ARCHIVEMATICA
- INSTALANDO O ARCHIVEMATICA NO ROCKY LINUX 9
- MIGRANDO O ARCHIVEMATICA PARA UM NOVO SERVIDOR
- DIAGRAMA ARCHIVEMATICA
- FLUXO DE PRESERVAÇÃO DIGITAL DO SCIELO DATA USANDO O ARCHIVEMATICA E O ATOM
- FLUXO DE PRESERVAÇÃO DIGITAL USANDO O ARCHIVEMATICA E O ATOM
INSTALANDO O ARCHIVEMATICA NO ROCKY LINUX 9
Atualizando o sistema operacional:
sudo yum -y updateSe o seu ambiente usar SELinux, você precisará executar no mínimo os seguintes comandos. Configuração adicional pode ser necessária para sua configuração local.
# Allow Nginx to use ports 81 and 8001
sudo semanage port -m -t http_port_t -p tcp 81
sudo semanage port -a -t http_port_t -p tcp 8001
# Allow Nginx to connect the MySQL server and Gunicorn backends
sudo setsebool -P httpd_can_network_connect_db=1
sudo setsebool -P httpd_can_network_connect=1
# Allow Nginx to change system limits
sudo setsebool -P httpd_setrlimit 1Alguns repositórios extras precisam ser instalados para cumprir o procedimento de instalação.
sudo -u root yum install -y epel-release yum-utils
sudo -u root yum-config-manager --enable crbINSTALANDO OS REPOSITÓRIOS DO ELASTICSEARCH E O ARCHIVEMATICA
- Elasticsearch
sudo -u root rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
sudo -u root bash -c 'cat << EOF > /etc/yum.repos.d/elasticsearch.repo
[elasticsearch-6.x]
name=Elasticsearch repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF'- Archivematica
sudo -u root bash -c 'cat << EOF > /etc/yum.repos.d/archivematica.repo
[archivematica]
name=archivematica
baseurl=https://packages.archivematica.org/1.15.x/rocky9/
gpgcheck=1
gpgkey=https://packages.archivematica.org/GPG-KEY-archivematica-sha512
enabled=1
EOF'
sudo -u root bash -c 'cat << EOF > /etc/yum.repos.d/archivematica-extras.repo
[archivematica-extras]
name=archivematica-extras
baseurl=https://packages.archivematica.org/1.15.x/rocky9-extras
gpgcheck=1
gpgkey=https://packages.archivematica.org/GPG-KEY-archivematica-sha512
enabled=1
EOF'INSTALANDO O ELASTICSEARCH, MARIADB E GEARMAND
Serviços comuns como Elasticsearch, MariaDB e Gearmand devem ser instalados e habilitados antes da instalação do Archivematica.
sudo -u root yum install -y java-1.8.0-openjdk-headless mariadb-server gearmand
sudo -u root yum install -y elasticsearch
sudo -u root systemctl enable elasticsearch
sudo -u root systemctl start elasticsearch
sudo -u root systemctl enable mariadb
sudo -u root systemctl start mariadb
sudo -u root systemctl enable gearmand
sudo -u root systemctl start gearmandCRIANDO O BANCO DE DADOS DO ARCHIVEMATICA E DO STORAGE SERVICE
Agora que o MariaDB está instalado e funcionando, crie os bancos de dados Archivematica e Storage Service e configure as credenciais esperadas.
sudo -H -u root mysql -hlocalhost -uroot -e "DROP DATABASE IF EXISTS MCP; CREATE DATABASE MCP CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;"
sudo -H -u root mysql -hlocalhost -uroot -e "DROP DATABASE IF EXISTS storage_service; CREATE DATABASE SS CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;"
sudo -H -u root mysql -hlocalhost -uroot -e "CREATE USER 'archivematica'@'localhost' IDENTIFIED BY 'demo';"
sudo -H -u root mysql -hlocalhost -uroot -e "GRANT ALL ON MCP.* TO 'archivematica'@'localhost';"
sudo -H -u root mysql -hlocalhost -uroot -e "GRANT ALL ON storage_service.* TO 'archivematica'@'localhost';"Instale o serviço de armazenamento Archivematica Storage Service
sudo -u root yum install -y python-pip archivematica-storage-serviceAplique as migrações de banco de dados usando o usuário archivematica:
sudo -u archivematica bash -c " \
set -a -e -x
source /etc/sysconfig/archivematica-storage-service
cd /usr/lib/archivematica/storage-service
/usr/share/archivematica/virtualenvs/archivematica-storage-service/bin/python manage.py migrate
";Agora habilite e inicie o archivematica-storage-service, rngd (necessário para espaços criptografados) e o frontend Nginx:
sudo -u root systemctl enable archivematica-storage-service
sudo -u root systemctl start archivematica-storage-service
sudo -u root systemctl enable nginx
sudo -u root systemctl start nginx
sudo -u root systemctl enable rngd
sudo -u root systemctl start rngdO Serviço de Armazenamento estará disponível em http://<ip>:8001.
INSTALANDO O ARCHIVEMATICA DASHBOARD E O MCP SERVER
sudo -u root yum install -y archivematica-common archivematica-mcp-server archivematica-dashboardAplique as migrações de banco de dados usando o usuário archivematica:
sudo -u archivematica bash -c " \
set -a -e -x
source /etc/sysconfig/archivematica-dashboard
cd /usr/share/archivematica/dashboard
/usr/share/archivematica/virtualenvs/archivematica/bin/python manage.py migrate
";Inicie e habilite serviços:
sudo -u root systemctl enable archivematica-mcp-server
sudo -u root systemctl start archivematica-mcp-server
sudo -u root systemctl enable archivematica-dashboard
sudo -u root systemctl start archivematica-dashboardReinicie o Nginx para carregar o arquivo de configuração do painel:
sudo -u root systemctl restart nginxO painel estará disponível em http://<ip>:81
INSTALANDO O MCP CLIENT
sudo -u root yum install -y archivematica-mcp-clientTweak ClamAV configuration:
sudo -u root sed -i 's/^#TCPSocket/TCPSocket/g' /etc/clamd.d/scan.conf
sudo -u root sed -i 's/^Example//g' /etc/clamd.d/scan.confDepois disso, podemos ativar e iniciar/reiniciar serviços
sudo -u root systemctl enable archivematica-mcp-client
sudo -u root systemctl start archivematica-mcp-client
sudo -u root systemctl enable fits-nailgun
sudo -u root systemctl start fits-nailgun
sudo -u root systemctl enable clamd@scan
sudo -u root systemctl start clamd@scan
sudo -u root systemctl restart archivematica-dashboard
sudo -u root systemctl restart archivematica-mcp-serverFinalizando a instalação
Configuração
Cada serviço possui um arquivo de configuração em /etc/sysconfig/archivematica-packagename
Solução de problemas
Se o IPv6 estiver desabilitado, o Nginx pode se recusar a iniciar. Se for esse o caso, certifique-se de que as diretivas listen usadas em /etc/nginx não estejam usando endereços IPv6 como [::]:80.
Rocky Linux instalará o firewalld que executará regras padrão que provavelmente bloquearão as portas 81 e 8001. Se você não conseguir acessar o painel e o serviço de armazenamento, use o seguinte comando para verificar se o firewalld está em execução:
sudo systemctl status firewalldSe o firewalld estiver em execução, você provavelmente precisará modificar as regras do firewall para permitir o acesso às portas 81 e 8001 do seu local:
sudo firewall-cmd --add-port=81/tcp --permanent
sudo firewall-cmd --add-port=8001/tcp --permanentCONFIGURAÇÃO PÓS-INSTALAÇÃO
Após concluir com êxito uma nova instalação, siga estas etapas para concluir a configuração do seu novo servidor.
O Serviço de Armazenamento é executado como um aplicativo web separado do painel do Archivematica. O Serviço de Armazenamento é exposto na porta 8001 por padrão ao implantar usando pacotes RPM. Use seu navegador da web para navegar até o serviço de armazenamento no endereço IP da máquina em que você está instalando, por exemplo, http://<MY-IP-ADDR>:8001 (ou http://localhost:8001 ou http: //127.0.0.1:8001 se esta for uma configuração de desenvolvimento local).
Se estiver usando um endereço IP ou nome de domínio totalmente qualificado em vez de localhost, você precisará configurar suas regras de firewall e permitir acesso apenas às portas 81 e 8001 para uso do Archivematica.
O Serviço de Armazenamento possui seu próprio conjunto de usuários. Crie um novo usuário com privilégios totais de administrador:
sudo -u archivematica bash -c " \
set -a -e -x
source /etc/default/archivematica-storage-service || \
source /etc/sysconfig/archivematica-storage-service \
|| (echo 'Environment file not found'; exit 1)
cd /usr/lib/archivematica/storage-service
/usr/share/archivematica/virtualenvs/archivematica-storage-service/bin/python manage.py createsuperuser
";Depois de criar esse usuário, a chave de API será gerada automaticamente e essa chave conectará o pipeline do Archivematica à API do Storage Service. A chave API pode ser encontrada através da interface web (vá em Administração > Usuários).
Para finalizar a instalação, use seu navegador da web para navegar até o painel do Archivematica usando o endereço IP da máquina na qual você está instalando, por exemplo, http://<MY-IP-ADDR>:81 (ou http:// localhost:81 ou http://127.0.0.1:81 se esta for uma configuração de desenvolvimento local).
Na página de boas-vindas, crie um usuário administrativo para o pipeline do Archivematica inserindo o nome da organização, o identificador da organização, nome de usuário, email e senha.
Na próxima tela, conecte seu pipeline ao serviço de armazenamento inserindo a URL e o nome de usuário do serviço de armazenamento e colando a chave de API que você copiou na etapa (2).
Se o serviço de armazenamento e o painel do Archivematica estiverem instalados na mesma máquina, você deverá fornecer http://127.0.0.1:8001 como URL do serviço de armazenamento nesta tela.
