica-storage-service, rngd (necessário para espaços criptografados) e o frontend Nginx:
sudo -u root systemctl enable archivematica-storage-service
sudo -u root systemctl start archivematica-storage-service
sudo -u root systemctl enable nginx
sudo -u root systemctl start nginx
sudo -u root systemctl enable rngd
sudo -u root systemctl start rngdO Serviço de Armazenamento estará disponível em http://<ip>:8001.
INSTALANDO O ARCHIVEMATICA DASHBOARD E O MCP SERVER
sudo -u root yum install -y archivematica-common archivematica-mcp-server archivematica-dashboardAplique as migrações de banco de dados usando o usuário archivematica:
sudo -u archivematica bash -c " \
set -a -e -x
source /etc/sysconfig/archivematica-dashboard
cd /usr/share/archivematica/dashboard
/usr/share/archivematica/virtualenvs/archivematica/bin/python manage.py migrate
";Inicie e habilite serviços:
sudo -u root systemctl enable archivematica-mcp-server
sudo -u root systemctl start archivematica-mcp-server
sudo -u root systemctl enable archivematica-dashboard
sudo -u root systemctl start archivematica-dashboardReinicie o Nginx para carregar o arquivo de configuração do painel:
sudo -u root systemctl restart nginxO painel estará disponível em http://<ip>:81
INSTALANDO O MCP CLIENT
sudo -u root yum install -y archivematica-mcp-clientTweak ClamAV configuration:
sudo -u root sed -i 's/^#TCPSocket/TCPSocket/g' /etc/clamd.d/scan.conf
sudo -u root sed -i 's/^Example//g' /etc/clamd.d/scan.confDepois disso, podemos ativar e iniciar/reiniciar serviços
sudo -u root systemctl enable archivematica-mcp-client
sudo -u root systemctl start archivematica-mcp-client
sudo -u root systemctl enable fits-nailgun
sudo -u root systemctl start fits-nailgun
sudo -u root systemctl enable clamd@scan
sudo -u root systemctl start clamd@scan
sudo -u root systemctl restart archivematica-dashboard
sudo -u root systemctl restart archivematica-mcp-serverFinalizando a instalação
Configuração
Cada serviço possui um arquivo de configuração em /etc/sysconfig/archivematica-packagename
Solução de problemas
Se o IPv6 estiver desabilitado, o Nginx pode se recusar a iniciar. Se for esse o caso, certifique-se de que as diretivas listen usadas em /etc/nginx não estejam usando endereços IPv6 como [::]:80.
Rocky Linux instalará o firewalld que executará regras padrão que provavelmente bloquearão as portas 81 e 8001. Se você não conseguir acessar o painel e o serviço de armazenamento, use o seguinte comando para verificar se o firewalld está em execução:
sudo systemctl status firewalldSe o firewalld estiver em execução, você provavelmente precisará modificar as regras do firewall para permitir o acesso às portas 81 e 8001 do seu local:
sudo firewall-cmd --add-port=81/tcp --permanent
sudo firewall-cmd --add-port=8001/tcp --permanentCONFIGURAÇÃO PÓS-INSTALAÇÃO
Após concluir com êxito uma nova instalação, siga estas etapas para concluir a configuração do seu novo servidor.
O Serviço de Armazenamento é executado como um aplicativo web separado do painel do Archivematica. O Serviço de Armazenamento é exposto na porta 8001 por padrão ao implantar usando pacotes RPM. Use seu navegador da web para navegar até o serviço de armazenamento no endereço IP da máquina em que você está instalando, por exemplo, http://<MY-IP-ADDR>:8001 (ou http://localhost:8001 ou http: //127.0.0.1:8001 se esta for uma configuração de desenvolvimento local).
Se estiver usando um endereço IP ou nome de domínio totalmente qualificado em vez de localhost, você precisará configurar suas regras de firewall e permitir acesso apenas às portas 81 e 8001 para uso do Archivematica.
O Serviço de Armazenamento possui seu próprio conjunto de usuários. Crie um novo usuário com privilégios totais de administrador:
sudo -u archivematica bash -c " \
set -a -e -x
source /etc/default/archivematica-storage-service || \
source /etc/sysconfig/archivematica-storage-service \
|| (echo 'Environment file not found'; exit 1)
cd /usr/lib/archivematica/storage-service
/usr/share/archivematica/virtualenvs/archivematica-storage-service/bin/python manage.py createsuperuser
";Depois de criar esse usuário, a chave de API será gerada automaticamente e essa chave conectará o pipeline do Archivematica à API do Storage Service. A chave API pode ser encontrada através da interface web (vá em Administração > Usuários).
Para finalizar a instalação, use seu navegador da web para navegar até o painel do Archivematica usando o endereço IP da máquina na qual você está instalando, por exemplo, http://<MY-IP-ADDR>:81 (ou http:// localhost:81 ou http://127.0.0.1:81 se esta for uma configuração de desenvolvimento local).
Na página de boas-vindas, crie um usuário administrativo para o pipeline do Archivematica inserindo o nome da organização, o identificador da organização, nome de usuário, email e senha.
Na próxima tela, conecte seu pipeline ao serviço de armazenamento inserindo a URL e o nome de usuário do serviço de armazenamento e colando a chave de API que você copiou na etapa (2).
Se o serviço de armazenamento e o painel do Archivematica estiverem instalados na mesma máquina, você deverá fornecer http://127.0.0.1:8001 como URL do serviço de armazenamento nesta tela.
Se o Serviço de Armazenamento e o painel do Archivematica estiverem instalados em nós (servidores) diferentes, você deverá usar o endereço IP ou nome de domínio totalmente qualificado da sua instância do Serviço de Armazenamento, por exemplo, http://<MY-IP-ADDR>: 8001 e você deve garantir que todas as regras de firewall (ou seja, iptables, ufw, grupos de segurança da AWS etc.) estejam configuradas para permitir solicitações do IP do seu painel para o IP do serviço de armazenamento na porta apropriada.
REFERÊNCIA
MIGRANDO O ARCHIVEMATICA PARA UM NOVO SERVIDOR
A migração do archivematica foi de um servidor CentOS 7.9 para Rocky Linux 9.4
A versão do archivematica era o 1.14.1 e foi migrado para 1.16.0
Atualizando o sistema operacional:
sudo yum -y updateSe o seu ambiente usar SELinux, você precisará executar no mínimo os seguintes comandos. Configuração adicional pode ser necessária para sua configuração local.
# Allow Nginx to use ports 81 and 8001
sudo semanage port -m -t http_port_t -p tcp 81
sudo semanage port -a -t http_port_t -p tcp 8001
# Allow Nginx to connect the MySQL server and Gunicorn backends
sudo setsebool -P httpd_can_network_connect_db=1
sudo setsebool -P httpd_can_network_connect=1
# Allow Nginx to change system limits
sudo setsebool -P httpd_setrlimit 1Alguns repositórios extras precisam ser instalados para cumprir o procedimento de instalação.
sudo -u root yum install -y epel-release yum-utils
sudo -u root yum-config-manager --enable crbINSTALANDO OS REPOSITÓRIOS DO ELASTICSEARCH E O ARCHIVEMATICA
- Elasticsearch
sudo -u root rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
sudo -u root bash -c 'cat << EOF > /etc/yum.repos.d/elasticsearch.repo
[elasticsearch-6.x]
name=Elasticsearch repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF'- Archivematica
sudo -u root bash -c 'cat << EOF > /etc/yum.repos.d/archivematica.repo
[archivematica]
name=archivematica
baseurl=https://packages.archivematica.org/1.15.x/rocky9/
gpgcheck=1
gpgkey=https://packages.archivematica.org/GPG-KEY-archivematica-sha512
enabled=1
EOF'
sudo -u root bash -c 'cat << EOF > /etc/yum.repos.d/archivematica-extras.repo
[archivematica-extras]
name=archivematica-extras
baseurl=https://packages.archivematica.org/1.15.x/rocky9-extras
gpgcheck=1
gpgkey=https://packages.archivematica.org/GPG-KEY-archivematica-sha512
enabled=1
EOF'INSTALANDO O ELASTICSEARCH, MARIADB E GEARMAND
Serviços comuns como Elasticsearch, MariaDB e Gearmand devem ser instalados e habilitados antes da instalação do Archivematica.
sudo -u root yum install -y java-1.8.0-openjdk-headless mariadb-server gearmand
sudo -u root yum install -y elasticsearch
sudo -u root systemctl enable elasticsearch
sudo -u root systemctl start elasticsearch
sudo -u root systemctl enable mariadb
sudo -u root systemctl start mariadb
sudo -u root systemctl enable gearmand
sudo -u root systemctl start gearmandMIGRANDO OS BANCOS NO MARIADB
CRIANDO O DUMP DOS BANCOS
No servidor de origem:
mysqldump -u root -p MCP > ~/am_backup.sql
mysqldump -u root -p storage_service > ~/storage_service.sqlAgora devemos copiá-los para o servidor de destino.
CRIANDO O BANCO DE DADOS DO ARCHIVEMATICA E DO STORAGE SERVICE
Agora que o MariaDB está instalado e funcionando, crie os bancos de dados Archivematica e Storage Service e configure as credenciais esperadas.
sudo -H -u root mysql -hlocalhost -uroot -e "DROP DATABASE IF EXISTS MCP; CREATE DATABASE MCP CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;"
sudo -H -u root mysql -hlocalhost -uroot -e "DROP DATABASE IF EXISTS storage_service; CREATE DATABASE SS CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;"
sudo -H -u root mysql -hlocalhost -uroot -e "CREATE USER 'archivematica'@'localhost' IDENTIFIED BY '<omitida>';"
sudo -H -u root mysql -hlocalhost -uroot -e "GRANT ALL ON MCP.* TO 'archivematica'@'localhost';"
sudo -H -u root mysql -hlocalhost -uroot -e "GRANT ALL ON storage_service.* TO 'archivematica'@'localhost';"FAZENDO O RESTORE DO BANCO
Uma vez copiados os dumps, devemos restaurá-lo nos bancos recém criados.
mysql -u root -p MCP < ~/am_backup.sql
mysql -u root -p storage_service < ~/storage_service.sqlMIGRANDO O INDICE NO ELASTICSEARCH
CONFIGURANDO O CAMINHO DO REPOSITÓRIO
O repositório dos snapshots no SciELO é um ponto de montagem NFS. Este ponto NFS deve ser montado no novo servidor. Mas antes instale o pacote nfs-utils:
sudo yum install nfs-utils -yCrie o diretório do repositório:
sudo mkdir /var/lib/elasticsearch/backup-repoConfigure o /etc/fstab para persistir:
storage-scielo-251.scielo.org:/archivematica_es_bkp /var/lib/elasticsearch/backup-repo nfs vers=4,rsize=8192,wsize=8192,timeo=14,intr 0 0Agora basta montar:
sudo systemctl daemon-reload
sudo mount -aADICIONADO O ELASTICSEARCH NA CONFIGURAÇÃO
Edite o arquivo /etc/elasticsearch/elasticsearch.yml e adicione a linha abaixo de path.logs:
path.repo: /var/lib/elasticsearch/backup-repoReinicie o elasticsearch
sudo systemctl restart elasticsearchDevemos garantir que o usuário elasticsearch seja o dono do diretório /var/lib/elasticsearch/backup-repo:
sudo chown elasticsearch. -R /var/lib/elasticsearch/backup-repoCRIANDO O REPOSITÓRIO
curl -XPUT -H 'Content-Type: application/json' 'http://localhost:9200/_snapshot/es_backup_archivematica' -d '{
"type": "fs",
"settings": {
"compress" : true,
"location": "/var/lib/elasticsearch/backup-repo/es_backup_archivematica"
}
}'Consulte o repositório:
curl -X GET "localhost:9200/_cat/snapshots/es_backup_archivematica?v&s=id&pretty"
RESTAURANDO O ÚLTIMO SNAPSHOT
curl -X POST "localhost:9200/_snapshot/es_backup_archivematica/20240917-235942/_restore?pretty"LISTANDO OS INDICES RESTAURADOS
curl -X GET "http://localhost:9200/_cat/indices?v"
MIGRANDO O ARCHIVEMATICA STORAGE SERVICE
Instale o serviço de armazenamento Archivematica Storage Service
sudo -u root yum install -y python-pip archivematica-storage-serviceCopie o arquivo /etc/sysconfig/archivematica-storage-service do servidor de origem
Instale o Archivematica Dashboard e o MCP Service e Client:
sudo -u root yum install -y archivematica-common archivematica-mcp-server archivematica-dashboard archivematica-mcp-clientCopie o arquivo /etc/sysconfig/archivematica-dashboard, /etc/sysconfig/archivematica-storage-service e o /etc/sysconfig/archivematica-mcp-client do servidor de origem.
APLICANDO A MIGRAÇÃO DO BANCO DO ARCHIVEMATICA
sudo -u archivematica bash -c " \
set -a -e -x
source /etc/default/archivematica-dashboard || \
source /etc/sysconfig/archivematica-dashboard \
|| (echo 'Environment file not found'; exit 1)
cd /usr/share/archivematica/dashboard
/usr/share/archivematica/virtualenvs/archivematica/bin/python manage.py migrate --noinput
";APLICANDO A MIGRAÇÃO DO BANCO DO ARCHIVEMATICA STORAGE SERVICE
sudo -u archivematica bash -c " \
set -a -e -x
source /etc/default/archivematica-storage-service || \
source /etc/sysconfig/archivematica-storage-service \
|| (echo 'Environment file not found'; exit 1)
cd /usr/lib/archivematica/storage-service
/usr/share/archivematica/virtualenvs/archivematica-storage-service/bin/python manage.py migrate
";Reiniciando os serviços:
sudo systemctl restart archivematica-storage-service
sudo systemctl restart archivematica-dashboard
sudo systemctl restart archivematica-mcp-client
sudo systemctl restart archivematica-mcp-server
sudo -u root systemctl enable nginx
sudo -u root systemctl start nginx
sudo -u root systemctl enable rngd
sudo -u root systemctl start rngdCONFIGURANDO O ANTI-VIRUS
sudo -u root sed -i 's/^#TCPSocket/TCPSocket/g' /etc/clamd.d/scan.conf
sudo -u root sed -i 's/^Example//g' /etc/clamd.d/scan.confDepois disso, podemos ativar e iniciar/reiniciar serviços
sudo -u root systemctl enable archivematica-mcp-client
sudo -u root systemctl start archivematica-mcp-client
sudo -u root systemctl enable fits-nailgun
sudo -u root systemctl start fits-nailgun
sudo -u root systemctl enable clamd@scan
sudo -u root systemctl start clamd@scan
sudo -u root systemctl restart archivematica-dashboard
sudo -u root systemctl restart archivematica-mcp-serverCONFIGURANDO O NGINX
O archivematica-dashboard e o archivematica-storage-service terão um vhost configurado:
/etc/nginx/conf.d/archivematica-dashboard.conf
server {
listen 80 default_server;
client_max_body_size 256M;
server_name _;
location / {
proxy_set_header Host $http_host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_redirect off;
proxy_buffering off;
proxy_read_timeout 172800s;
proxy_pass http://localhost4:7400;
}
}/etc/nginx/conf.d/archivematica-storage-service.conf
server {
listen 8001 default_server;
client_max_body_size 256M;
server_name _;
location / {
proxy_set_header Host $http_host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_redirect off;
proxy_buffering off;
proxy_read_timeout 172800s;
proxy_pass http://localhost4:7500;
proxy_http_version 1.1;
}
}Agora iremos configurar o proxy reverso no ha-1 para ativar o https:
/etc/nginx/conf.d/archivematica-scielo-org.conf
upstream archivematica {
server 192.168.2.126:80;
}
server {
listen 443 http2;
server_name archivematica.scielo.org;
ssl_certificate /certificados2/scielo.org/fullchain.pem;
ssl_certificate_key /certificados2/scielo.org/privkey.pem;
ssl on;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_prefer_server_ciphers on;
ssl_ciphers 'ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:AES:CAMELLIA:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!MD5:!PSK:!aECDH:!EDH-DSS-DES-CBC3-SHA:!EDH-RSA-DES-CBC3-SHA:!KRB5-DES-CBC3-SHA';
ssl_session_timeout 1d;
ssl_session_cache shared:SSL:50m;
ssl_stapling on;
ssl_stapling_verify on;
add_header Strict-Transport-Security max-age=15768000;
keepalive_timeout 150s;
client_max_body_size 100M;
location / {
proxy_set_header Host $host;
proxy_set_header X-Scheme $scheme;
proxy_set_header X-SSL-Protocal $ssl_protocol;
proxy_redirect http:// $scheme://;
proxy_set_header X-Forwarded-Proto https;
proxy_set_header X-Forwarded-Port $server_port;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://archivematica;
proxy_http_version 1.1;
proxy_read_timeout 900s;
proxy_redirect off;
allow all;
}
gzip on;
access_log /var/log/nginx/archivematica-scielo-org/archivematica-scielo-org.log;
error_log /var/log/nginx/archivematica-scielo-org/archivematica-scielo-org-error.log warn;
}
server {
listen 80;
server_name archivematica.scielo.org;
return 301 https://$server_name$request_uri;
}
MIGRANDO OS DADOS
Os dados que estão em /var/archivematica/ devem ser migrados e as permissões ajustadas para o usuário archivematica.