Se o Serviço de Armazenamento e o painel do Archivematica estiverem instalados em nós (servidores) diferentes, você deverá usar o endereço IP ou nome de domínio totalmente qualificado da sua instância do Serviço de Armazenamento, por exemplo, http://<MY-IP-ADDR>: 8001 e você deve garantir que todas as regras de firewall (ou seja, iptables, ufw, grupos de segurança da AWS etc.) estejam configuradas para permitir solicitações do IP do seu painel para o IP do serviço de armazenamento na porta apropriada.
REFERÊNCIA
MIGRANDO O ARCHIVEMATICA PARA UM NOVO SERVIDOR
A migração do archivematica foi de um servidor CentOS 7.9 para Rocky Linux 9.4
A versão do archivematica era o 1.14.1 e foi migrado para 1.16.0
Atualizando o sistema operacional:
sudo yum -y updateSe o seu ambiente usar SELinux, você precisará executar no mínimo os seguintes comandos. Configuração adicional pode ser necessária para sua configuração local.
# Allow Nginx to use ports 81 and 8001
sudo semanage port -m -t http_port_t -p tcp 81
sudo semanage port -a -t http_port_t -p tcp 8001
# Allow Nginx to connect the MySQL server and Gunicorn backends
sudo setsebool -P httpd_can_network_connect_db=1
sudo setsebool -P httpd_can_network_connect=1
# Allow Nginx to change system limits
sudo setsebool -P httpd_setrlimit 1Alguns repositórios extras precisam ser instalados para cumprir o procedimento de instalação.
sudo -u root yum install -y epel-release yum-utils
sudo -u root yum-config-manager --enable crbINSTALANDO OS REPOSITÓRIOS DO ELASTICSEARCH E O ARCHIVEMATICA
- Elasticsearch
sudo -u root rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
sudo -u root bash -c 'cat << EOF > /etc/yum.repos.d/elasticsearch.repo
[elasticsearch-6.x]
name=Elasticsearch repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF'- Archivematica
sudo -u root bash -c 'cat << EOF > /etc/yum.repos.d/archivematica.repo
[archivematica]
name=archivematica
baseurl=https://packages.archivematica.org/1.15.x/rocky9/
gpgcheck=1
gpgkey=https://packages.archivematica.org/GPG-KEY-archivematica-sha512
enabled=1
EOF'
sudo -u root bash -c 'cat << EOF > /etc/yum.repos.d/archivematica-extras.repo
[archivematica-extras]
name=archivematica-extras
baseurl=https://packages.archivematica.org/1.15.x/rocky9-extras
gpgcheck=1
gpgkey=https://packages.archivematica.org/GPG-KEY-archivematica-sha512
enabled=1
EOF'INSTALANDO O ELASTICSEARCH, MARIADB E GEARMAND
Serviços comuns como Elasticsearch, MariaDB e Gearmand devem ser instalados e habilitados antes da instalação do Archivematica.
sudo -u root yum install -y java-1.8.0-openjdk-headless mariadb-server gearmand
sudo -u root yum install -y elasticsearch
sudo -u root systemctl enable elasticsearch
sudo -u root systemctl start elasticsearch
sudo -u root systemctl enable mariadb
sudo -u root systemctl start mariadb
sudo -u root systemctl enable gearmand
sudo -u root systemctl start gearmandMIGRANDO OS BANCOS NO MARIADB
CRIANDO O DUMP DOS BANCOS
No servidor de origem:
mysqldump -u root -p MCP > ~/am_backup.sql
mysqldump -u root -p storage_service > ~/storage_service.sqlAgora devemos copiá-los para o servidor de destino.
CRIANDO O BANCO DE DADOS DO ARCHIVEMATICA E DO STORAGE SERVICE
Agora que o MariaDB está instalado e funcionando, crie os bancos de dados Archivematica e Storage Service e configure as credenciais esperadas.
sudo -H -u root mysql -hlocalhost -uroot -e "DROP DATABASE IF EXISTS MCP; CREATE DATABASE MCP CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;"
sudo -H -u root mysql -hlocalhost -uroot -e "DROP DATABASE IF EXISTS storage_service; CREATE DATABASE SS CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;"
sudo -H -u root mysql -hlocalhost -uroot -e "CREATE USER 'archivematica'@'localhost' IDENTIFIED BY '<omitida>';"
sudo -H -u root mysql -hlocalhost -uroot -e "GRANT ALL ON MCP.* TO 'archivematica'@'localhost';"
sudo -H -u root mysql -hlocalhost -uroot -e "GRANT ALL ON storage_service.* TO 'archivematica'@'localhost';"FAZENDO O RESTORE DO BANCO
Uma vez copiados os dumps, devemos restaurá-lo nos bancos recém criados.
mysql -u root -p MCP < ~/am_backup.sql
mysql -u root -p storage_service < ~/storage_service.sqlMIGRANDO O INDICE NO ELASTICSEARCH
CONFIGURANDO O CAMINHO DO REPOSITÓRIO
O repositório dos snapshots no SciELO é um ponto de montagem NFS. Este ponto NFS deve ser montado no novo servidor. Mas antes instale o pacote nfs-utils:
sudo yum install nfs-utils -yCrie o diretório do repositório:
sudo mkdir /var/lib/elasticsearch/backup-repoConfigure o /etc/fstab para persistir:
storage-scielo-251.scielo.org:/archivematica_es_bkp /var/lib/elasticsearch/backup-repo nfs vers=4,rsize=8192,wsize=8192,timeo=14,intr 0 0Agora basta montar:
sudo systemctl daemon-reload
sudo mount -aADICIONADO O ELASTICSEARCH NA CONFIGURAÇÃO
Edite o arquivo /etc/elasticsearch/elasticsearch.yml e adicione a linha abaixo de path.logs:
path.repo: /var/lib/elasticsearch/backup-repoReinicie o elasticsearch
sudo systemctl restart elasticsearchDevemos garantir que o usuário elasticsearch seja o dono do diretório /var/lib/elasticsearch/backup-repo:
sudo chown elasticsearch. -R /var/lib/elasticsearch/backup-repoCRIANDO O REPOSITÓRIO
curl -XPUT -H 'Content-Type: application/json' 'http://localhost:9200/_snapshot/es_backup_archivematica' -d '{
"type": "fs",
"settings": {
"compress" : true,
"location": "/var/lib/elasticsearch/backup-repo/es_backup_archivematica"
}
}'Consulte o repositório:
curl -X GET "localhost:9200/_cat/snapshots/es_backup_archivematica?v&s=id&pretty"
RESTAURANDO O ÚLTIMO SNAPSHOT
curl -X POST "localhost:9200/_snapshot/es_backup_archivematica/20240917-235942/_restore?pretty"LISTANDO OS INDICES RESTAURADOS
curl -X GET "http://localhost:9200/_cat/indices?v"
MIGRANDO O ARCHIVEMATICA STORAGE SERVICE
Instale o serviço de armazenamento Archivematica Storage Service
sudo -u root yum install -y python-pip archivematica-storage-serviceCopie o arquivo /etc/sysconfig/archivematica-storage-service do servidor de origem
Instale o Archivematica Dashboard e o MCP Service e Client:
sudo -u root yum install -y archivematica-common archivematica-mcp-server archivematica-dashboard archivematica-mcp-clientCopie o arquivo /etc/sysconfig/archivematica-dashboard, /etc/sysconfig/archivematica-storage-service e o /etc/sysconfig/archivematica-mcp-client do servidor de origem.
APLICANDO A MIGRAÇÃO DO BANCO DO ARCHIVEMATICA
sudo -u archivematica bash -c " \
set -a -e -x
source /etc/default/archivematica-dashboard || \
source /etc/sysconfig/archivematica-dashboard \
|| (echo 'Environment file not found'; exit 1)
cd /usr/share/archivematica/dashboard
/usr/share/archivematica/virtualenvs/archivematica/bin/python manage.py migrate --noinput
";APLICANDO A MIGRAÇÃO DO BANCO DO ARCHIVEMATICA STORAGE SERVICE
sudo -u archivematica bash -c " \
set -a -e -x
source /etc/default/archivematica-storage-service || \
source /etc/sysconfig/archivematica-storage-service \
|| (echo 'Environment file not found'; exit 1)
cd /usr/lib/archivematica/storage-service
/usr/share/archivematica/virtualenvs/archivematica-storage-service/bin/python manage.py migrate
";Reiniciando os serviços:
sudo systemctl restart archivematica-storage-service
sudo systemctl restart archivematica-dashboard
sudo systemctl restart archivematica-mcp-client
sudo systemctl restart archivematica-mcp-server
sudo -u root systemctl enable nginx
sudo -u root systemctl start nginx
sudo -u root systemctl enable rngd
sudo -u root systemctl start rngdCONFIGURANDO O ANTI-VIRUS
sudo -u root sed -i 's/^#TCPSocket/TCPSocket/g' /etc/clamd.d/scan.conf
sudo -u root sed -i 's/^Example//g' /etc/clamd.d/scan.confDepois disso, podemos ativar e iniciar/reiniciar serviços
sudo -u root systemctl enable archivematica-mcp-client
sudo -u root systemctl start archivematica-mcp-client
sudo -u root systemctl enable fits-nailgun
sudo -u root systemctl start fits-nailgun
sudo -u root systemctl enable clamd@scan
sudo -u root systemctl start clamd@scan
sudo -u root systemctl restart archivematica-dashboard
sudo -u root systemctl restart archivematica-mcp-serverCONFIGURANDO O NGINX
O archivematica-dashboard e o archivematica-storage-service terão um vhost configurado:
/etc/nginx/conf.d/archivematica-dashboard.conf
server {
listen 80 default_server;
client_max_body_size 256M;
server_name _;
location / {
proxy_set_header Host $http_host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_redirect off;
proxy_buffering off;
proxy_read_timeout 172800s;
proxy_pass http://localhost4:7400;
}
}/etc/nginx/conf.d/archivematica-storage-service.conf
server {
listen 8001 default_server;
client_max_body_size 256M;
server_name _;
location / {
proxy_set_header Host $http_host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_redirect off;
proxy_buffering off;
proxy_read_timeout 172800s;
proxy_pass http://localhost4:7500;
proxy_http_version 1.1;
}
}Agora iremos configurar o proxy reverso no ha-1 para ativar o https:
/etc/nginx/conf.d/archivematica-scielo-org.conf
upstream archivematica {
server 192.168.2.126:80;
}
server {
listen 443 http2;
server_name archivematica.scielo.org;
ssl_certificate /certificados2/scielo.org/fullchain.pem;
ssl_certificate_key /certificados2/scielo.org/privkey.pem;
ssl on;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_prefer_server_ciphers on;
ssl_ciphers 'ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:AES:CAMELLIA:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!MD5:!PSK:!aECDH:!EDH-DSS-DES-CBC3-SHA:!EDH-RSA-DES-CBC3-SHA:!KRB5-DES-CBC3-SHA';
ssl_session_timeout 1d;
ssl_session_cache shared:SSL:50m;
ssl_stapling on;
ssl_stapling_verify on;
add_header Strict-Transport-Security max-age=15768000;
keepalive_timeout 150s;
client_max_body_size 100M;
location / {
proxy_set_header Host $host;
proxy_set_header X-Scheme $scheme;
proxy_set_header X-SSL-Protocal $ssl_protocol;
proxy_redirect http:// $scheme://;
proxy_set_header X-Forwarded-Proto https;
proxy_set_header X-Forwarded-Port $server_port;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://archivematica;
proxy_http_version 1.1;
proxy_read_timeout 900s;
proxy_redirect off;
allow all;
}
gzip on;
access_log /var/log/nginx/archivematica-scielo-org/archivematica-scielo-org.log;
error_log /var/log/nginx/archivematica-scielo-org/archivematica-scielo-org-error.log warn;
}
server {
listen 80;
server_name archivematica.scielo.org;
return 301 https://$server_name$request_uri;
}
MIGRANDO OS DADOS
Os dados que estão em /var/archivematica/ devem ser migrados e as permissões ajustadas para o usuário archivematica.