[root@node01-archivematica ~]# ls -lha /var/archivematica/
total 16K
drwxr-xr-x. 5 archivematica archivematica 75 Sep 18 17:03 .
drwxr-xr-x. 21 root root 4.0K Sep 18 16:58 ..
drwxr-xr-x. 15 archivematica archivematica 4.0K Jul 19 2023 sharedDirectory
drwxrwx---. 2 archivematica archivematica 24 Sep 17 09:47 storage-service
drwxr-xr-x. 172 archivematica archivematica 4.0K Sep 19 16:14 storage_serviceREFERÊNCIA
https://www.archivematica.org/en/docs/archivematica-1.12/admin-manual/maintenance/maintenance/
DIAGRAMA ARCHIVEMATICA

FLUXO DE PRESERVAÇÃO DIGITAL USANDO O ARCHIVEMATICA E O ATOM
Esta documentação visa apresentar o fluxo de preservação digital do site SciELO e seus objetos digitais. Estes objetos digitais fazem parte do pacote enviados pelos editores para produzir o conteúdo no site.
Objetivo
Apresentar o fluxo de preservação digital utilizando o Archivematica e o AtoM.
Archivematica
O Archivematica é um conjunto integrado de ferramentas de código aberto que permite o processamento de objetos digitais desde o ingresso até o acesso. Baseado em padrões em conformidade com o modelo funcional ISO-OAIS permite preservar o acesso de longo prazo a conteúdo digital confiável, autêntico e seguro. O Archivematica usa o METS, PREMIS, Dublin Core, a especificação BagIt da Library of Congress e outros normas reconhecidos para gerar Pacotes de Informações de Arquivamento (AIPs) confiáveis, autênticos, seguros e independentes do sistema para armazenamento em seu repositório preferido.
No Format Policy Registry (FPR), o Archivematica implementa suas políticas de formato padrão com base em uma análise das características significativas dos formatos de arquivo. O FPR também oferece uma estrutura editável e flexível para identificação de formatos, extração de pacotes, transcrição e normalização para preservação e acesso. Sua instituição pode atualizar ferramentas, regras e comandos em seu FPR local a partir do servidor FPR gerenciado pela Artefactual. Você também pode adicionar suas próprias políticas locais ao FPR interno. O FPR é integrado ao PRONOM.
O Archivematica integra aos sistemas: dSpace, CONTENTdm, Islandora, LOCKSS, AtoM, DuraCloud, OpenStack, Archivists'Toolkit, Arkivum, ArchivesSpace.
Usuários monitoram e controlam a ingestão e a preservação através de micro-serviços que são gerenciados através de um painel baseado em web.
Manual de uso
Acesse o site https://archivematica.scielo.org
Guia Transferência
A guia Transferência é o local onde muitos usuários iniciam o processo de transformar seus objetos digitais em Pacotes de Informações de Arquivamento (AIPs). Na guia Transferência, os usuários selecionam o material a ser preservado, nomeiam a transferência e iniciam o processo de transferência.
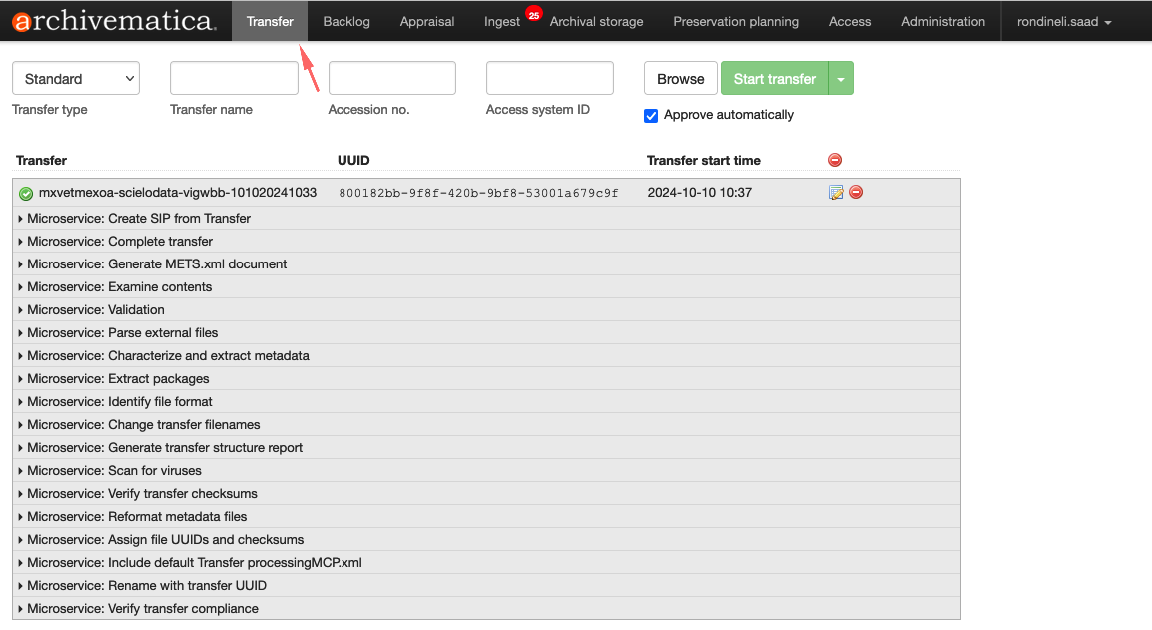
A seção na parte superior da guia Transferência é onde você encontrará materiais para transferência para o Archivematica. Existem quatro campos a serem preenchidos, os botões Browse e Start transfer e a caixa de seleção Approve automatically
- Tipo de transferência : o tipo de material que está sendo transferido. Consulte Tipos de transferência para obter mais informações.
- Nome da transferência : um nome para sua transferência. Este se tornará o nome do pacote de informações de arquivamento (AIP) resultante. Este é um campo obrigatório.
- Adesão no. : A inserção de um número de acesso para sua transferência resultará na cópia do número de acesso no arquivo AIP METS como um evento de registro. Não é usado para identificar ou procurar o AIP no Archivematica. Este campo é opcional.
- ID do sistema de acesso : inserir um campo de ID do sistema de acesso ao configurar sua transferência permite automatizar o processo de upload de um DIP para o AtoM. O Archivematica automaticamente captura esse valor quando alcançar o microsserviço DIP de upload. Consulte Carregar um DIP para AtoM para obter mais informações. Este campo é opcional.
- Procurar : O botão Procurar alterna para abrir o navegador de transferência. Isso permite que os usuários visualizem e naveguem pelos locais configurados da fonte de transferência. Para obter mais informações sobre como configurar locais de origem de transferência que o Archivematica pode acessar, consulte o Manual do administrador - Serviço de armazenamento . Selecionar um diretório e clicar em Adicionar adiciona o diretório de materiais à transferência.
- Iniciar transferência : depois de atribuir à sua transferência um nome e o material selecionado no navegador de transferências, o botão Iniciar transferência inicia os microsserviços de transferência.
- Aprovar automaticamente : se esta caixa estiver desmarcada, o Archivematica fará uma pausa no primeiro micros serviço, Aprovar transferência , e você terá a chance de confirmar que sua transferência foi configurada corretamente. Se a caixa estiver marcada, o Archivematica não fará uma pausa nesta etapa.
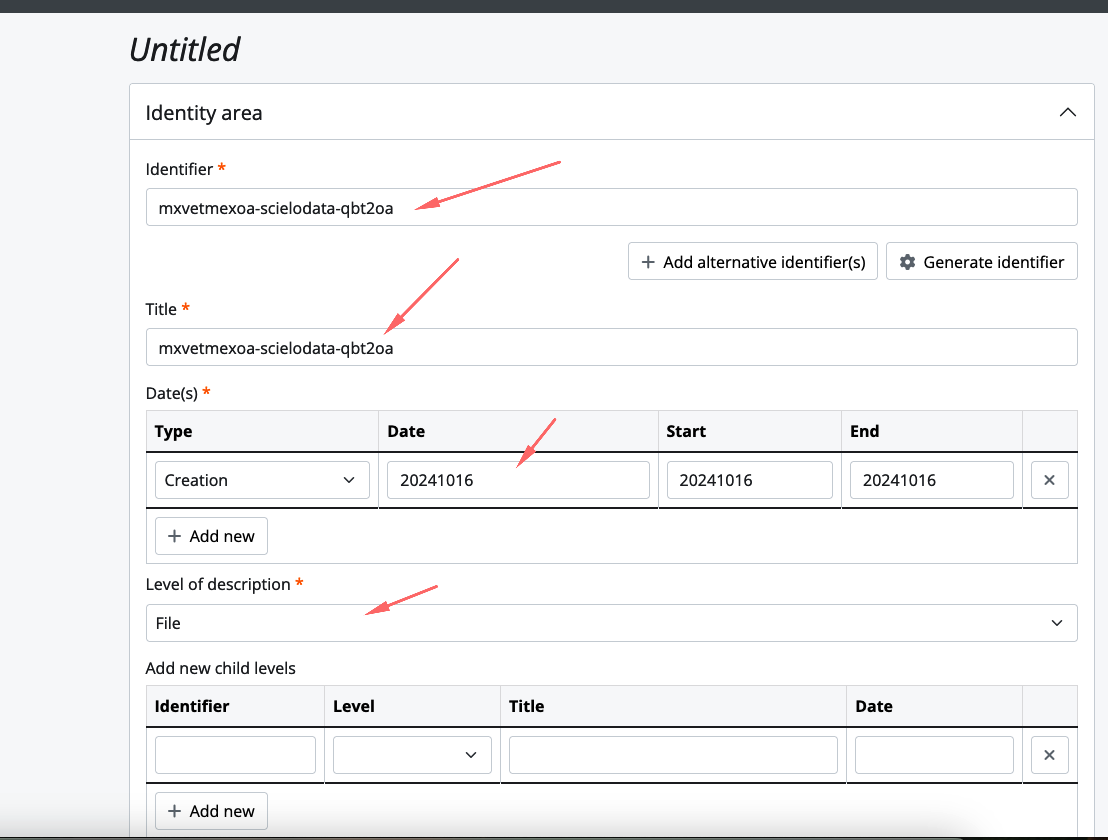
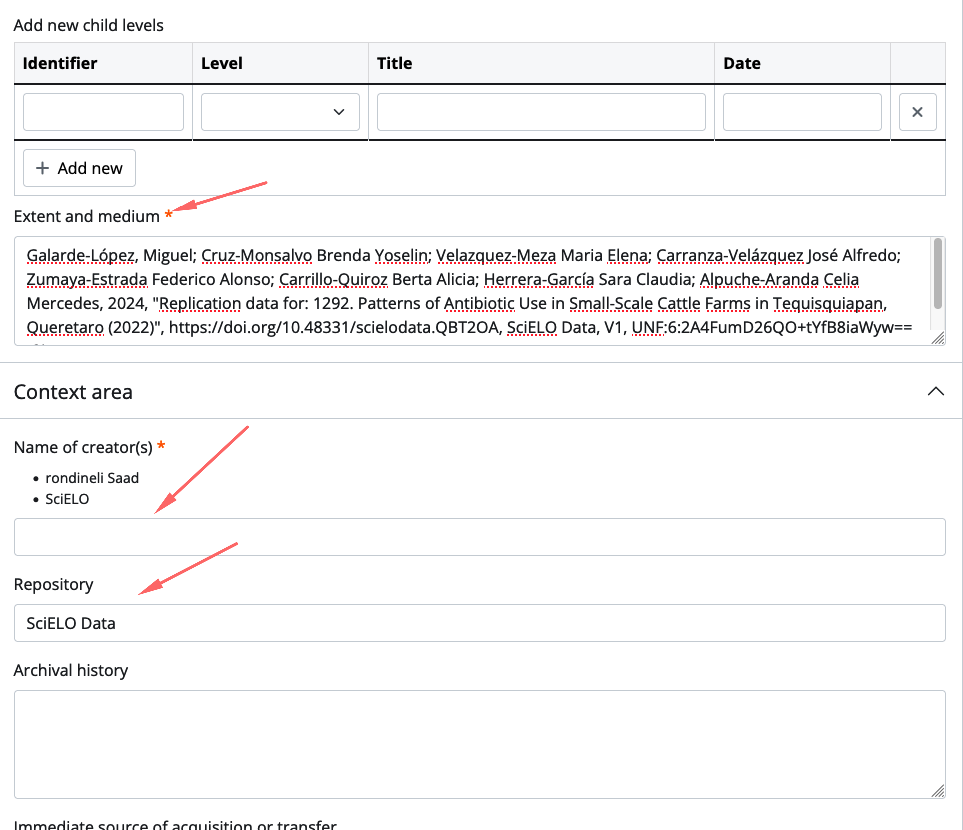
Definindo o nome da transferência
O padrão de nome adotado para transferências dos conjuntos de dados do Data SciELO ficou:
<acrônimo do periódico no dataverse>-<identificador DOI>-<dia-mes-ano-hora-minuto>
Exemplo: mxvetmexoa-scielodata-qbt2oa-161020241746
Este exemplo corresponde ao conjunto de dados com a https://data.scielo.org/dataset.xhtml?persistentId=doi:10.48331/scielodata.QBT2OA
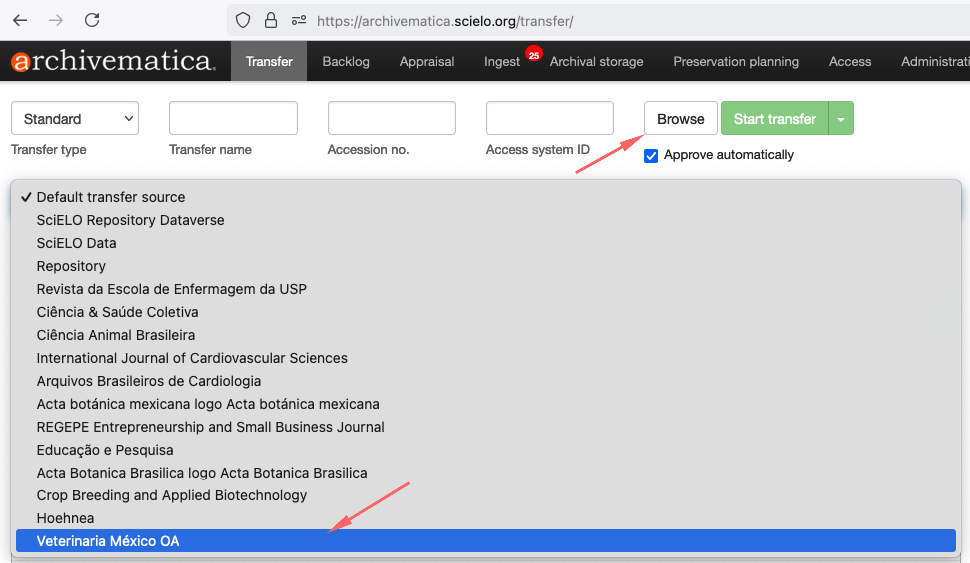
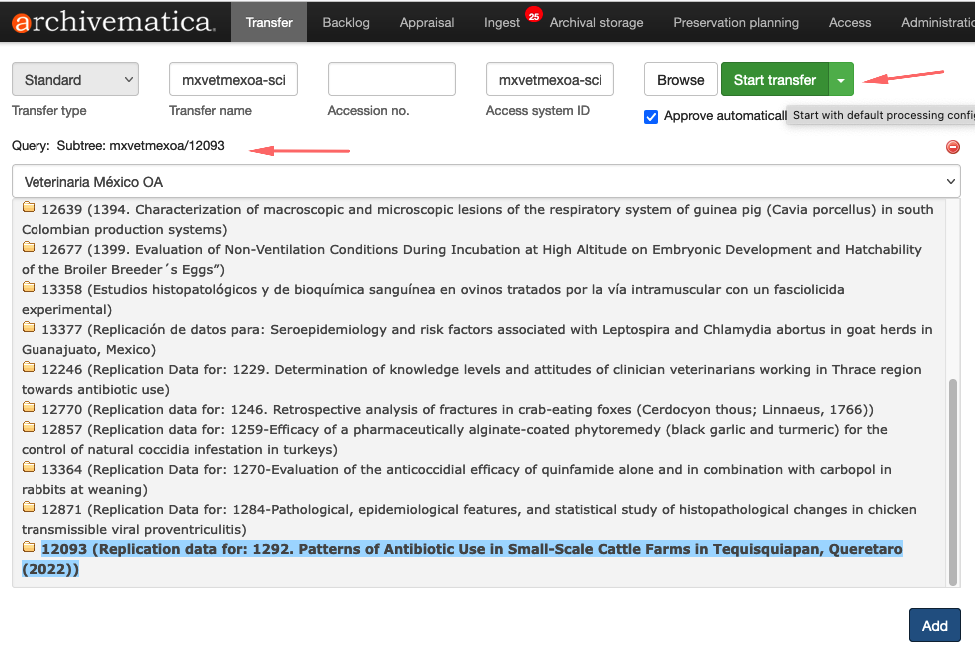
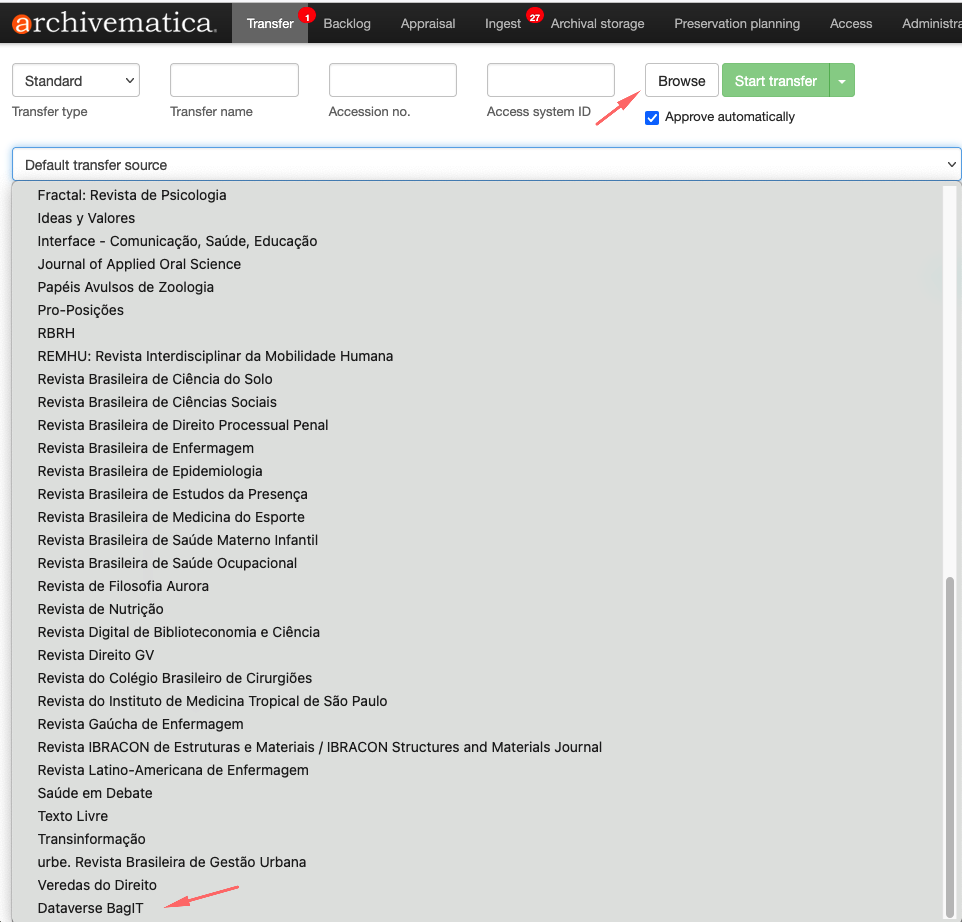
Para iniciar o processo de transferência, clique no botão Browse para listar as coleções. Selecione a coleção, conforme a imagem abaixo:
Ao selecionar a coleção, os datasets aparecerão.
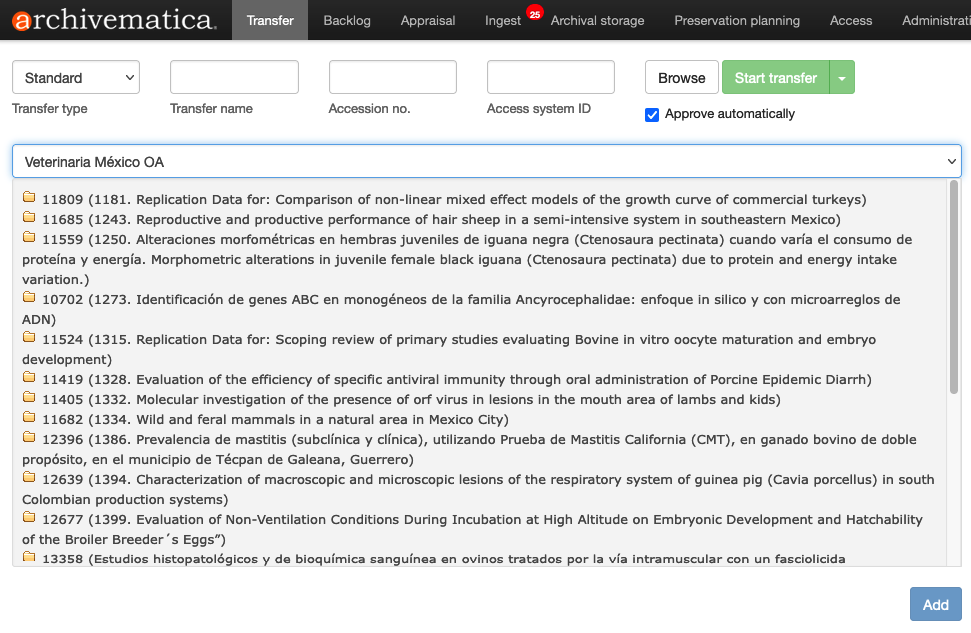
Selecione o dataset e clique no botão Add
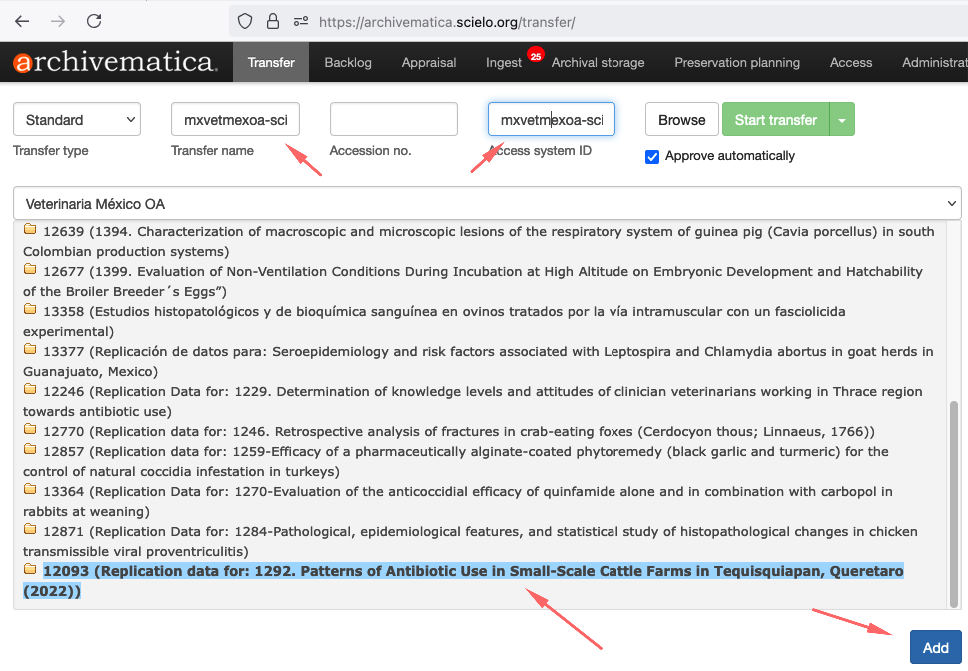
Importante que antes de pressionar o botão Start Transfer, execute o procedimento abaixo:
PREPARANDO O ATOM PARA RECEBER O DIP
Acesse https://atom.scielo.org/
A url criada foi https://atom.scielo.org/index.php/mxvetmexoa-scielodata-qbt2oa
Ao finalizar o procedimento de preparação do AtoM, clique no botão Start transfer para iniciar o processo.
Se não houver erro, o processo de ingestão iniciará.
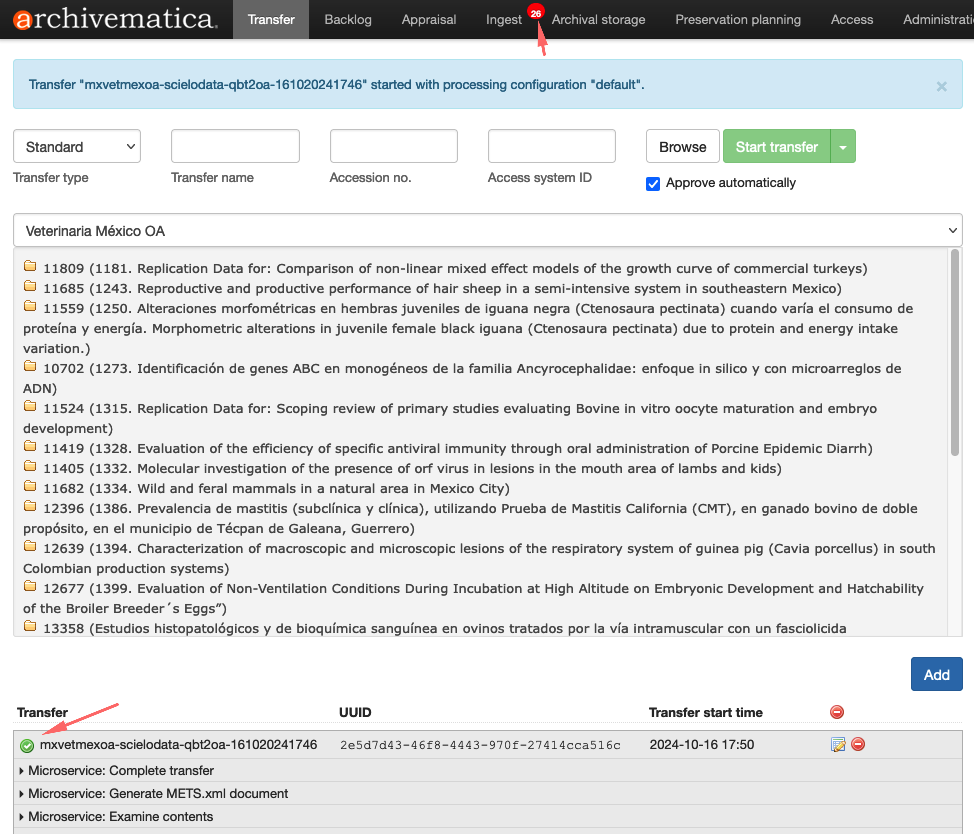
Depois que uma transferência é iniciada, ela aparece abaixo da área de preparação da transferência. Vários microsserviços executam o material transferido para prepará-lo para se tornar um SIP. A lista de microsserviços deve ser lida de baixo para cima.
No final do processo de transferência, o material transferido pode ser enviado para o backlog , onde pode ser armazenado até que você esteja pronto para transformá-lo em um AIP. O backlog também oferece aos usuários a chance de realizar tarefas de avaliação . Como alternativa, o usuário pode transformar o material transferido em um SIP e enviá-lo para a guia Ingest .
Você pode limpar a guia Transferência removendo transferências concluídas ou rejeitadas. Para obter mais informações, consulte Limpando a guia Transferir abaixo.
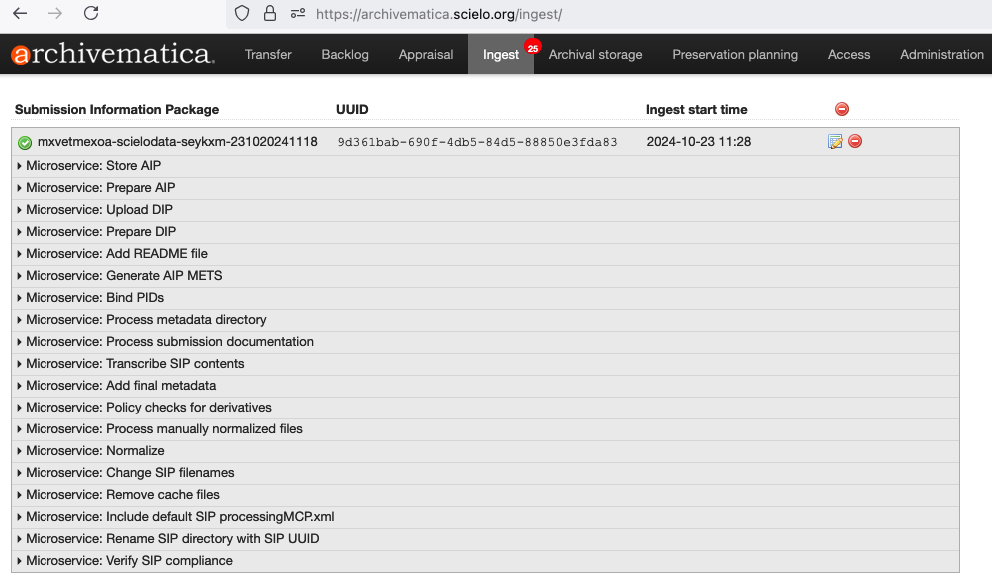
ALIMENTANDO A PLANILHA DE CONTROLE
Uma vez que o fluxo de ingest finalize, é necessário adicionar na planilha [ARCHIVEMATICA] PRESERVAÇÃO DIGITAL DATAVERSE o pacote que foi preservado. Cada aba da planilha corresponde a gestão dos conjuntos de dados que foram preservador.