[root@node01-archivematica ~]# ls -lha /var/archivematica/
total 16K
drwxr-xr-x. 5 archivematica archivematica 75 Sep 18 17:03 .
drwxr-xr-x. 21 root root 4.0K Sep 18 16:58 ..
drwxr-xr-x. 15 archivematica archivematica 4.0K Jul 19 2023 sharedDirectory
drwxrwx---. 2 archivematica archivematica 24 Sep 17 09:47 storage-service
drwxr-xr-x. 172 archivematica archivematica 4.0K Sep 19 16:14 storage_serviceREFERÊNCIA
https://www.archivematica.org/en/docs/archivematica-1.12/admin-manual/maintenance/maintenance/
DIAGRAMA ARCHIVEMATICA

FLUXO DE PRESERVAÇÃO DIGITAL DO SCIELO DATA USANDO O ARCHIVEMATICA E O ATOM
Esta documentação apresenta o fluxo de preservação digital do site SciELO Data. Onde os objetos digitais desse repositório fazem parte dos dados de pesquisa e metadados submetidos pelos autores.
Portanto, o objetivo desse manual é apresentar o fluxo de preservação digital do repositório de dados do SciELO (https://data.scielo.org) utilizando o Archivematica e o AtoM.
Os conjuntos de dados do repositórios são armazenados individualmente em pacotes de preservação chamado de BagITs. Eles são gerados mensalmente e armazenados em pastas com a seguinte identificação: scielodata-mês-ano. Exemplo: scielodata-agosto-2025.
E dentro dessa pasta haverá outras pastas que são pastas que divide o tamanho da soma dos bagits gerados. O tamanho considerado para cada uma dessa divisão é de 1GB, podendo ter pacotes individuais que podem ter mais de 1GB. Portanto, esse pode ser superior a regra proposta.
O fluxo de criação dos bagits e das pastas que os organizam está em https://documentacao.scielo.org/books/preservacao-digital/page/gerenciar-pacotes-bagit
Manual de uso
Acesse o site https://archivematica.scielo.org
Guia Transferência
A guia Transferência é o local onde muitos usuários iniciam o processo de transformar seus objetos digitais em Pacotes de Informações de Arquivamento (AIPs). Na guia Transferência, os usuários selecionam o material a ser preservado, nomeiam a transferência e iniciam o processo de transferência.
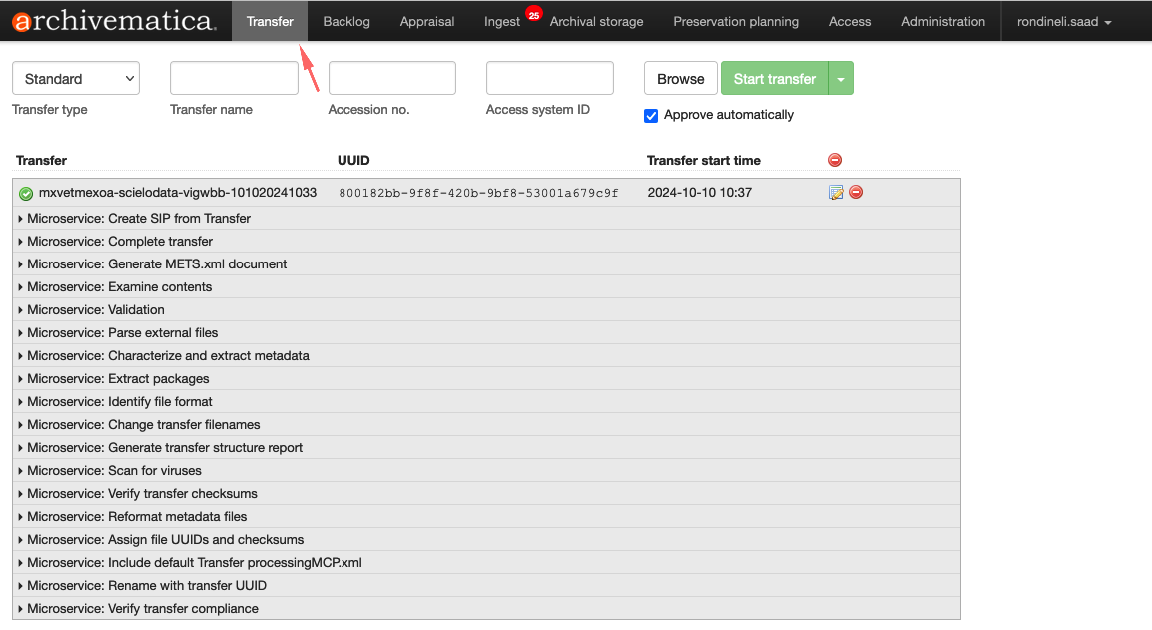
A seção na parte superior da guia Transferência é onde você encontrará materiais para transferência para o Archivematica. Existem quatro campos a serem preenchidos, os botões Browse e Start transfer e a caixa de seleção Approve automatically
- Tipo de transferência : o tipo de material que está sendo transferido. Consulte Tipos de transferência para obter mais informações.
- Nome da transferência : um nome para sua transferência. Este se tornará o nome do pacote de informações de arquivamento (AIP) resultante. Este é um campo obrigatório.
- Adesão no. : A inserção de um número de acesso para sua transferência resultará na cópia do número de acesso no arquivo AIP METS como um evento de registro. Não é usado para identificar ou procurar o AIP no Archivematica. Este campo é opcional.
- ID do sistema de acesso : inserir um campo de ID do sistema de acesso ao configurar sua transferência permite automatizar o processo de upload de um DIP para o AtoM. O Archivematica automaticamente captura esse valor quando alcançar o microsserviço DIP de upload. Consulte Carregar um DIP para AtoM para obter mais informações. Este campo é opcional.
- Procurar : O botão Procurar alterna para abrir o navegador de transferência. Isso permite que os usuários visualizem e naveguem pelos locais configurados da fonte de transferência. Para obter mais informações sobre como configurar locais de origem de transferência que o Archivematica pode acessar, consulte o Manual do administrador - Serviço de armazenamento . Selecionar um diretório e clicar em Adicionar adiciona o diretório de materiais à transferência.
- Iniciar transferência : depois de atribuir à sua transferência um nome e o material selecionado no navegador de transferências, o botão Iniciar transferência inicia os microsserviços de transferência.
- Aprovar automaticamente : se esta caixa estiver desmarcada, o Archivematica fará uma pausa no primeiro micros serviço, Aprovar transferência , e você terá a chance de confirmar que sua transferência foi configurada corretamente. Se a caixa estiver marcada, o Archivematica não fará uma pausa nesta etapa.