Os campos a serem preenchidos são:
- DATA DE SUBMISSÃO: Corresponde quando o fluxo foi executado.
- ACRONIMO: Corresponde ao acrônimo da revista no Data SciELO
- DATASET (DOI): O identificador único do conjunto de dados
- TRANSFER NAME: Nome de indentificação de transferência
-
ACCESS SYSTEM ID: ID de acesso ao sistema.
-
UUID DO AIP: Identificador único do AIP.

-
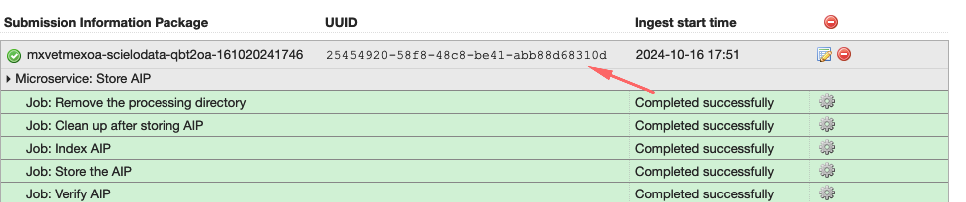
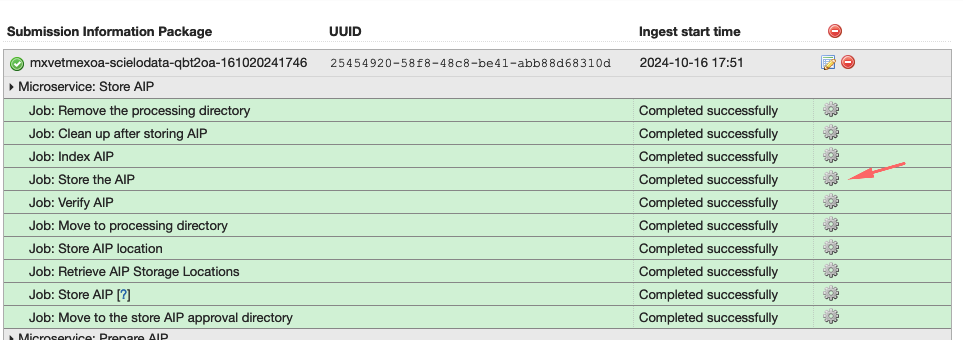
UUID DO REPLICATOR DIGITAL OCEAN: Clique em Job: Store de AIP e busque por replicas.
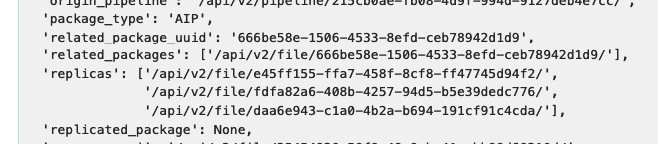
-
UUID DO REPLICATOR MINIO: Clique em Job: Store de AIP e busque por replicas.
-
UUID DO REPLICATOR AWS: Clique em Job: Store de AIP e busque por replicas.
-
CHECKSUM DO AIP
-
CHECKSUM DO DIP
-
AtoM: Corresponde a url do DIP no AtoM
FLUXO DE PRESERVAÇÃO DIGITAL DO SCIELO DATA USANDO O ARCHIVEMATICA E O ATOM
Esta documentação apresenta o fluxo de preservação digital do site SciELO Data. Onde os objetos digitais desse repositório fazem parte dos dados de pesquisa e metadados submetidos pelos autores.
Portanto, o objetivo desse manual é apresentar o fluxo de preservação digital do repositório de dados do SciELO (https://data.scielo.org) utilizando o Archivematica e o AtoM.
Os conjuntos de dados do repositórios são armazenados individualmente em pacotes de preservação chamado de BagITs. Eles são gerados mensalmente e armazenados em pastas com a seguinte identificação: scielodata-mês-ano. Exemplo: scielodata-agosto-2025.
E dentro dessa pasta haverá outras pastas que são pastas que divide o tamanho da soma dos bagits gerados. O tamanho considerado para cada uma dessa divisão é de 1GB, podendo ter pacotes individuais que podem ter mais de 1GB. Portanto, esse pode ser superior a regra proposta.
O fluxo de criação dos bagits e das pastas que os organizam está em https://documentacao.scielo.org/books/preservacao-digital/page/gerenciar-pacotes-bagit
Manual de uso
Acesse o site https://archivematica.scielo.org
Guia Transferência
A guia Transferência é o local onde muitos usuários iniciam o processo de transformar seus objetos digitais em Pacotes de Informações de Arquivamento (AIPs). Na guia Transferência, os usuários selecionam o material a ser preservado, nomeiam a transferência e iniciam o processo de transferência.
A seção na parte superior da guia Transferência é onde você encontrará materiais para transferência para o Archivematica. Existem quatro campos a serem preenchidos, os botões Browse e Start transfer e a caixa de seleção Approve automatically
- Tipo de transferência : o tipo de material que está sendo transferido. Consulte Tipos de transferência para obter mais informações.
- Nome da transferência : um nome para sua transferência. Este se tornará o nome do pacote de informações de arquivamento (AIP) resultante. Este é um campo obrigatório.
- Adesão no. : A inserção de um número de acesso para sua transferência resultará na cópia do número de acesso no arquivo AIP METS como um evento de registro. Não é usado para identificar ou procurar o AIP no Archivematica. Este campo é opcional.
- ID do sistema de acesso : inserir um campo de ID do sistema de acesso ao configurar sua transferência permite automatizar o processo de upload de um DIP para o AtoM. O Archivematica automaticamente captura esse valor quando alcançar o microsserviço DIP de upload. Consulte Carregar um DIP para AtoM para obter mais informações. Este campo é opcional.
- Procurar : O botão Procurar alterna para abrir o navegador de transferência. Isso permite que os usuários visualizem e naveguem pelos locais configurados da fonte de transferência. Para obter mais informações sobre como configurar locais de origem de transferência que o Archivematica pode acessar, consulte o Manual do administrador - Serviço de armazenamento . Selecionar um diretório e clicar em Adicionar adiciona o diretório de materiais à transferência.
- Iniciar transferência : depois de atribuir à sua transferência um nome e o material selecionado no navegador de transferências, o botão Iniciar transferência inicia os microsserviços de transferência.
- Aprovar automaticamente : se esta caixa estiver desmarcada, o Archivematica fará uma pausa no primeiro micros serviço, Aprovar transferência , e você terá a chance de confirmar que sua transferência foi configurada corretamente. Se a caixa estiver marcada, o Archivematica não fará uma pausa nesta etapa.
Quando a transferência é por dataset
O padrão de nome adotado para transferências dos conjuntos de dados do Data SciELO ficou:
<acrônimo do periódico no dataverse>-<identificador DOI>-<dia-mes-ano-hora-minuto>
Exemplo: mxvetmexoa-scielodata-qbt2oa-161020241746
Este exemplo corresponde ao conjunto de dados com a https://data.scielo.org/dataset.xhtml?persistentId=doi:10.48331/scielodata.QBT2OA
Para iniciar o processo de transferência, clique no botão Browse para listar as coleções. Selecione a coleção, conforme a imagem abaixo:
Ao selecionar a coleção, os datasets aparecerão.
Selecione o dataset e clique no botão Add
Importante que antes de pressionar o botão Start Transfer, execute o procedimento abaixo:
PREPARANDO O ATOM PARA RECEBER O DIP
Acesse https://atom.scielo.org/
A url criada foi https://atom.scielo.org/index.php/mxvetmexoa-scielodata-qbt2oa
Ao finalizar o procedimento de preparação do AtoM, clique no botão Start transfer para iniciar o processo.
Se não houver erro, o processo de ingestão iniciará.
Depois que uma transferência é iniciada, ela aparece abaixo da área de preparação da transferência. Vários microsserviços executam o material transferido para prepará-lo para se tornar um SIP. A lista de microsserviços deve ser lida de baixo para cima.
No final do processo de transferência, o material transferido pode ser enviado para o backlog , onde pode ser armazenado até que você esteja pronto para transformá-lo em um AIP. O backlog também oferece aos usuários a chance de realizar tarefas de avaliação . Como alternativa, o usuário pode transformar o material transferido em um SIP e enviá-lo para a guia Ingest .
Você pode limpar a guia Transferência removendo transferências concluídas ou rejeitadas. Para obter mais informações, consulte Limpando a guia Transferir abaixo.
ALIMENTANDO A PLANILHA DE CONTROLE
Uma vez que o fluxo de ingest finalize, é necessário adicionar na planilha [ARCHIVEMATICA] PRESERVAÇÃO DIGITAL DATAVERSE o pacote que foi preservado. Cada aba da planilha corresponde a gestão dos conjuntos de dados que foram preservador.
Os campos a serem preenchidos são:
- DATA DE SUBMISSÃO: Corresponde quando o fluxo foi executado.
- ACRONIMO: Corresponde ao acrônimo da revista no Data SciELO
- DATASET (DOI): O identificador único do conjunto de dados
- TRANSFER NAME: Nome de indentificação de transferência
-
ACCESS SYSTEM ID: ID de acesso ao sistema.
-
UUID DO AIP: Identificador único do AIP.
-
UUID DO REPLICATOR DIGITAL OCEAN: Clique em Job: Store de AIP e busque por replicas.
-
UUID DO REPLICATOR MINIO: Clique em Job: Store de AIP e busque por replicas.
-
UUID DO REPLICATOR AWS: Clique em Job: Store de AIP e busque por replicas.
-
CHECKSUM DO AIP
-
CHECKSUM DO DIP
-
AtoM: Corresponde a url do DIP no AtoM
Quando a transferência é feita por grupo de datasets
Esse tipo está considerando a transferência de datasets por grupos onde os pacotes SIP são BagITs criados mensalmente e que tem tamanho de 1GB cada grupo.
O padrão de nome adotado para transferências dos conjuntos de dados do Data SciELO ficou:
scielodata-<mês>-<ano>-<sequência>
Exemplo: scielodata-agosto-2025-01
Para iniciar o processo de transferência, clique no botão Browse para listar as coleções. Selecione a coleção, conforme a imagem abaixo:

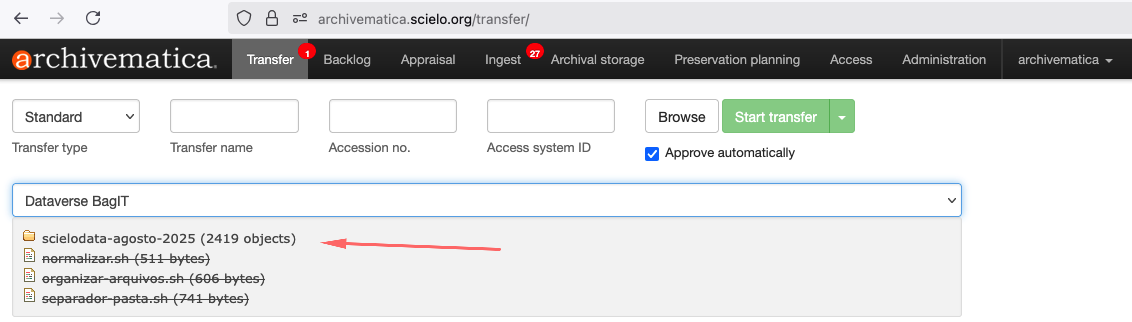
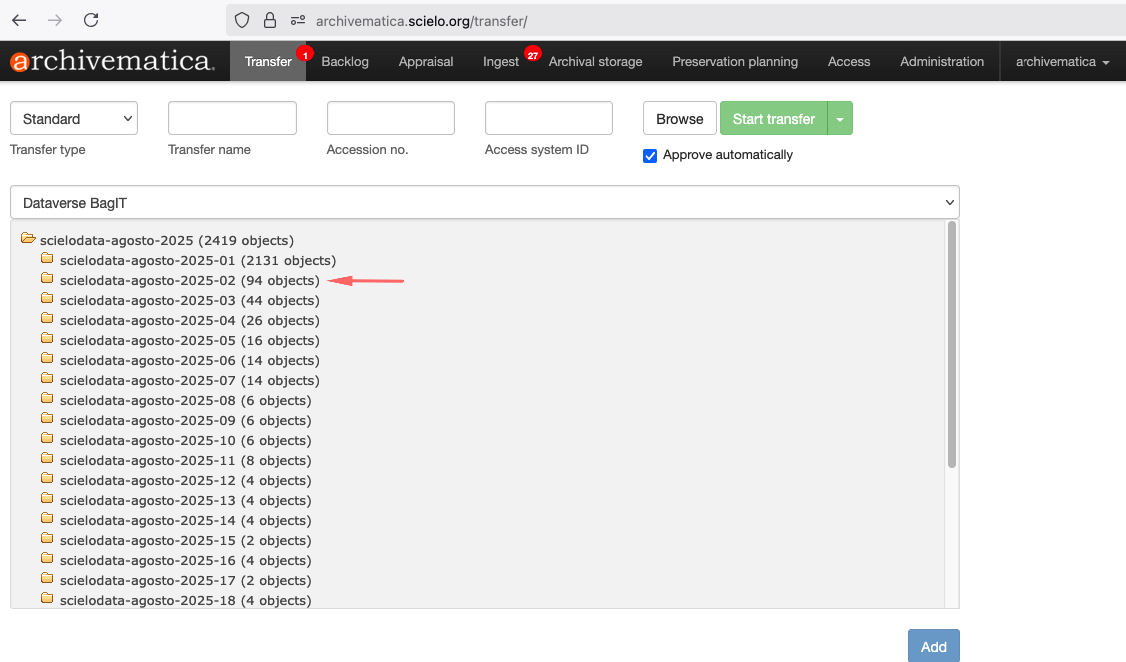
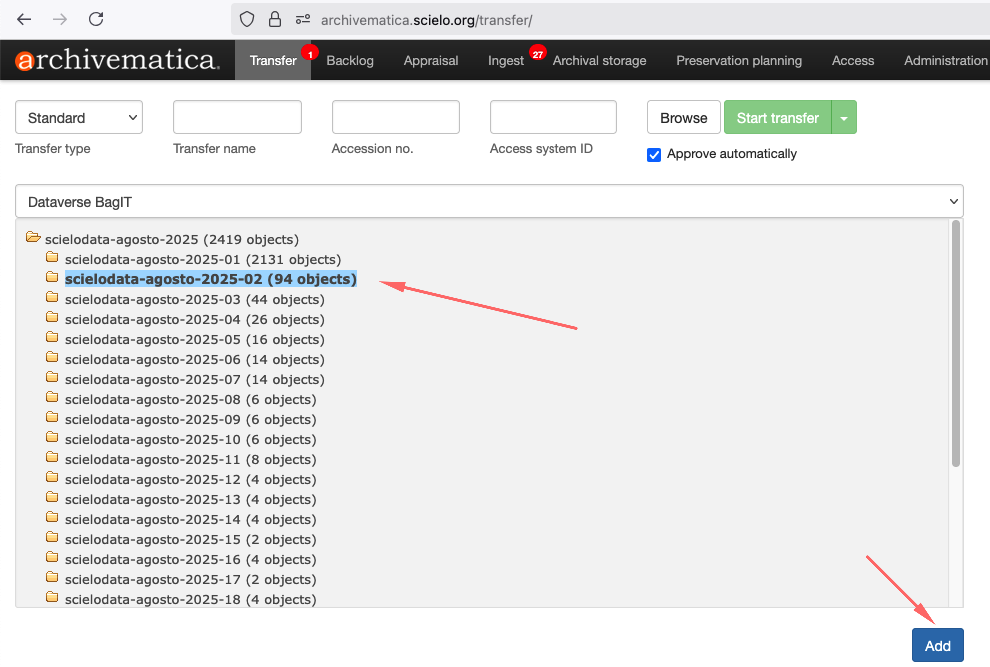
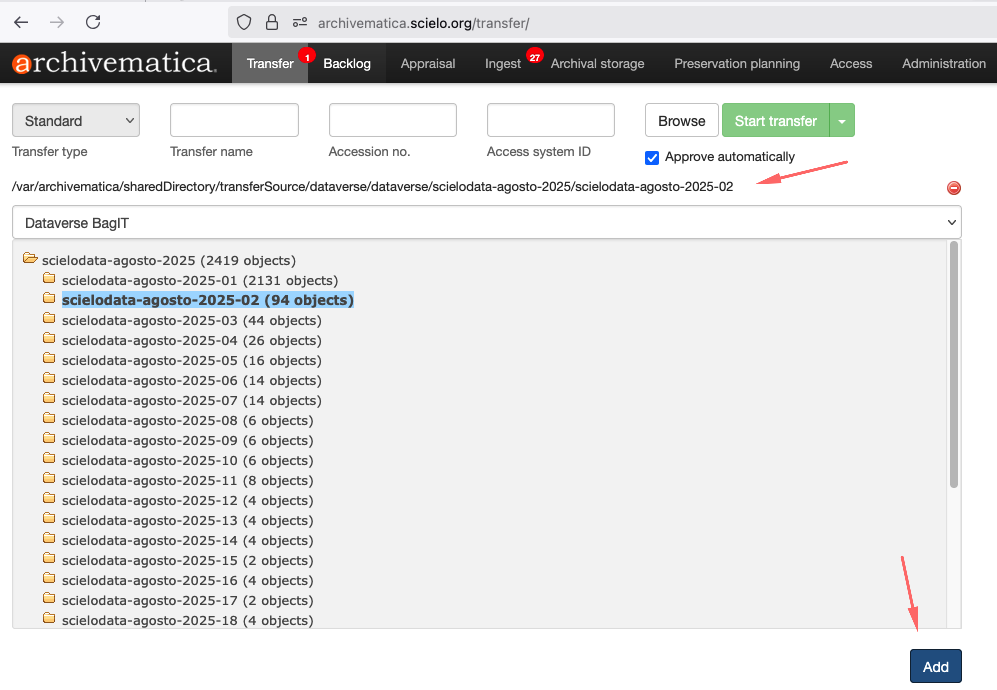
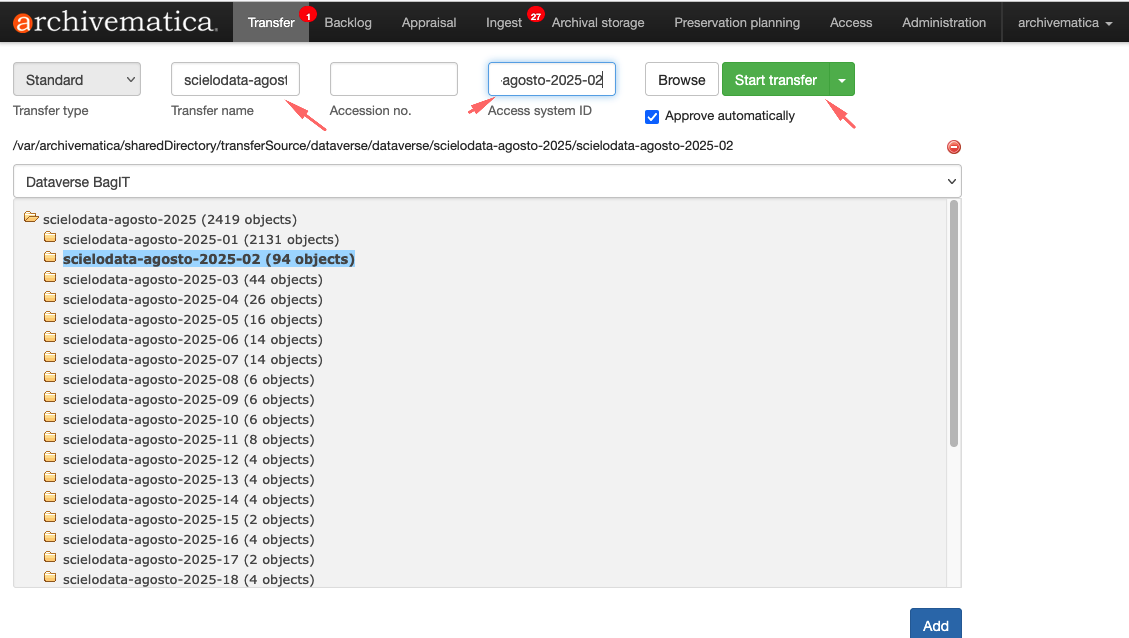
Adicionando no ATOM
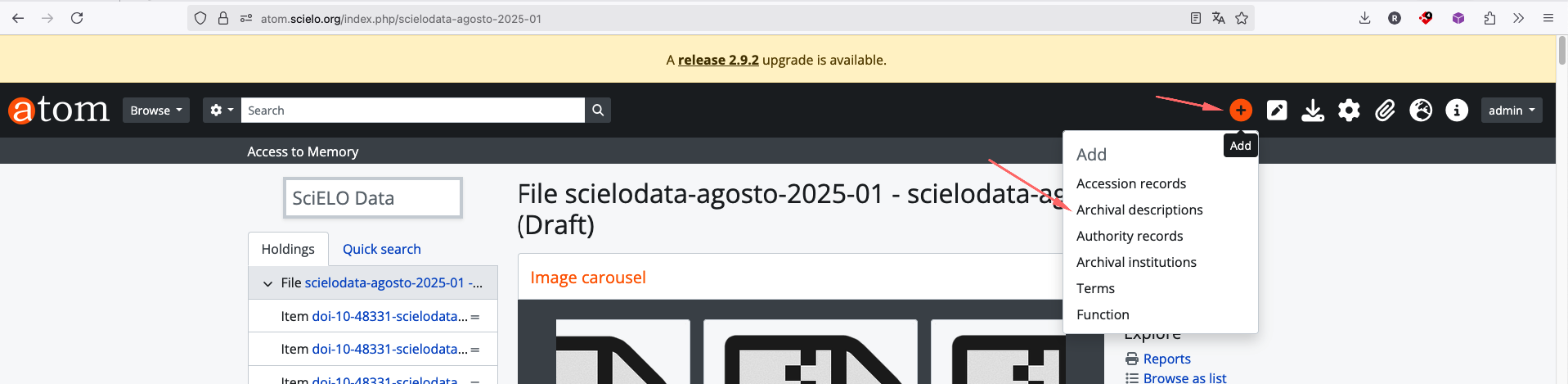
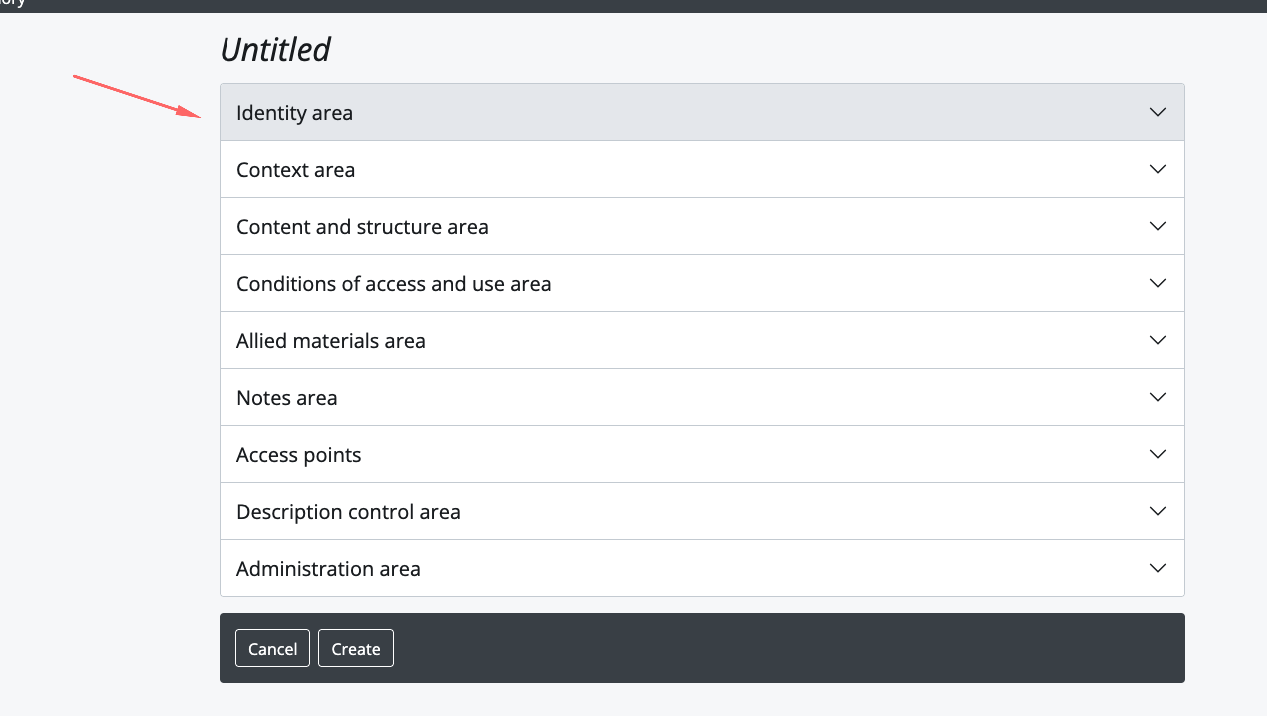
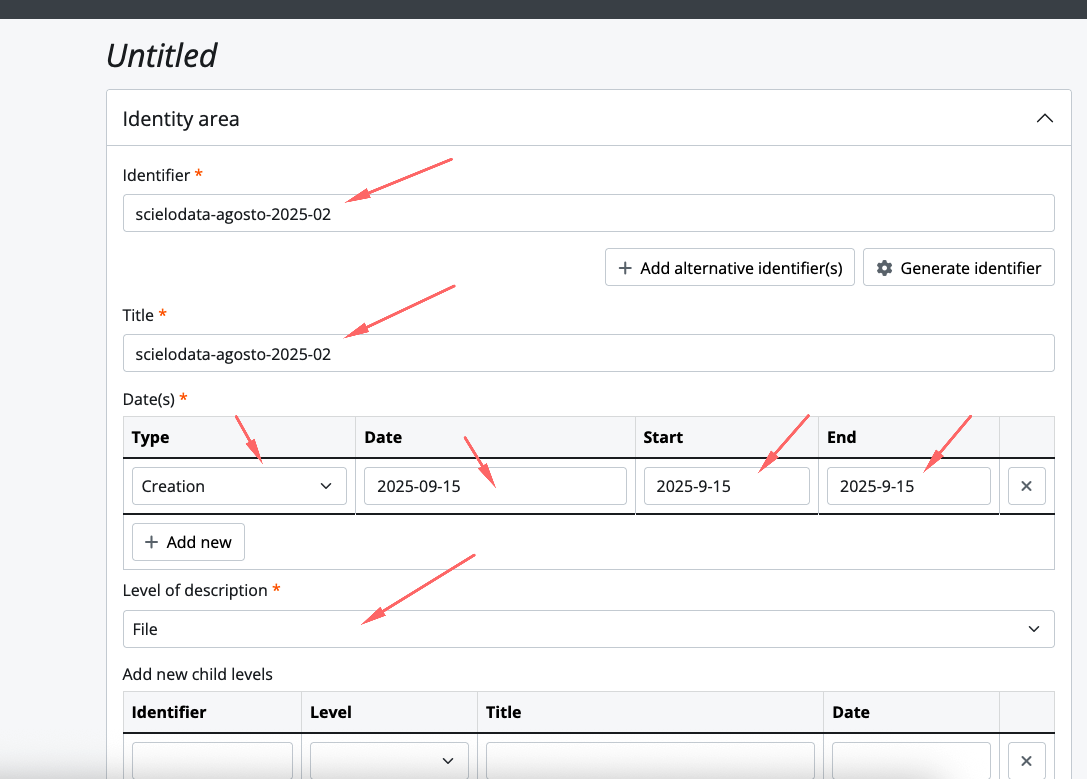
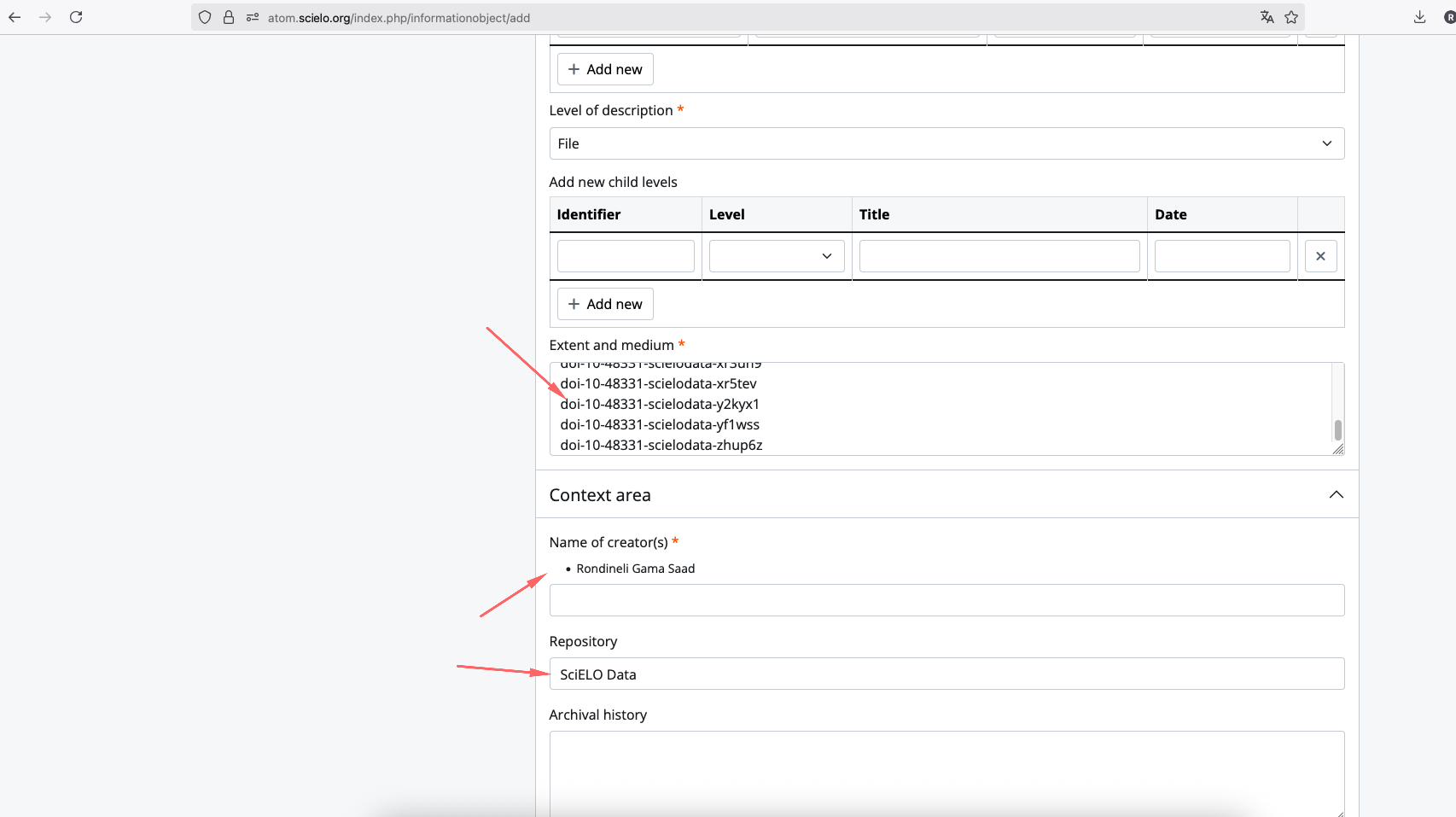
ATOM
INSTALANDO O ATOM NO UBUNTU 20.04 LTS
Este documento é baseado no Ubuntu 20.04 LTS (Focal Fossa). Depois de instalá-lo, você deve conseguir seguir as instruções descritas abaixo. Em particular, usaremos pacotes do Ubuntu que podem ser encontrados nos repositórios main e universe.