Quando a transferência é por dataset
O padrão de nome adotado para transferências dos conjuntos de dados do Data SciELO ficou:
<acrônimo do periódico no dataverse>-<identificador DOI>-<dia-mes-ano-hora-minuto>
Exemplo: mxvetmexoa-scielodata-qbt2oa-161020241746
Este exemplo corresponde ao conjunto de dados com a https://data.scielo.org/dataset.xhtml?persistentId=doi:10.48331/scielodata.QBT2OA
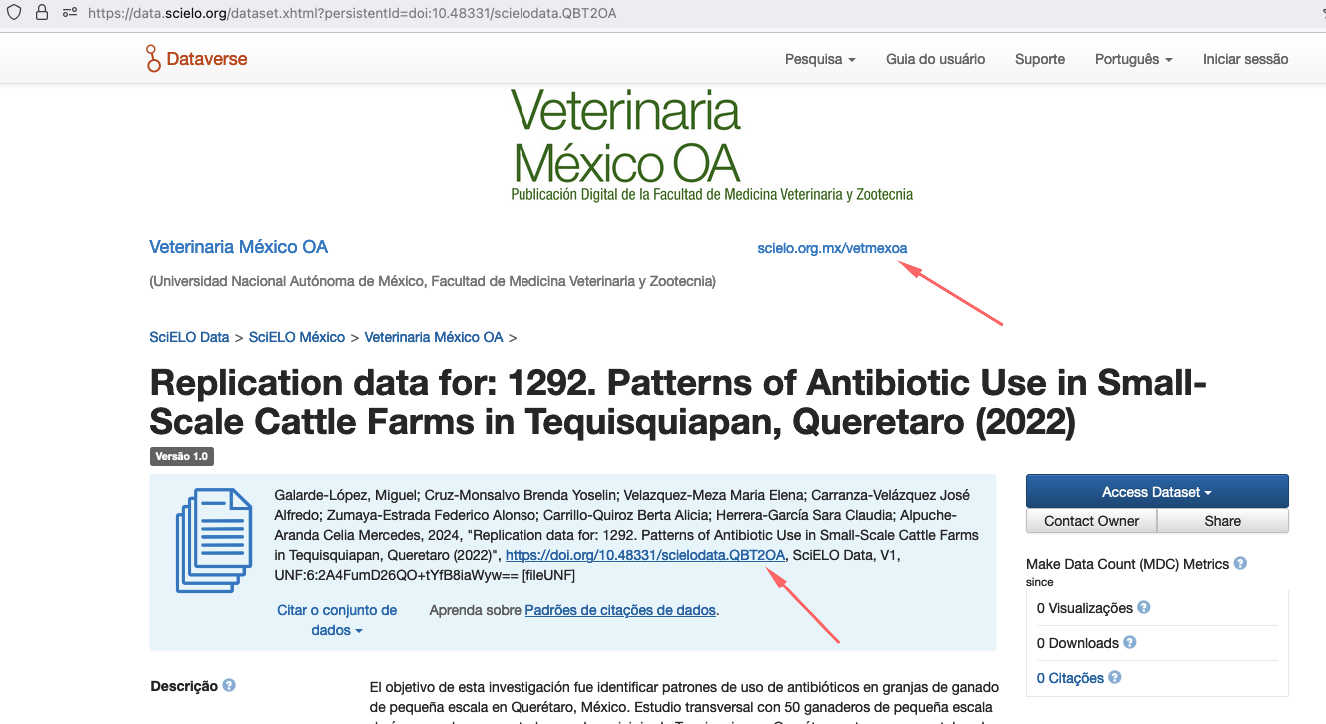
Para iniciar o processo de transferência, clique no botão Browse para listar as coleções. Selecione a coleção, conforme a imagem abaixo:
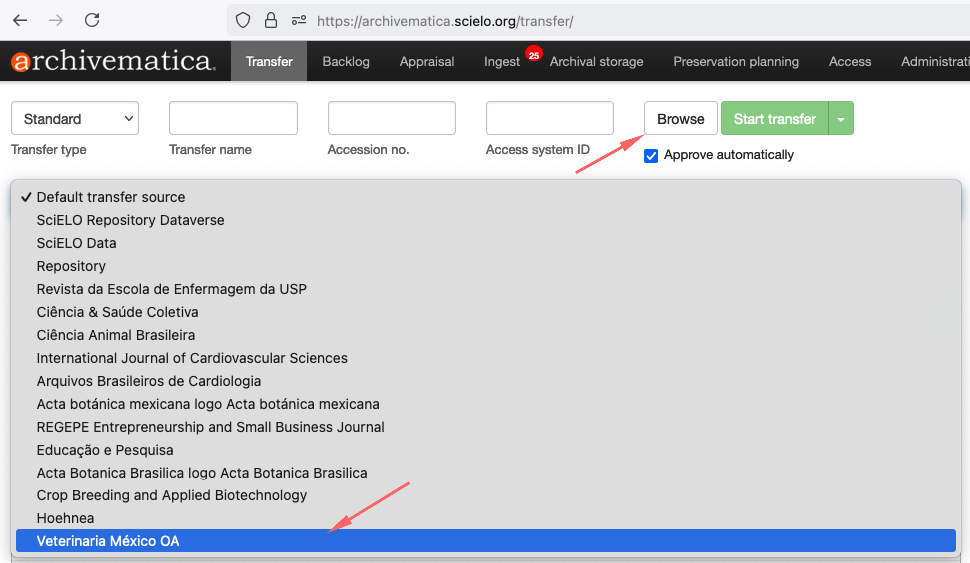
Ao selecionar a coleção, os datasets aparecerão.
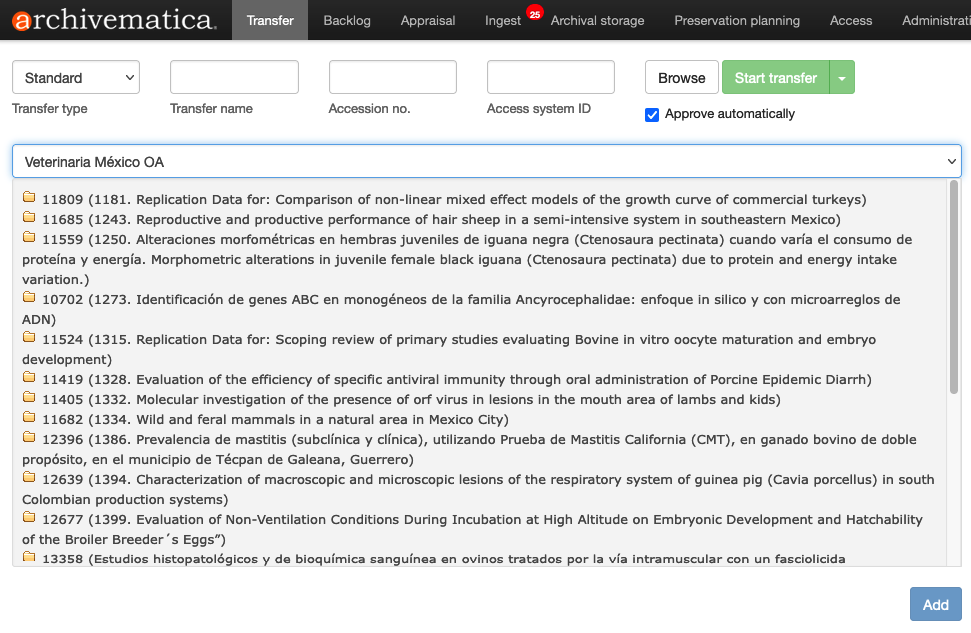
Selecione o dataset e clique no botão Add