INSTALAR AS DEPENDÊNCIAS
MySQL
AtoM 2.8 requer MySQL 8.0 ou superior, pois usa expressões de tabela comuns. Além disso, tivemos resultados muito bons usando o Percona Server para MySQL 8.0, então não tenha medo e use-o se quiser!
sudo apt update
sudo apt install mysql-serverPor fim, vamos configurar nossos modos MySQL. O servidor MySQL pode operar em diferentes modos SQL, o que afeta a sintaxe SQL que o MySQL suporta e as verificações de validação de dados que ele executa.
Cole os seguintes valores em um novo arquivo em /etc/mysql/conf.d/mysqld.cnf e salve:
[mysqld]
sql_mode=ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION
optimizer_switch='block_nested_loop=off'Agora vamos reiniciar o MySQL:
sudo systemctl restart mysqlElasticsearch
Um servidor de busca baseado no Apache Lucene e desenvolvido em Java que trouxe ao AtoM muitos recursos avançados, desempenho e escalabilidade. Esta é provavelmente a maior mudança introduzida no AtoM 2.x e estamos satisfeitos com os resultados.
O Ubuntu não fornece um pacote, mas você pode baixá-lo diretamente do site do Elasticsearch se não conseguir baixá-lo usando o método a seguir.
Certifique-se de que o Java esteja instalado. Neste exemplo, usaremos o OpenJDK, mas a JVM da Oracle também funcionaria.
sudo apt install openjdk-11-jre-headless apt-transport-https software-properties-commonApós instalar o Java com sucesso, prossiga para instalar o Elasticsearch. Baixe e instale a chave de assinatura pública usada no repositório deles:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -Agora adicione o repositório deles:
echo "deb https://artifacts.elastic.co/packages/5.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-5.x.listPronto para ser instalado. Execute:
sudo apt update
sudo apt install elasticsearchInicie o serviço e configure-o para iniciar quando o sistema for inicializado.
sudo systemctl enable elasticsearch
sudo systemctl start elasticsearchPHP
O Ubuntu 20.04 agrupa o PHP 7.4, que é muito mais rápido do que versões mais antigas. O comando a seguir o instalará junto com o restante das extensões PHP necessárias pelo AtoM:
sudo apt install php-common php7.4-common php7.4-cli php7.4-curl php7.4-json php7.4-ldap php7.4-mysql php7.4-opcache php7.4-readline php7.4-xml php7.4-mbstring php7.4-xsl php7.4-zip php-apcu php-apcu-bcSe você estiver usando o Memcached como mecanismo de cache, você também precisará instalar o php-memcache:
sudo apt install php-memcacheServidor de trabalho Gearman
O servidor de trabalho Gearman é exigido pelo AtoM a partir da versão 2.2.
sudo apt install gearman-job-serverOutros pacotes
Para gerar auxílios de busca em PDF, o AtoM requer que o Apache FOP esteja instalado. Felizmente, o Apache FOP agora pode ser instalado diretamente de pacotes do Ubuntu usando o comando abaixo.
O comando especificado abaixo usa o parâmetro --no-install-recommends: isso é intencional e garante que apenas dependências sejam instaladas e não pacotes ‘recomendados’. Se --no-install-recommends não for especificado, o openjdk-8-jre será instalado como uma dependência para um dos pacotes recomendados. Como o openjdk-8-jre-headless já foi instalado na seção de instalação do Elasticsearch acima, queremos evitar a instalação do pacote openjdk-8-jre também.
sudo apt install --no-install-recommends fop libsaxon-java
Certifique-se de que o comando java padrão aponta para o binário java versão 11 (ignore erros):
sudo update-java-alternatives -s java-1.11.0-openjdk-amd64
Se você quiser que o AtoM seja capaz de processar objetos digitais em formatos como JPEG ou extrair o texto de seus documentos PDF, há certos pacotes que você precisa instalar. Eles não são obrigatórios, mas se forem encontrados no sistema, o AtoM os usará para produzir derivados de objetos digitais a partir de seus objetos mestres. para mais informações sobre cada um, consulte: Requisitos: outras dependências. O seguinte instalará todas as dependências recomendadas de uma vez:
sudo apt install imagemagick ghostscript poppler-utils ffmpeg
Baixar o AtoM
Agora que instalamos e configuramos todas as dependências, estamos prontos para baixar e instalar o AtoM em si. A maneira mais segura é instalar o AtoM a partir do tarball, que você pode encontrar na seção de download. No entanto, usuários experientes podem preferir verificar o código do nosso repositório público.
As instruções a seguir pressupõem que estamos instalando o AtoM em /usr/share/nginx e que você está usando o AtoM 2.8.0.
wget https://storage.accesstomemory.org/releases/atom-2.8.2.tar.gz
sudo mkdir /usr/share/nginx/atom
sudo tar xzf atom-2.8.2.tar.gz -C /usr/share/nginx/atom --strip 1Crie o banco de dados
Supondo que você esteja executando o MySQL no localhost, crie o banco de dados executando o seguinte comando usando a senha que você criou anteriormente:
sudo mysql -h localhost -u root -p -e "CREATE DATABASE atom CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;"
Observe que o banco de dados foi chamado de atom. Sinta-se à vontade para mudar seu nome.
Caso seu servidor MySQL não seja o mesmo que seu servidor web, substitua “localhost” pelo endereço do seu servidor MySQL.
Além disso, é sempre uma boa ideia criar um usuário MySQL específico para o AtoM para manter as coisas mais seguras. É assim que você pode criar um usuário chamado atom com senha 12345 e as permissões necessárias para o banco de dados criado acima.
sudo mysql -h localhost -u root -p -e "CREATE USER 'atom'@'localhost' IDENTIFIED BY '12345';"
sudo mysql -h localhost -u root -p -e "GRANT ALL PRIVILEGES ON atom.* TO 'atom'@'localhost';"Note que os privilégios INDEX, CREATE e ALTER são necessários somente durante o processo de instalação ou quando você estiver atualizando o AtoM para uma versão mais nova. Eles podem ser removidos do usuário quando você terminar a instalação ou você pode alterar o usuário usado pelo AtoM em config.php.
Execute o instalador
Agora você deve estar pronto para executar o instalador. É uma tarefa simples de interface de linha de comando que configura o AtoM de acordo com seu ambiente, adiciona as tabelas necessárias e os dados iniciais ao banco de dados criado recentemente e cria o índice Elasticsearch.
cd /usr/share/nginx/atom php symfony tools:install
A tarefa de instalação solicitará detalhes de configuração, como o local do seu servidor de banco de dados. Em alguns casos, ela pode fornecer valores padrão, como atom para o nome do banco de dados. Se você seguiu este documento à risca (incluindo a criação de um usuário de banco de dados diferente na etapa de configuração do banco de dados acima), é assim que você deve preencher a configuração:
- Database host:
localhost - Database port:
3306 - Database name:
atom - Database user:
atom - Database password:
12345 - Search host:
localhost - Search port:
9200 - Search index:
atom
É claro que alguns desses valores parecerão muito diferentes se você estiver executando o AtoM de forma distribuída, onde seus serviços como MySQL ou Elasticsearch estão sendo executados em máquinas separadas.
O restante da configuração pode ser preenchido conforme necessário:
Título do site
Descrição do site
URL base do site
E-mail do administrador
Nome de usuário do administrador
Senha do administrador
Você sempre pode alterar o título do site, a descrição do site e a URL base mais tarde em Admin > Configurações > Informações do site. Veja: Informações do site para mais informações. O e-mail, nome de usuário e senha do administrador também podem ser alterados por um administrador após a instalação por meio da interface do usuário - veja: Editar um usuário existente.
Configurar
Há várias configurações que só podem ser configuradas via linha de comando - por exemplo, o fuso horário padrão e a cultura do aplicativo. Dependendo dos seus requisitos locais, pode ser preferível configurar algumas delas agora. Para obter mais informações sobre essas configurações, consulte: Gerenciar arquivos de configuração do AtoM.
Considerações de segurança
Agora que o AtoM está configurado e instalado, reserve um momento para ler nossa seção de segurança, onde mostraremos como configurar o firewall no Ubuntu e outras opções na configuração do AtoM.
Nós encorajamos fortemente nossos usuários a configurar um firewall porque alguns dos serviços configurados não devem ser expostos na natureza, por exemplo, o Elasticsearch não foi projetado para ser acessível de redes não confiáveis e é um vetor de ataque comum.
Servidor
Existem muitos servidores web por aí capazes de trabalhar bem com PHP. O Apache é provavelmente o mais popular e nós gostamos dele, mas descobrimos que o Nginx se adapta muito melhor a ambientes de recursos limitados, enquanto também escala melhor e mais previsivelmente sob altas cargas. Você pode tentar outras soluções, mas a documentação a seguir se concentrará no Nginx e no PHP-FPM.
Além disso, o AtoM requer a configuração de um serviço de trabalhador Gearman.
Permissões do sistema de arquivos
Por padrão, o Nginx é executado como o usuário www-data. Existem alguns diretórios no AtoM que devem ser graváveis pelo servidor web. A maneira mais fácil de garantir isso é atualizar o proprietário do diretório AtoM e seu conteúdo executando:
sudo chown -R www-data:www-data /usr/share/nginx/atom
Se você estiver implantando o AtoM em um ambiente compartilhado, recomendamos que preste atenção às permissões atribuídas a outros. A seguir, um exemplo de como limpar todos os bits de modo para outros:
sudo chmod o= /usr/share/nginx/atom
Se você estiver planejando fazer uploads DIP do AM, verifique a seção do diretório de depósito do SWORD para definir as permissões desse diretório.
Implantação de workers
Gearman é usado no AtoM para dar suporte a tarefas assíncronas, algumas das quais são funcionalidades principais, como atualizar o status de publicação de uma hierarquia descritiva, mover descrições para um novo registro pai e muito mais. Um worker é apenas uma tarefa CLI que você pode executar em um terminal ou supervisionar com ferramentas específicas como upstart, supervisord ou systemd. O worker aguardará por jobs atribuídos pelo servidor de jobs.
Usaremos systemd para gerenciar o worker do AtoM; crie o seguinte arquivo de serviço /usr/lib/systemd/system/atom-worker.service:
[Unit]
Description=AtoM worker
After=network.target
# High interval and low restart limit to increase the possibility
# of hitting the rate limits in long running recurrent jobs.
StartLimitIntervalSec=24h
StartLimitBurst=3
[Install]
WantedBy=multi-user.target
[Service]
Type=simple
User=www-data
Group=www-data
WorkingDirectory=/usr/share/nginx/atom
ExecStart=/usr/bin/php7.4 -d memory_limit=-1 -d error_reporting="E_ALL" symfony jobs:worker
KillSignal=SIGTERM
Restart=on-failure
RestartSec=30Agora recarregue o systemd, habilite e inicie o AtoM worker:
sudo systemctl daemon-reload sudo systemctl enable atom-worker sudo systemctl start atom-worker
PHP-FPM
Nossa maneira favorita de implementar o AtoM é usando PHP-FPM, um gerenciador de processos que escala melhor do que outras soluções como FastCGI.
sudo apt install php7.4-fpm
Vamos adicionar um novo pool PHP para AtoM adicionando o seguinte conteúdo em um novo arquivo chamado /etc/php/7.4/fpm/pool.d/atom.conf:
[atom] ; The user running the application user = www-data group = www-data ; Use UNIX sockets if Nginx and PHP-FPM are running in the same machine listen = /run/php7.4-fpm.atom.sock listen.owner = www-data listen.group = www-data listen.mode = 0600 ; The following directives should be tweaked based in your hardware resources pm = dynamic pm.max_children = 30 pm.start_servers = 10 pm.min_spare_servers = 10 pm.max_spare_servers = 10 pm.max_requests = 200 chdir = / ; Some defaults for your PHP production environment ; A full list here: http://www.php.net/manual/en/ini.list.php php_admin_value[expose_php] = off php_admin_value[allow_url_fopen] = on php_admin_value[memory_limit] = 512M php_admin_value[max_execution_time] = 120 php_admin_value[post_max_size] = 72M php_admin_value[upload_max_filesize] = 64M php_admin_value[max_file_uploads] = 10 php_admin_value[cgi.fix_pathinfo] = 0 php_admin_value[display_errors] = off php_admin_value[display_startup_errors] = off php_admin_value[html_errors] = off php_admin_value[session.use_only_cookies] = 0 ; APC php_admin_value[apc.enabled] = 1 php_admin_value[apc.shm_size] = 64M php_admin_value[apc.num_files_hint] = 5000 php_admin_value[apc.stat] = 0 ; Zend OPcache php_admin_value[opcache.enable] = 1 php_admin_value[opcache.memory_consumption] = 192 php_admin_value[opcache.interned_strings_buffer] = 16 php_admin_value[opcache.max_accelerated_files] = 4000 php_admin_value[opcache.validate_timestamps] = 0 php_admin_value[opcache.fast_shutdown] = 1 ; This is a good place to define some environment variables, e.g. use ; ATOM_DEBUG_IP to define a list of IP addresses with full access to the ; debug frontend or ATOM_READ_ONLY if you want AtoM to prevent ; authenticated users env[ATOM_DEBUG_IP] = "10.10.10.10,127.0.0.1" env[ATOM_READ_ONLY] = "off"
The process manager has to be enabled and started:
sudo systemctl enable php7.4-fpm sudo systemctl start php7.4-fpm
If the service fails to start, make sure that the configuration file has been has been pasted properly. You can also check the syntax by running:
sudo php-fpm7.4 --test
If you are not planning to use the default PHP pool (www), feel free to remove it:
sudo rm /etc/php/7.4/fpm/pool.d/www.conf sudo systemctl restart php7.4-fpm
Nginx
In Ubuntu, the installation of Nginx is simple:
sudo apt install nginx
Warning
These instructions assume that the Nginx package is creating the directory /usr/share/nginx and that is the location where we are going to place the AtoM sources. However, we have been told this location may be different in certain environments (e.g. /var/www) or you may opt for a different location. If that is the case, please make sure that you update the configuration snippets that we share later in this document according to your location.
Nginx deploys a default server (aka VirtualHost, for Apache users) called default and you can find it in /etc/nginx/sites-available/default. In order to install AtoM you could edit the existing server block or add a new one. We are going to you show you how to do the latter:
sudo touch /etc/nginx/sites-available/atom sudo ln -sf /etc/nginx/sites-available/atom /etc/nginx/sites-enabled/atom sudo rm /etc/nginx/sites-enabled/default
We have now created the configuration file and linked it from sites-enabled/, which is the directory that Nginx will look for. This means that you could disable a site by removing its symlink from sites-enabled/ while keeping the original one under sites-available/, in case that you want to re-use it in the future. You can do this with the Nginx default server.