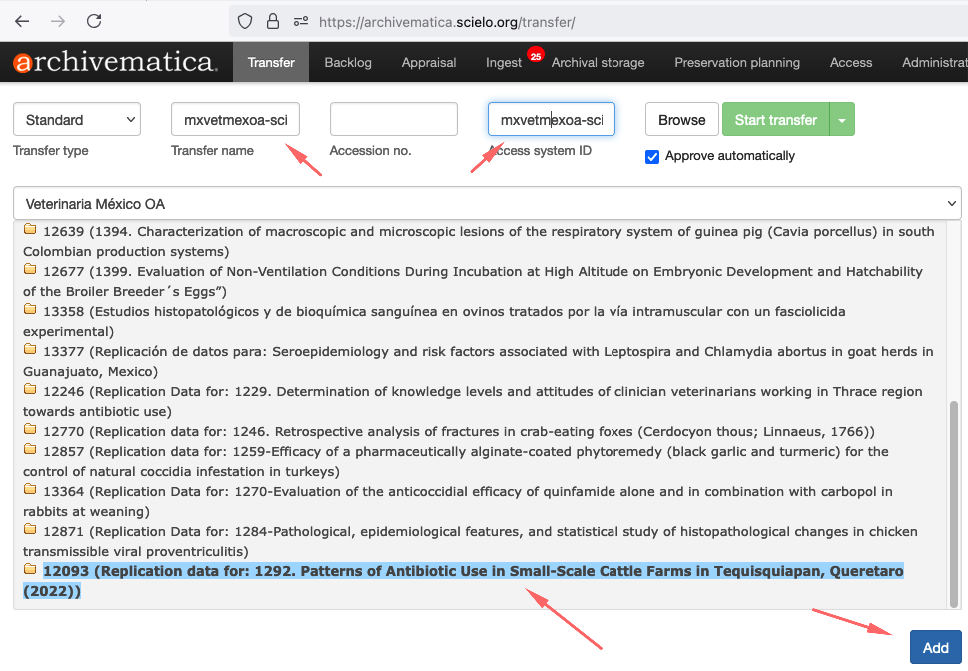
Importante que antes de pressionar o botão Start Transfer, execute o procedimento abaixo:
PREPARANDO O ATOM PARA RECEBER O DIP
Acesse https://atom.scielo.org/
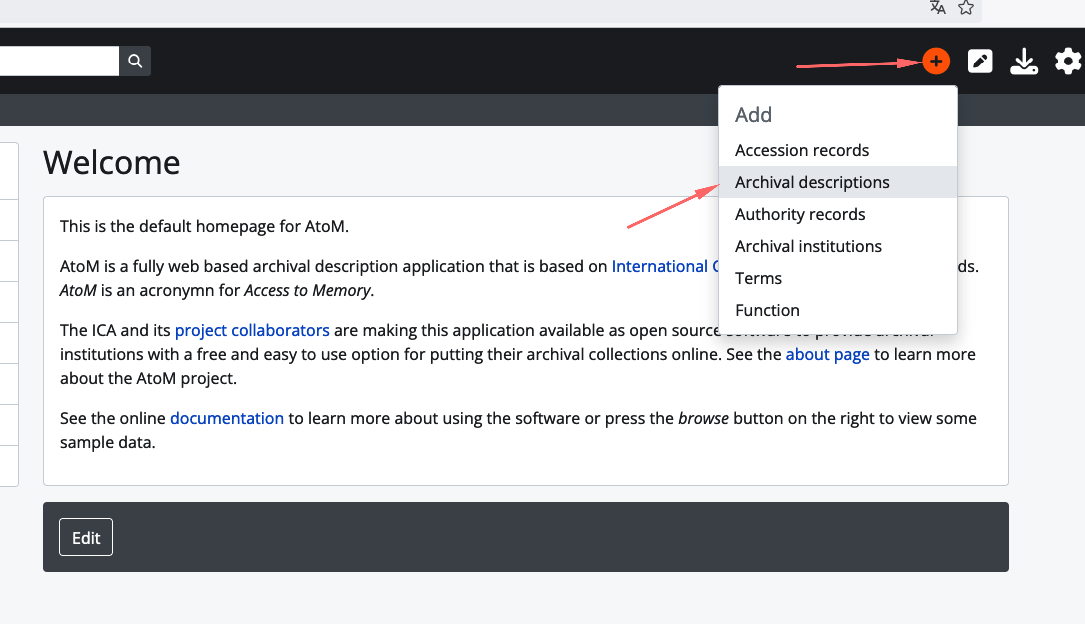
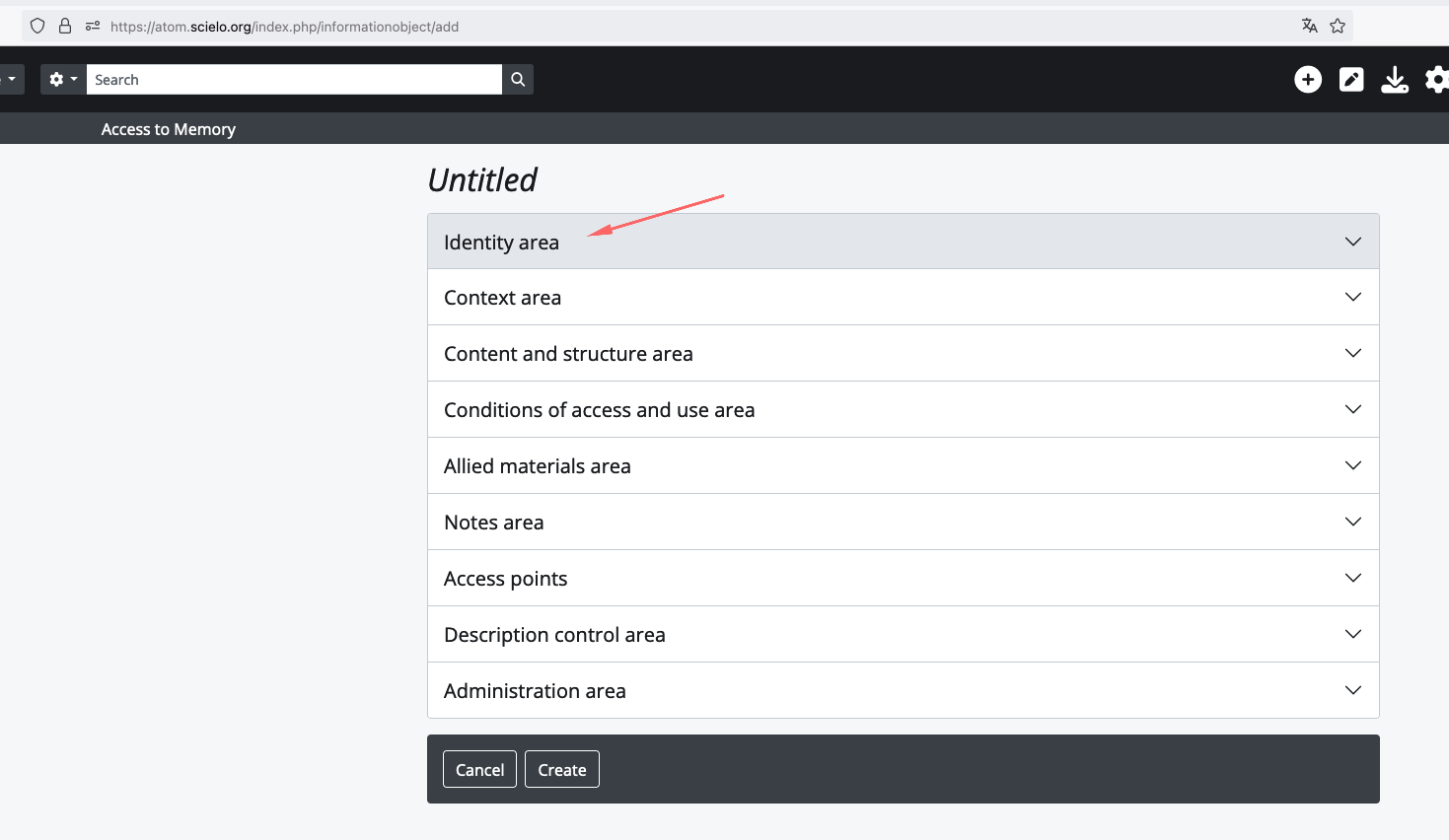
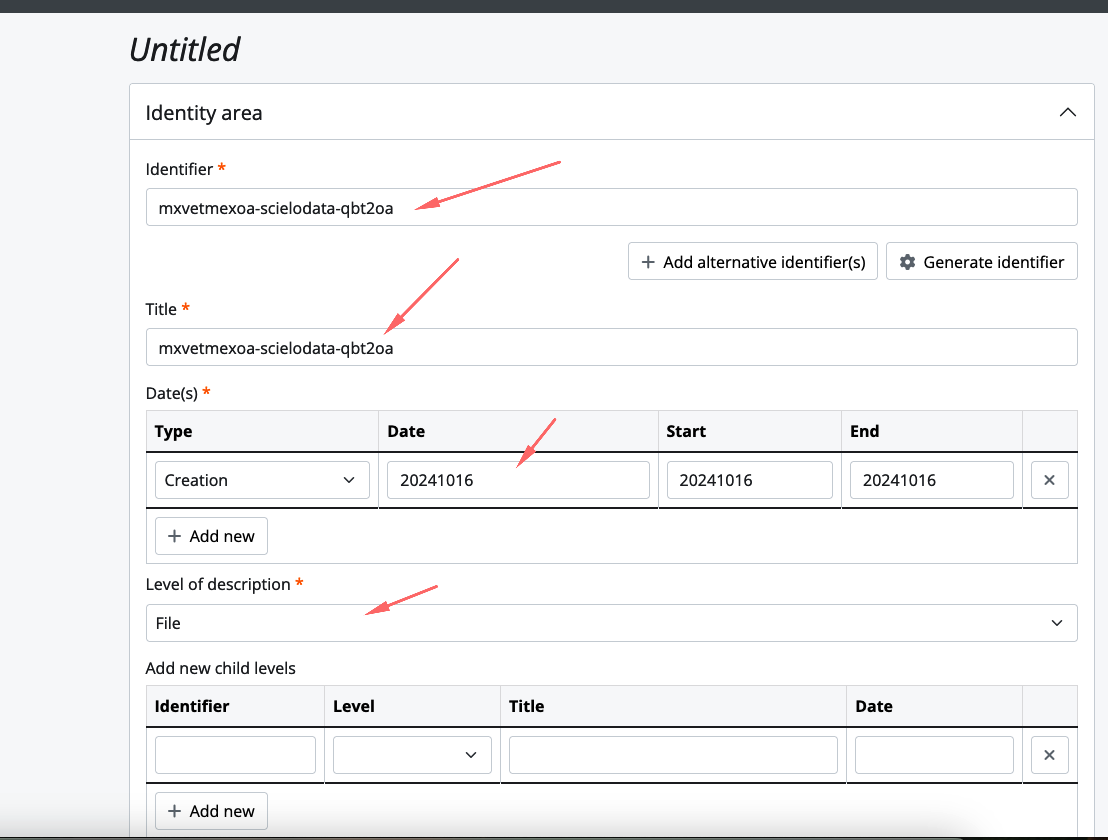
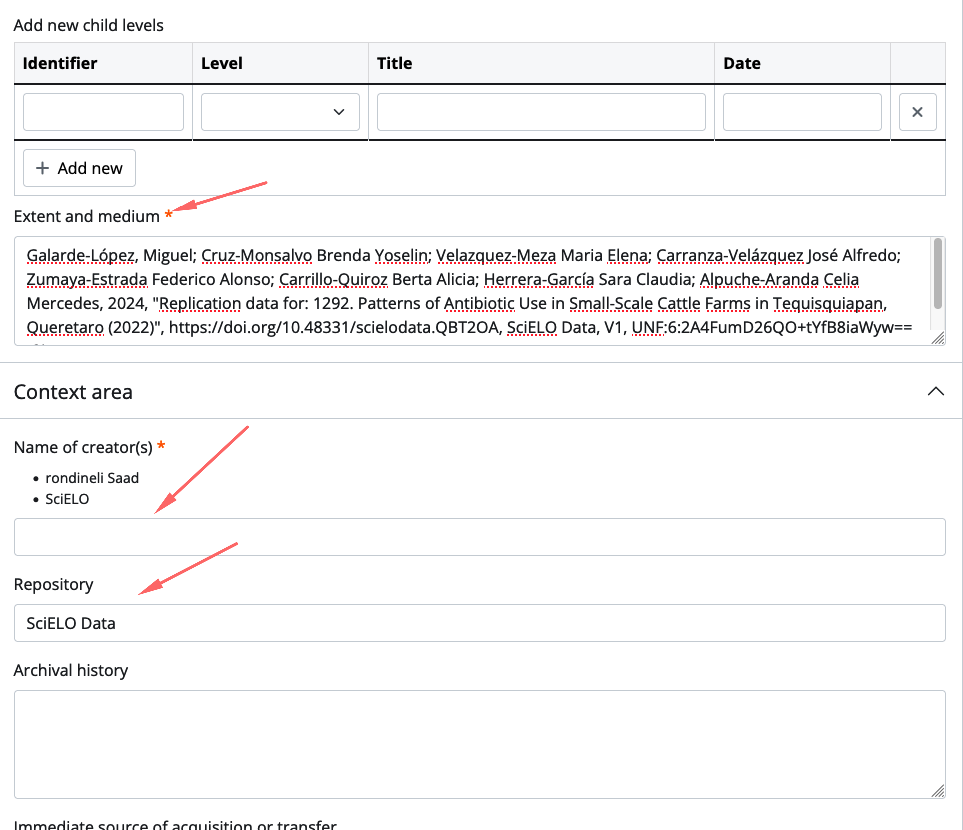
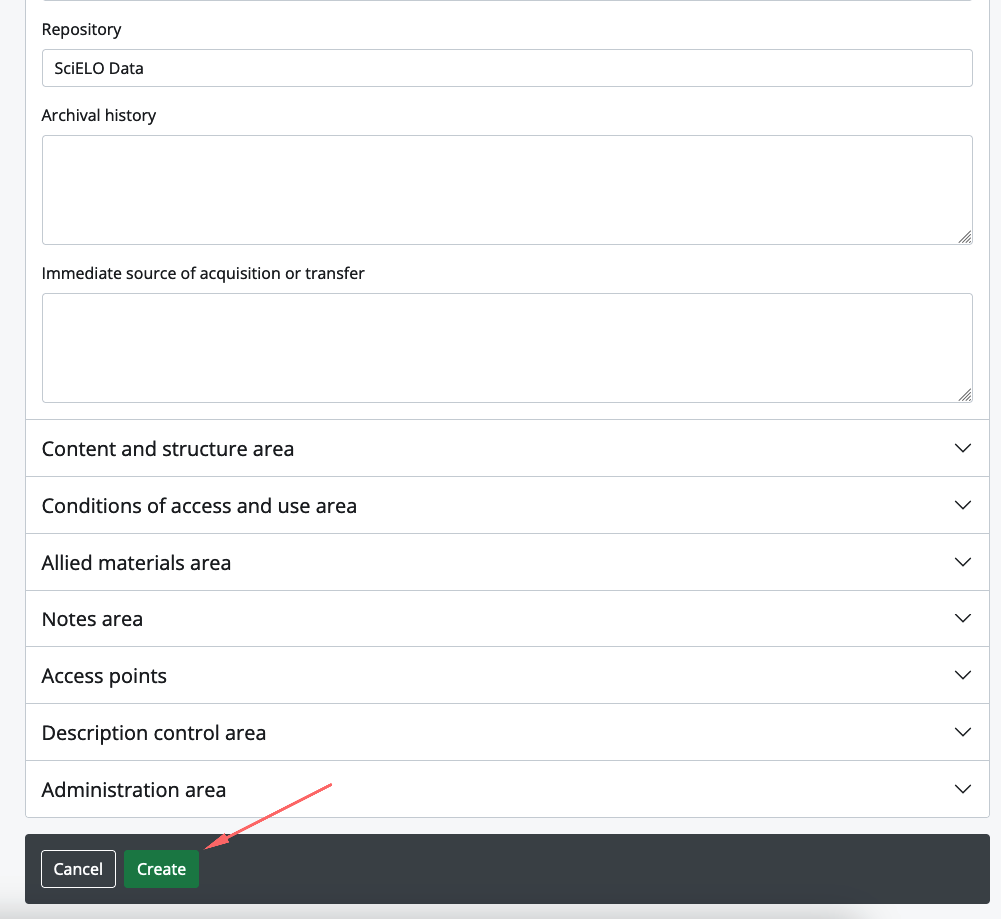
A url criada foi https://atom.scielo.org/index.php/mxvetmexoa-scielodata-qbt2oa
Ao finalizar o procedimento de preparação do AtoM, clique no botão Start transfer para iniciar o processo.
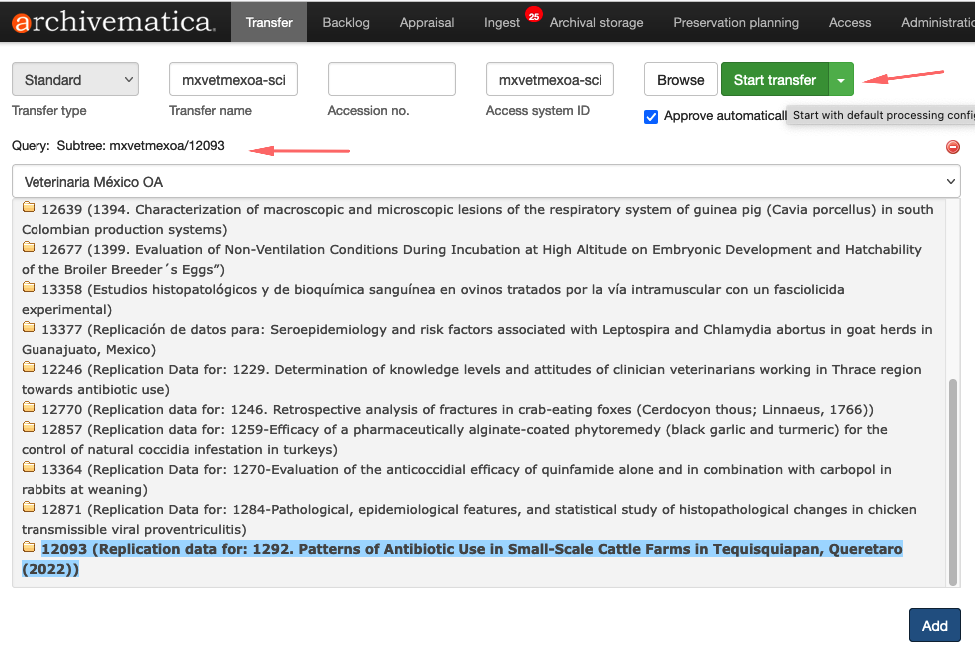
Se não houver erro, o processo de ingestão iniciará.
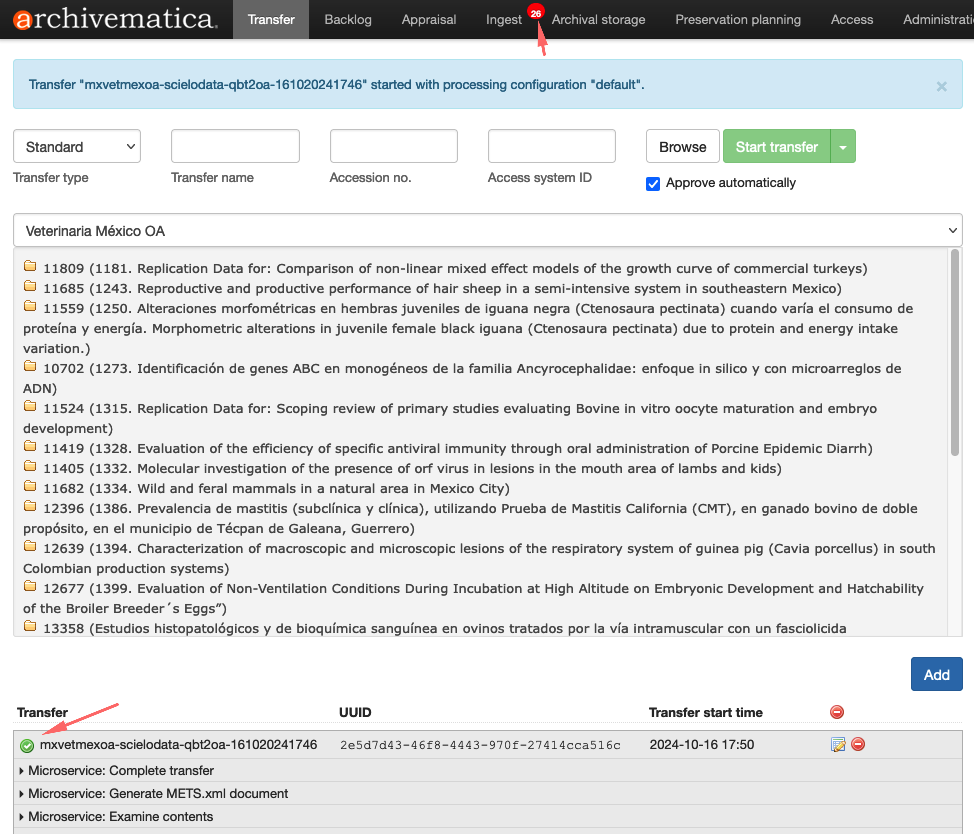
Depois que uma transferência é iniciada, ela aparece abaixo da área de preparação da transferência. Vários microsserviços executam o material transferido para prepará-lo para se tornar um SIP. A lista de microsserviços deve ser lida de baixo para cima.
No final do processo de transferência, o material transferido pode ser enviado para o backlog , onde pode ser armazenado até que você esteja pronto para transformá-lo em um AIP. O backlog também oferece aos usuários a chance de realizar tarefas de avaliação . Como alternativa, o usuário pode transformar o material transferido em um SIP e enviá-lo para a guia Ingest .
Você pode limpar a guia Transferência removendo transferências concluídas ou rejeitadas. Para obter mais informações, consulte Limpando a guia Transferir abaixo.