The following is a recommended server block for AtoM. Put the following contents in /etc/nginx/sites-available/atom.
Warning
This example listens for connections on port 80 using basic http without encryption.
While this is ok for testing AtoM locally on a private network, any public implementation of AtoM should be secured using TLS/SSL certificates such that your content is served over HTTPS.
The Mozilla SSL Configuration Generator is useful for assisting with adding the appropriate blocks to your Nginx configuration file.
upstream atom {
server unix:/run/php7.4-fpm.atom.sock;
}
server {
listen 80;
root /usr/share/nginx/atom;
# http://wiki.nginx.org/HttpCoreModule#server_name
# _ means catch any, but it's better if you replace this with your server
# name, e.g. archives.foobar.com
server_name _;
client_max_body_size 72M;
location ~* ^/(css|dist|js|images|plugins|vendor)/.*\.(css|png|jpg|js|svg|ico|gif|pdf|woff|ttf)$ {
}
location ~* ^/(downloads)/.*\.(pdf|xml|html|csv|zip|rtf)$ {
}
location ~ ^/(ead.dtd|favicon.ico|robots.txt|sitemap.*)$ {
}
location / {
try_files $uri /index.php?$args;
if (-f $request_filename) {
return 403;
}
}
location ~* /uploads/r/(.*)/conf/ {
}
location ~* ^/uploads/r/(.*)$ {
include /etc/nginx/fastcgi_params;
set $index /index.php;
fastcgi_param SCRIPT_FILENAME $document_root$index;
fastcgi_param SCRIPT_NAME $index;
fastcgi_pass atom;
}
location ~ ^/private/(.*)$ {
internal;
alias /usr/share/nginx/atom/$1;
}
location ~ ^/(index|qubit_dev)\.php(/|$) {
include /etc/nginx/fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_split_path_info ^(.+\.php)(/.*)$;
fastcgi_pass atom;
}
}
Agora você precisa habilitar e recarregar o Nginx:
sudo systemctl enable nginx sudo systemctl reload nginx
Comece a usar o AtoM
Parabéns! Sua nova instalação do AtoM 2.8 agora deve estar pronta para uso. Você pode acessá-la inserindo sua URL base em um navegador da web - os detalhes de login da conta do administrador serão aqueles que você inseriu ao configurar o instalador. Veja Introdução para mais informações sobre seus primeiros passos usando o AtoM.
Após implementar as alterações acima durante a configuração inicial, pode ser necessário limpar o cache e reiniciar o PHP-FPM para que as alterações entrem em vigor.
Se você encontrar quaisquer outros problemas, recomendamos consultar a documentação de Solução de problemas para obter sugestões sobre como resolver erros comuns.
REFERÊNCIAS
https://www.accesstomemory.org/pt-br/docs/2.8/admin-manual/installation/ubuntu/
https://www.accesstomemory.org/pt-br/docs/2.5/admin-manual/maintenance/cli-tools/
MIGRANDO O ATOM 2.5.3 PARA 2.8.2
Para migrar para a versão 2.8.2 é necessário Ubuntu 20.04 LTS. A versão 2.5.3 está instalado no Ubuntu 18.04. Iremos aproveitar para atualizar e migrar para um novo servidor.
INSTALAR AS DEPENDÊNCIAS
MySQL
AtoM 2.8 requer MySQL 8.0 ou superior, pois usa expressões de tabela comuns. Além disso, tivemos resultados muito bons usando o Percona Server para MySQL 8.0, então não tenha medo e use-o se quiser!
sudo apt update
sudo apt install mysql-serverPor fim, vamos configurar nossos modos MySQL. O servidor MySQL pode operar em diferentes modos SQL, o que afeta a sintaxe SQL que o MySQL suporta e as verificações de validação de dados que ele executa.
Cole os seguintes valores em um novo arquivo em /etc/mysql/conf.d/mysqld.cnf e salve:
[mysqld]
sql_mode=ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION
optimizer_switch='block_nested_loop=off'Agora vamos reiniciar o MySQL:
sudo systemctl restart mysqlElasticsearch
Um servidor de busca baseado no Apache Lucene e desenvolvido em Java que trouxe ao AtoM muitos recursos avançados, desempenho e escalabilidade. Esta é provavelmente a maior mudança introduzida no AtoM 2.x e estamos satisfeitos com os resultados.
O Ubuntu não fornece um pacote, mas você pode baixá-lo diretamente do site do Elasticsearch se não conseguir baixá-lo usando o método a seguir.
Certifique-se de que o Java esteja instalado. Neste exemplo, usaremos o OpenJDK, mas a JVM da Oracle também funcionaria.
sudo apt install openjdk-11-jre-headless apt-transport-https software-properties-commonApós instalar o Java com sucesso, prossiga para instalar o Elasticsearch. Baixe e instale a chave de assinatura pública usada no repositório deles:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -Agora adicione o repositório deles:
echo "deb https://artifacts.elastic.co/packages/5.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-5.x.listPronto para ser instalado. Execute:
sudo apt update
sudo apt install elasticsearchInicie o serviço e configure-o para iniciar quando o sistema for inicializado.
sudo systemctl enable elasticsearch
sudo systemctl start elasticsearchPHP
O Ubuntu 20.04 agrupa o PHP 7.4, que é muito mais rápido do que versões mais antigas. O comando a seguir o instalará junto com o restante das extensões PHP necessárias pelo AtoM:
sudo apt install php-common php7.4-common php7.4-cli php7.4-curl php7.4-json php7.4-ldap php7.4-mysql php7.4-opcache php7.4-readline php7.4-xml php7.4-mbstring php7.4-xsl php7.4-zip php-apcu php-apcu-bcSe você estiver usando o Memcached como mecanismo de cache, você também precisará instalar o php-memcache:
sudo apt install php-memcacheServidor de trabalho Gearman
O servidor de trabalho Gearman é exigido pelo AtoM a partir da versão 2.2.
sudo apt install gearman-job-serverOutros pacotes
Para gerar auxílios de busca em PDF, o AtoM requer que o Apache FOP esteja instalado. Felizmente, o Apache FOP agora pode ser instalado diretamente de pacotes do Ubuntu usando o comando abaixo.
O comando especificado abaixo usa o parâmetro --no-install-recommends: isso é intencional e garante que apenas dependências sejam instaladas e não pacotes ‘recomendados’. Se --no-install-recommends não for especificado, o openjdk-8-jre será instalado como uma dependência para um dos pacotes recomendados. Como o openjdk-8-jre-headless já foi instalado na seção de instalação do Elasticsearch acima, queremos evitar a instalação do pacote openjdk-8-jre também.
sudo apt install --no-install-recommends fop libsaxon-java
Certifique-se de que o comando java padrão aponta para o binário java versão 11 (ignore erros):
sudo update-java-alternatives -s java-1.11.0-openjdk-amd64
Se você quiser que o AtoM seja capaz de processar objetos digitais em formatos como JPEG ou extrair o texto de seus documentos PDF, há certos pacotes que você precisa instalar. Eles não são obrigatórios, mas se forem encontrados no sistema, o AtoM os usará para produzir derivados de objetos digitais a partir de seus objetos mestres. para mais informações sobre cada um, consulte: Requisitos: outras dependências. O seguinte instalará todas as dependências recomendadas de uma vez:
sudo apt install imagemagick ghostscript poppler-utils ffmpeg
Baixar o AtoM
Agora que instalamos e configuramos todas as dependências, estamos prontos para baixar e instalar o AtoM em si. A maneira mais segura é instalar o AtoM a partir do tarball, que você pode encontrar na seção de download. No entanto, usuários experientes podem preferir verificar o código do nosso repositório público.
As instruções a seguir pressupõem que estamos instalando o AtoM em /usr/share/nginx e que você está usando o AtoM 2.8.0.
wget https://storage.accesstomemory.org/releases/atom-2.8.2.tar.gz
sudo mkdir /usr/share/nginx/atom
sudo tar xzf atom-2.2.0.tar.gz -C /usr/share/nginx/atom --strip 1Crie o banco de dados
Supondo que você esteja executando o MySQL no localhost, crie o banco de dados executando o seguinte comando usando a senha que você criou anteriormente:
sudo mysql -h localhost -u root -p -e "CREATE DATABASE atom CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;"Observe que o banco de dados foi chamado de atom. Sinta-se à vontade para mudar seu nome.
Caso seu servidor MySQL não seja o mesmo que seu servidor web, substitua “localhost” pelo endereço do seu servidor MySQL.
Além disso, é sempre uma boa ideia criar um usuário MySQL específico para o AtoM para manter as coisas mais seguras. É assim que você pode criar um usuário chamado atom com senha 12345 e as permissões necessárias para o banco de dados criado acima.
sudo mysql -h localhost -u root -p -e "CREATE USER 'atom'@'localhost' IDENTIFIED BY '<omitida>';"
sudo mysql -h localhost -u root -p -e "GRANT ALL PRIVILEGES ON atom.* TO 'atom'@'localhost';"Note que os privilégios INDEX, CREATE e ALTER são necessários somente durante o processo de instalação ou quando você estiver atualizando o AtoM para uma versão mais nova. Eles podem ser removidos do usuário quando você terminar a instalação ou você pode alterar o usuário usado pelo AtoM em config.php.
Restaurando a base do banco de dados
Importante lembrar que é necessário o dump do banco para realizar a restauração.
sudo mysql -h localhost -u root -p atom < ~/atom.sqlMIGRANDO O INDICE NO ELASTICSEARCH
CONFIGURANDO O CAMINHO DO REPOSITÓRIO
O repositório dos snapshots no SciELO é um ponto de montagem NFS. Este ponto NFS deve ser montado no novo servidor. Mas antes instale o pacote nfs-utils:
sudo yum install nfs-utils -yCrie o diretório do repositório:
sudo mkdir /var/lib/elasticsearch/backup-repoConfigure o /etc/fstab para persistir:
storage-scielo-251.scielo.org:/atom_es_bkp /var/lib/elasticsearch/backup-repo nfs vers=4,rsize=8192,wsize=8192,timeo=14,intr 0 0Agora basta montar:
sudo systemctl daemon-reload
sudo mount -aADICIONADO O ELASTICSEARCH NA CONFIGURAÇÃO
Edite o arquivo /etc/elasticsearch/elasticsearch.yml e adicione a linha abaixo de path.logs:
path.repo: /var/lib/elasticsearch/backup-repoReinicie o elasticsearch
sudo systemctl restart elasticsearchDevemos garantir que o usuário elasticsearch seja o dono do diretório /var/lib/elasticsearch/backup-repo:
sudo chown elasticsearch. -R /var/lib/elasticsearch/backup-repoCRIANDO O REPOSITÓRIO
curl -XPUT -H 'Content-Type: application/json' 'http://localhost:9200/_snapshot/es_backup_atom' -d '{
"type": "fs",
"settings": {
"compress" : true,
"location": "/var/lib/elasticsearch/backup-repo/es_backup_atom"
}
}'Consulte o repositório:
curl -X GET "localhost:9200/_cat/snapshots/es_backup_atom?v&s=id&pretty"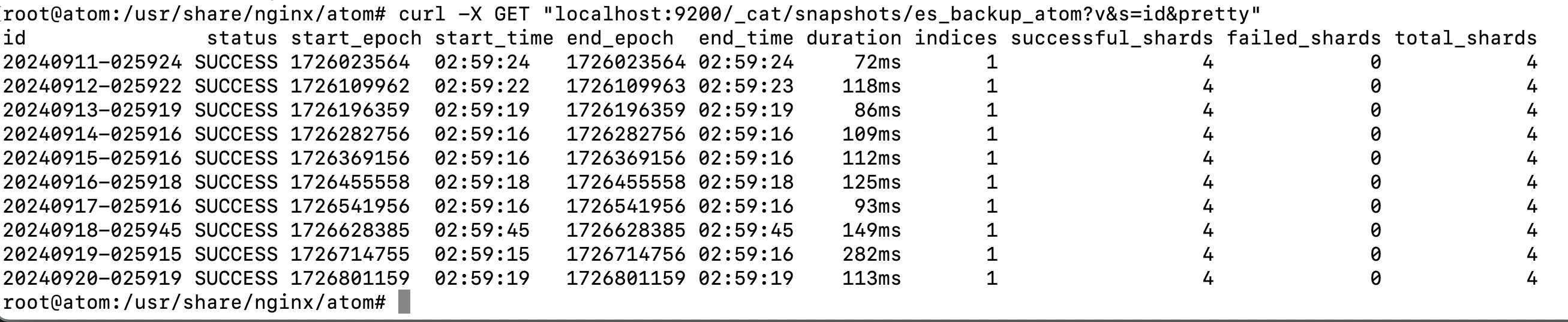
RESTAURANDO O ÚLTIMO SNAPSHOT
curl -X POST "localhost:9200/_snapshot/es_backup_atom/20240920-025919/_restore?pretty"LISTANDO OS INDICES RESTAURADOS
curl -X GET "http://localhost:9200/_cat/indices?v"
Baixar o AtoM
Agora que instalamos e configuramos todas as dependências, estamos prontos para baixar e instalar o AtoM em si. A maneira mais segura é instalar o AtoM a partir do tarball, que você pode encontrar na seção de download. No entanto, usuários experientes podem preferir verificar o código do nosso repositório público.
As instruções a seguir pressupõem que estamos instalando o AtoM em /usr/share/nginx e que você está usando o AtoM 2.8.0.
wget https://storage.accesstomemory.org/releases/atom-2.8.2.tar.gz
sudo mkdir /usr/share/nginx/atom-new
sudo tar xzf atom-2.2.0.tar.gz -C /usr/share/nginx/atom-new --strip 1Copie seus dados antigos
Agora, vamos copiar o conteúdo dos diretórios antigos de uploads e downloads, bem como o banco de dados. Vamos primeiro mover a instalação 2.5.3 renomeando:
sudo mv /usr/share/nginx/atom /usr/share/nginx/atom-oldVamos mover a nova versão:
sudo mv /usr/share/nginx/atom-new /usr/share/nginx/atomVamos copiar a pasta uploads e downloads para a nova instalação:
rsync -av /usr/share/nginx/atom-old/uploads/ /usr/share/nginx/atom/uploads/
rsync -av /usr/share/nginx/atom-old/downloads/ /usr/share/nginx/atom/downloads/Executando a tarefa de atualização
Esta é talvez a etapa mais crítica no processo de atualização. Se você encontrar algum erro, consulte nosso Fórum de Usuários ou, se não encontrar uma solução, sinta-se à vontade para postar uma pergunta lá você mesmo. Também tentaremos adicionar ao nosso FAQ conforme recebermos feedback, para ajudar os usuários a solucionar quaisquer problemas de atualização encontrados.
cd /usr/share/nginx/atom
php -d memory_limit=-1 symfony tools:upgrade-sqlRegenerar a referência do objeto digital e as imagens em miniatura
Primeiro, certifique-se de que você não alterou o diretório (/usr/share/nginx/atom).
Agora, execute a tarefa regen-derivatives:
php symfony digitalobject:regen-derivatives
Reconstruir índice de pesquisa e limpar cache
Para que todas essas alterações entrem em vigor, você precisará reindexar os arquivos que importou para seu banco de dados e limpar o cache do aplicativo.
Primeiro, reconstrua o índice de pesquisa:
php -d memory_limit=-1 symfony search:populate
Resultado:
Index populated with 1214 documents in 15.7 seconds.
The following errors have been encountered:
Couldn't find information object (id: 2705)
Please, contact an administrator.Em seguida, limpe o cache para remover quaisquer dados desatualizados do aplicativo:
php symfony cc
Permissões do sistema de arquivos
Por padrão, o Nginx é executado como o usuário www-data. Existem alguns diretórios no AtoM que devem ser graváveis pelo servidor web. A maneira mais fácil de garantir isso é atualizar o proprietário do diretório AtoM e seu conteúdo executando:
sudo chown -R www-data:www-data /usr/share/nginx/atom
Se você estiver implantando o AtoM em um ambiente compartilhado, recomendamos que preste atenção às permissões atribuídas a outros. A seguir, um exemplo de como limpar todos os bits de modo para outros:
sudo chmod o= /usr/share/nginx/atom
Se você estiver planejando fazer uploads DIP do AM, verifique a seção do diretório de depósito do SWORD para definir as permissões desse diretório.
Implantação de workers
Gearman é usado no AtoM para dar suporte a tarefas assíncronas, algumas das quais são funcionalidades principais, como atualizar o status de publicação de uma hierarquia descritiva, mover descrições para um novo registro pai e muito mais. Um worker é apenas uma tarefa CLI que você pode executar em um terminal ou supervisionar com ferramentas específicas como upstart, supervisord ou systemd. O worker aguardará por jobs atribuídos pelo servidor de jobs.
Usaremos systemd para gerenciar o worker do AtoM; crie o seguinte arquivo de serviço /usr/lib/systemd/system/atom-worker.service:
[Unit]
Description=AtoM worker
After=network.target
# High interval and low restart limit to increase the possibility
# of hitting the rate limits in long running recurrent jobs.
StartLimitIntervalSec=24h
StartLimitBurst=3
[Install]
WantedBy=multi-user.target
[Service]
Type=simple
User=www-data
Group=www-data
WorkingDirectory=/usr/share/nginx/atom
ExecStart=/usr/bin/php7.4 -d memory_limit=-1 -d error_reporting="E_ALL" symfony jobs:worker
KillSignal=SIGTERM
Restart=on-failure
RestartSec=30Agora recarregue o systemd, habilite e inicie o AtoM worker:
sudo systemctl daemon-reload sudo systemctl enable atom-worker sudo systemctl start atom-worker
PHP-FPM
Nossa maneira favorita de implementar o AtoM é usando PHP-FPM, um gerenciador de processos que escala melhor do que outras soluções como FastCGI.
sudo apt install php7.4-fpm
Vamos adicionar um novo pool PHP para AtoM adicionando o seguinte conteúdo em um novo arquivo chamado /etc/php/7.4/fpm/pool.d/atom.conf:
[atom] ; The user running the application user = www-data group = www-data ; Use UNIX sockets if Nginx and PHP-FPM are running in the same machine listen = /run/php7.4-fpm.atom.sock listen.owner = www-data listen.group = www-data listen.mode = 0600 ; The following directives should be tweaked based in your hardware resources pm = dynamic pm.max_children = 30 pm.start_servers = 10 pm.min_spare_servers = 10 pm.max_spare_servers = 10 pm.max_requests = 200 chdir = / ; Some defaults for your PHP production environment ; A full list here: http://www.php.net/manual/en/ini.list.php php_admin_value[expose_php] = off php_admin_value[allow_url_fopen] = on php_admin_value[memory_limit] = 512M php_admin_value[max_execution_time] = 120 php_admin_value[post_max_size] = 72M php_admin_value[upload_max_filesize] = 64M php_admin_value[max_file_uploads] = 10 php_admin_value[cgi.fix_pathinfo] = 0 php_admin_value[display_errors] = off php_admin_value[display_startup_errors] = off php_admin_value[html_errors] = off php_admin_value[session.use_only_cookies] = 0 ; APC php_admin_value[apc.enabled] = 1 php_admin_value[apc.shm_size] = 64M php_admin_value[apc.num_files_hint] = 5000 php_admin_value[apc.stat] = 0 ; Zend OPcache php_admin_value[opcache.enable] = 1 php_admin_value[opcache.memory_consumption] = 192 php_admin_value[opcache.interned_strings_buffer] = 16 php_admin_value[opcache.max_accelerated_files] = 4000 php_admin_value[opcache.validate_timestamps] = 0 php_admin_value[opcache.fast_shutdown] = 1 ; This is a good place to define some environment variables, e.g. use ; ATOM_DEBUG_IP to define a list of IP addresses with full access to the ; debug frontend or ATOM_READ_ONLY if you want AtoM to prevent ; authenticated users env[ATOM_DEBUG_IP] = "10.10.10.10,127.0.0.1" env[ATOM_READ_ONLY] = "off"
The process manager has to be enabled and started:
sudo systemctl enable php7.4-fpm sudo systemctl start php7.4-fpm
If the service fails to start, make sure that the configuration file has been has been pasted properly. You can also check the syntax by running:
sudo php-fpm7.4 --test
If you are not planning to use the default PHP pool (www), feel free to remove it:
sudo rm /etc/php/7.4/fpm/pool.d/www.conf sudo systemctl restart php7.4-fpm
Nginx
In Ubuntu, the installation of Nginx is simple:
sudo apt install nginxThese instructions assume that the Nginx package is creating the directory /usr/share/nginx and that is the location where we are going to place the AtoM sources. However, we have been told this location may be different in certain environments (e.g. /var/www) or you may opt for a different location. If that is the case, please make sure that you update the configuration snippets that we share later in this document according to your location.
Nginx deploys a default server (aka VirtualHost, for Apache users) called default and you can find it in /etc/nginx/sites-available/default. In order to install AtoM you could edit the existing server block or add a new one. We are going to you show you how to do the latter:
sudo touch /etc/nginx/sites-available/atom sudo ln -sf /etc/nginx/sites-available/atom /etc/nginx/sites-enabled/atom sudo rm /etc/nginx/sites-enabled/default
We have now created the configuration file and linked it from sites-enabled/, which is the directory that Nginx will look for. This means that you could disable a site by removing its symlink from sites-enabled/ while keeping the original one under sites-available/, in case that you want to re-use it in the future. You can do this with the Nginx default server.
The following is a recommended server block for AtoM. Put the following contents in /etc/nginx/sites-available/atom.
Warning
This example listens for connections on port 80 using basic http without encryption.
While this is ok for testing AtoM locally on a private network, any public implementation of AtoM should be secured using TLS/SSL certificates such that your content is served over HTTPS.
The Mozilla SSL Configuration Generator is useful for assisting with adding the appropriate blocks to your Nginx configuration file.
upstream atom {
server unix:/run/php7.4-fpm.atom.sock;
}
server {
listen 80;
root /usr/share/nginx/atom;
# http://wiki.nginx.org/HttpCoreModule#server_name
# _ means catch any, but it's better if you replace this with your server
# name, e.g. archives.foobar.com
server_name _;
client_max_body_size 72M;
location ~* ^/(css|dist|js|images|plugins|vendor)/.*\.(css|png|jpg|js|svg|ico|gif|pdf|woff|ttf)$ {
}
location ~* ^/(downloads)/.*\.(pdf|xml|html|csv|zip|rtf)$ {
}
location ~ ^/(ead.dtd|favicon.ico|robots.txt|sitemap.*)$ {
}
location / {
try_files $uri /index.php?$args;
if (-f $request_filename) {
return 403;
}
}
location ~* /uploads/r/(.*)/conf/ {
}
location ~* ^/uploads/r/(.*)$ {
include /etc/nginx/fastcgi_params;
set $index /index.php;
fastcgi_param SCRIPT_FILENAME $document_root$index;
fastcgi_param SCRIPT_NAME $index;
fastcgi_pass atom;
}
location ~ ^/private/(.*)$ {
internal;
alias /usr/share/nginx/atom/$1;
}
location ~ ^/(index|qubit_dev)\.php(/|$) {
include /etc/nginx/fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_split_path_info ^(.+\.php)(/.*)$;
fastcgi_pass atom;
}
}
Agora você precisa habilitar e recarregar o Nginx:
sudo systemctl enable nginx sudo systemctl reload nginx
CRIANDO O USUÁRIO PARA INTEGRAR O ATOM AO ARCHIVEMATICA
useradd -c "Archivematica User" archivematicaAltere o bash editando o /etc/passwd
archivematica:x:1001:1001:Archivematica User:/home/archivematica:/usr/bin/rsshAjuste a permissão do diretório /DIPs que foi copiado do servidor de origem:
chown -R archivematica. /DIPs/CRIANDO A RELAÇÃO DE CONFIANÇA
No diretório home (/home/archivematica) dentro da pasta .ssh crie o arquivo authorized_keys
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDLmna1yXOa5xFRuTgx8HeaGxqy3b3H5EksPIeVm+pfSElbrs8gnnrz3vFzYLve2csLP0QDnq6mq9zS8O1h5OAKNN1oKJ8C1o0kvcB7XDHwSqAU8SJ48c3mTWl7OSqRUznyvdXFL37qnpeF7SA0BUVYRb1CIrpiZLg6btrV6tLgcdF3LnqvJUuWjLXLOhIj6dU7TW9h1HpLB2ZmpkkWc0LIY1kUrJA/w9w2HnE7Qc0UjEldlhOMN/Bpc2wLi9Cs3ZA6iRwnbV7f3M86R/0ZspRfNA6lg0ZId44AGS5OxB5QhU8nLsfXfj2PgCeUtWlwEQVPTE055crz8JlxXI7P2Rnl archivematica@archivematica.scielo.orgAjuste a permissão:
chmod 400 /home/archivematica/.ssh/authorized_keysGERENCIAR PACOTES BAGIT
CRIAR PACOTES BAGITS POR DATASETS
sudo su - glassfish
curl -H X-Dataverse-key:$API_TOKEN http://localhost:8080/api/datasets/:persistentId/?persistentId=doi:10.48331/SCIELODATA.RJ1HZO
export ID=19300
export API_TOKEN='YOUR API TOKEN'
curl -X POST -H "X-Dataverse-key: $API_TOKEN" http://localhost:8080/api/admin/submitDatasetVersionToArchive/$ID/1.0CRIAR PACOTES BAGITS DE TODOS OS DATASETS
Essa execução é feito uma vez por mês. Os pacotes bagits são gerados no diretório /preservacao/dataverse que é um ponto de montagem nfs em storage-scielo-232.scielo.org:/archivematica_transfersource
export API_TOKEN='MEU TOKEN'
curl -X POST -H "X-Dataverse-key: $API_TOKEN" 'http://localhost:8080/api/admin/archiveAllUnarchivedDatasetVersions'Uma vez que os pacotes são gerados precisamos organizar cada um dos datasets em pastas individuais. Para isso precisamos executar o script organizar-arquivos.sh que irá criar apenas as pastas
cd /preservacao/dataverse
sh -x organizar-arquivos.sh Uma vez criadas as pastas, precisamos ajustar o nome da pasta, pois ele fica com a versão no final e o desejado é ter apenas o nome:
cd /preservacao/dataverse
sh -x normalizar.sh
Pode ser que o mês tenha muitos arquivos e que represente muito gigabyte como foi o caso de agosto de 2025 que chegou a 29Gb. Precisamos dividir elas em tamanho de 1GB. Foi criado um script chamado separador-pasta.sh. Antes de executar o script, crie a pasta que identifique o mês e o ano. Exemplo: scielodata-setembro-2025
mkdir /preservacao/dataverse/scielodata-setembro-2025Agora edite o arquivo para ajustar a variável ORIGEM e A PREFIXO:
#!/bin/bash
# Diretório de origem
ORIGEM="/preservacao/dataverse/scielodata-setembro-2025"
# Prefixo das novas pastas
PREFIXO="scielodata-setembro-2025"
cd "$ORIGEM" || exit 1
i=1
total=0
destino=$(printf "%s-%02d" "$PREFIXO" "$i")
mkdir -p "$destino"
# Lista subpastas com tamanho em KB (para somar fácil)
du -sk * | sort -n | while read -r size name; do
# Se passar de 1GB (1048576 KB), cria nova pasta
if (( total + size > 1048576 )); then
i=$((i+1))
total=0
destino=$(printf "%s-%02d" "$PREFIXO" "$i")
mkdir -p "$destino"
fi
echo "Movendo $name para $destino (tamanho: $size KB)"
mv "$name" "$destino/"
total=$((total + size))
doneveja que neste exemplo as variáveis abaixo precisam ser ajustas para o mês que você precisa trabalhar:
ORIGEM="/preservacao/dataverse/scielodata-setembro-2025"
PREFIXO="scielodata-setembro-2025"Antes de executar o script mova as pastas para a pasta do mês:
mv doi-10-48331-scielodata-* scielodata-setembro-2025/
./separador-pasta.sh
TROUBLESHOOTING
Version was already submitted for archiving.
Quando você envia para criar o pacote em uma data versão, não é possível criar o mesmo sem uma intervenção. O erro que dá é:
{"status":"ERROR","message":"Version was already submitted for archiving."}Para enviar novamente siga os passos:
sudo su - postgres
\c dvndb
SELECT
id, versionnumber, minorversionnumber, versionstate,
archivetime, archivalcopylocation, externalstatuslabel, archivenote
FROM datasetversion
WHERE dataset_id = '13150'
ORDER BY versionnumber DESC, minorversionnumber DESC;Veja que o resultado foi:

Vamos agora atualizar o registro para limpar esta mensagem:
UPDATE datasetversion
SET archivetime = NULL,
archivalcopylocation = NULL,
externalstatuslabel = NULL,
archivenote = NULL
WHERE id = 2209;Resultado:

Agora vamos executar novamente o comando:
sudo su - glassfish
export ID=13150
export API_TOKEN='minha api'
curl -X POST -H "X-Dataverse-key: $API_TOKEN" http://localhost:8080/api/admin/submitDatasetVersionToArchive/$ID/1.0Outra forma para limpar é:
export API_TOKEN=xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
export SERVER_URL=https://demo.dataverse.org
export PERSISTENT_IDENTIFIER=doi:10.5072/FK2/7U7YBV
export VERSION=1.0
curl -H "X-Dataverse-key: $API_TOKEN" -X DELETE "$SERVER_URL/api/datasets/:persistentId/$VERSION/archivalStatus?persistentId=$PERSISTENT_IDENTIFIER"Erro {"status":"failure","message":"Bag not transferred"}
Este erro aconteceu quando eu tentei criar os bagit e o usuário não tinha permissão para escrever no diretório /preservacao/dataverse. Uma vez que deu erro alguns pacotes ficaram com o status : {"status":"failure","message":"Bag not transferred"}
✅ 1️⃣ Primeiro: verifique antes de atualizar (modo seguro)
Antes de alterar qualquer coisa, rode este SELECT para confirmar exatamente quais registros serão afetados:
SELECT
id, dataset_id, versionnumber, versionstate, archivetime, archivalcopylocation
FROM datasetversion
WHERE archivalcopylocation::text LIKE '%"Bag not transferred"%';💡 Isso lista apenas as versões com erro de arquivamento, garantindo que você não vai limpar dados corretos.
✅ 2️⃣ Atualização segura (modo em lote)
Depois de confirmar, execute:
UPDATE datasetversion
SET
archivetime = NULL,
archivalcopylocation = NULL,
externalstatuslabel = NULL,
archivenote = NULL
WHERE archivalcopylocation::text LIKE '%"Bag not transferred"%';🔹 Esse comando:
-
limpa os campos de arquivamento que ficaram marcados com erro,
-
sem afetar versões bem-sucedidas ou DRAFTs normais.
Feito isso, faço novamente o processo de criação dos pacotes.