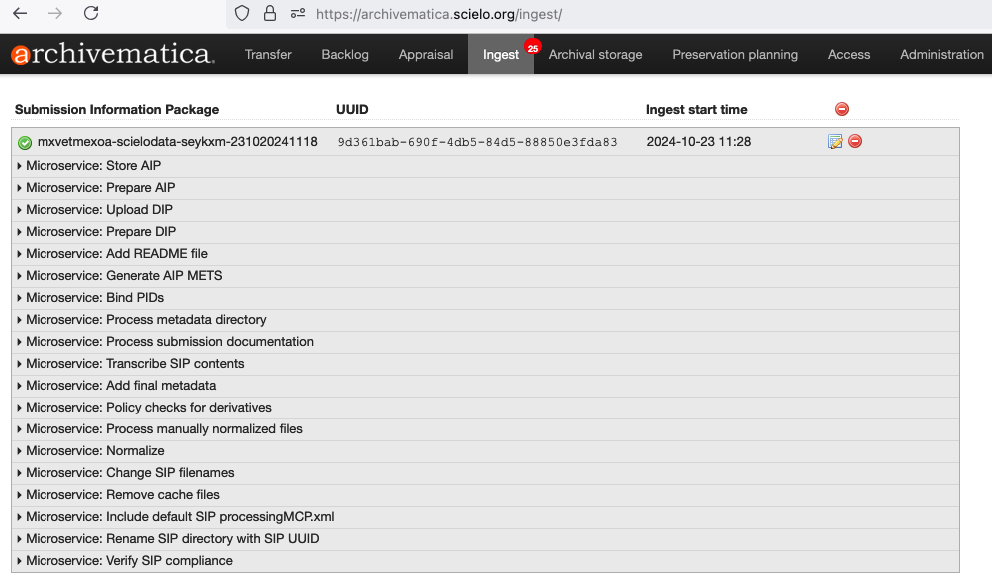
ALIMENTANDO A PLANILHA DE CONTROLE
Uma vez que o fluxo de ingest finalize, é necessário adicionar na planilha [ARCHIVEMATICA] PRESERVAÇÃO DIGITAL DATAVERSE o pacote que foi preservado. Cada aba da planilha corresponde a gestão dos conjuntos de dados que foram preservador.
Os campos a serem preenchidos são:
- DATA DE SUBMISSÃO: Corresponde quando o fluxo foi executado.
- ACRONIMO: Corresponde ao acrônimo da revista no Data SciELO
- DATASET (DOI): O identificador único do conjunto de dados
- TRANSFER NAME: Nome de indentificação de transferência
-
ACCESS SYSTEM ID: ID de acesso ao sistema.
-
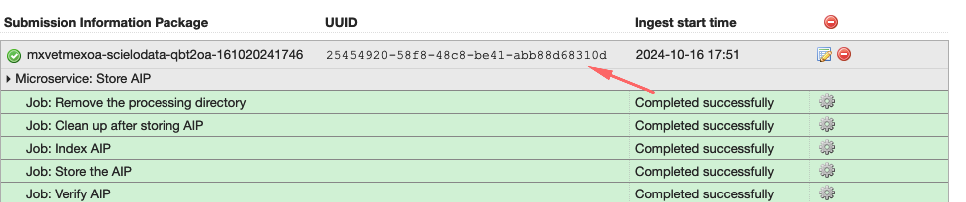
UUID DO AIP: Identificador único do AIP.

-
UUID DO REPLICATOR DIGITAL OCEAN: Clique em Job: Store de AIP e busque por replicas.
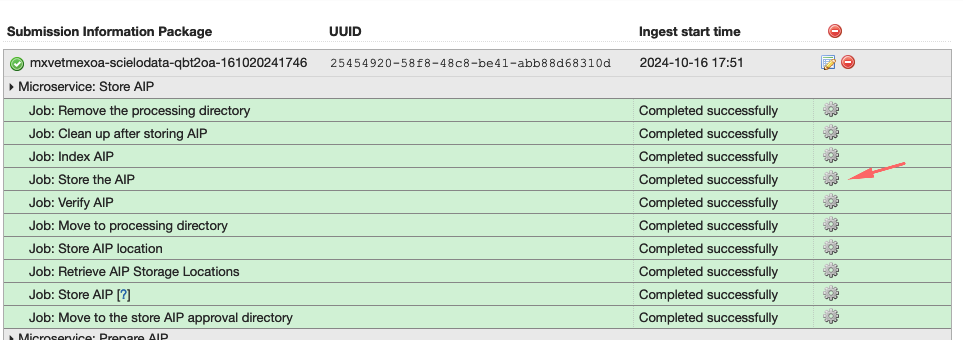
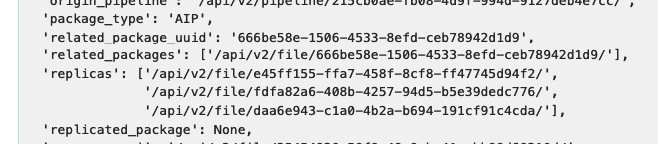
-
UUID DO REPLICATOR MINIO: Clique em Job: Store de AIP e busque por replicas.
-
UUID DO REPLICATOR AWS: Clique em Job: Store de AIP e busque por replicas.
-
CHECKSUM DO AIP
-
CHECKSUM DO DIP
-
AtoM: Corresponde a url do DIP no AtoM
Quando a transferência é feita por grupo de datasets
Esse tipo está considerando a transferência de datasets por grupos onde os pacotes SIP são BagITs criados mensalmente e que tem tamanho de 1GB cada grupo.
O padrão de nome adotado para transferências dos conjuntos de dados do Data SciELO ficou:
scielodata-<mês>-<ano>-<sequência>
Exemplo: scielodata-agosto-2025-01
Para iniciar o processo de transferência, clique no botão Browse para listar as coleções. Selecione a coleção, conforme a imagem abaixo:

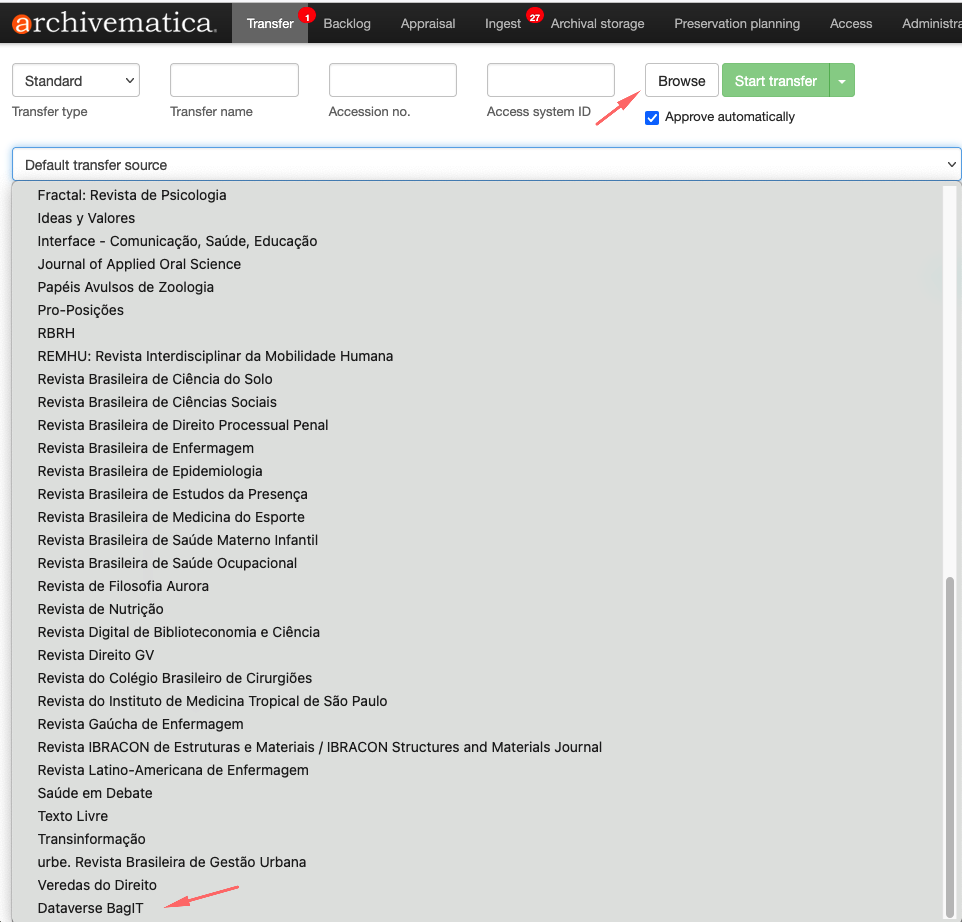
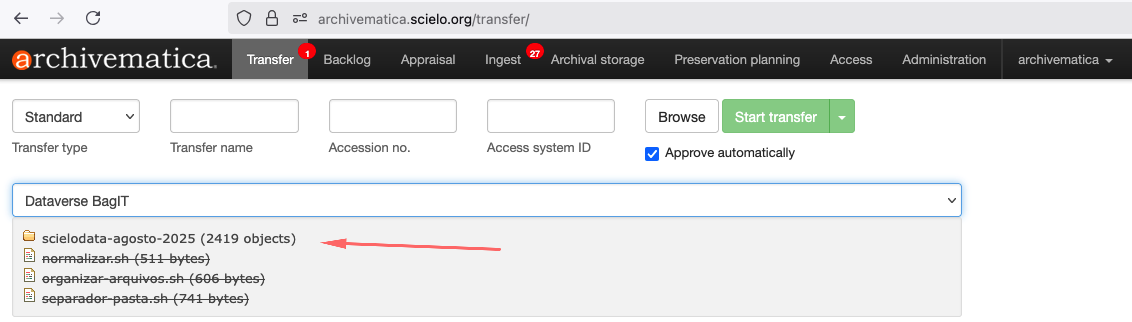
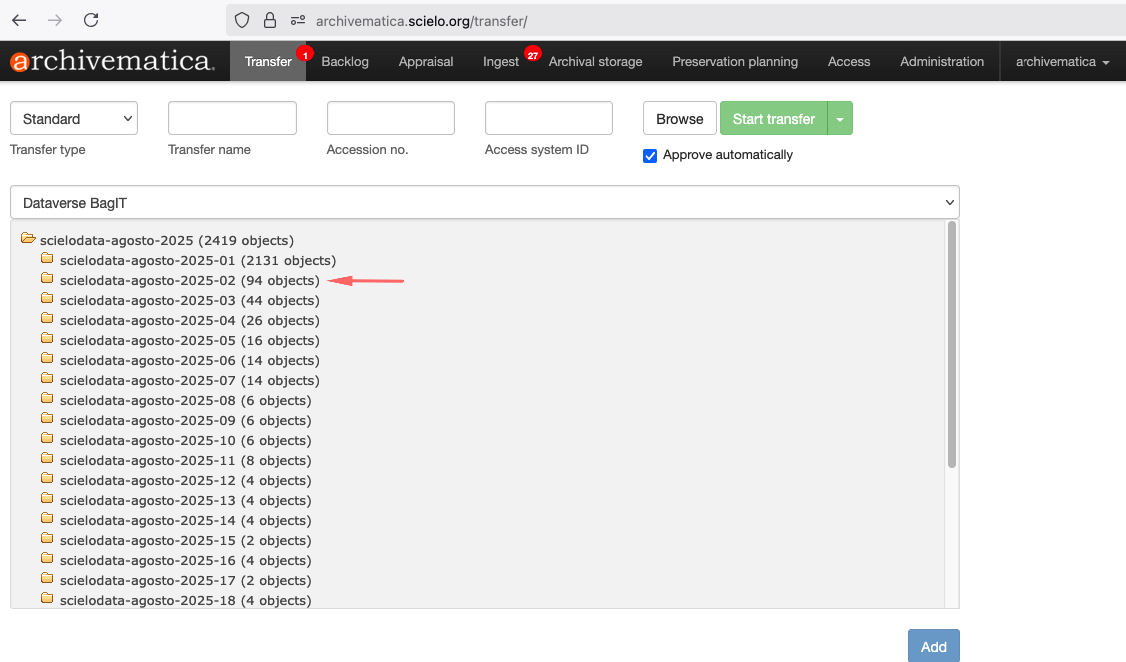
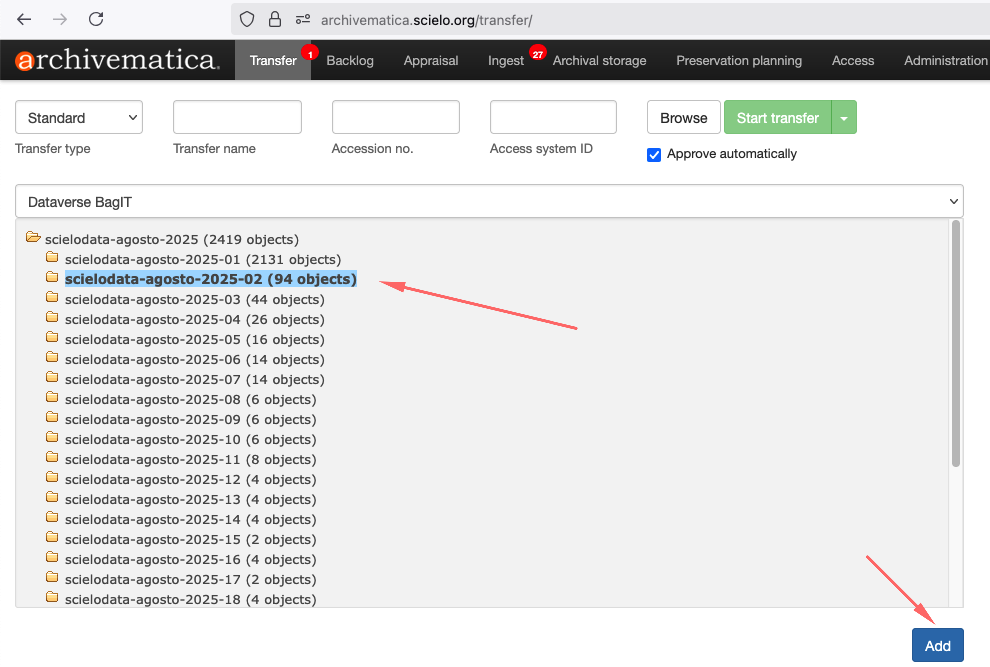
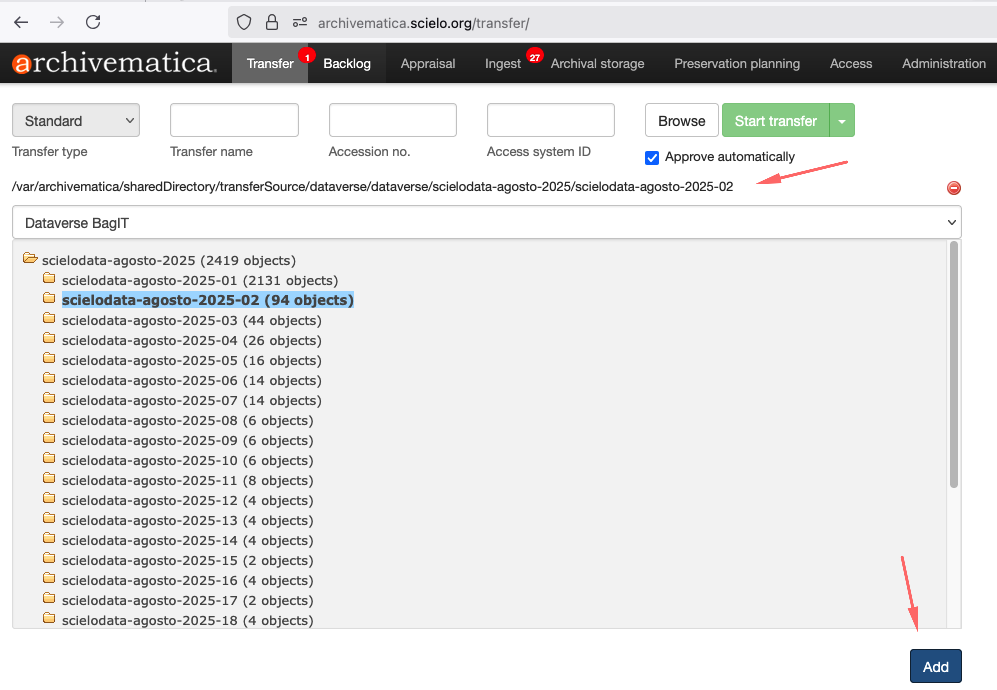
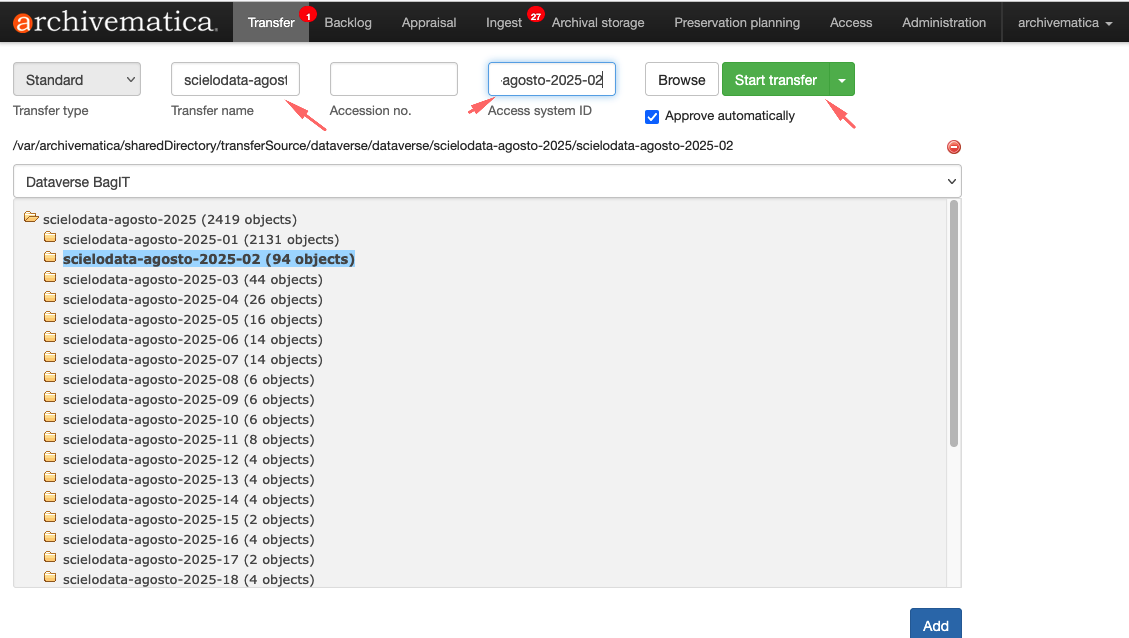
Adicionando no ATOM
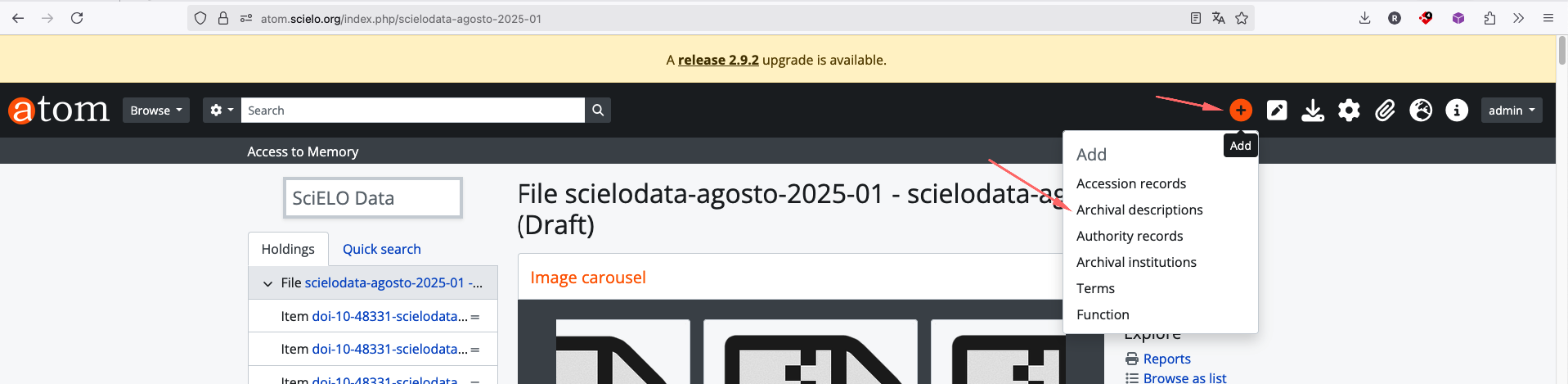
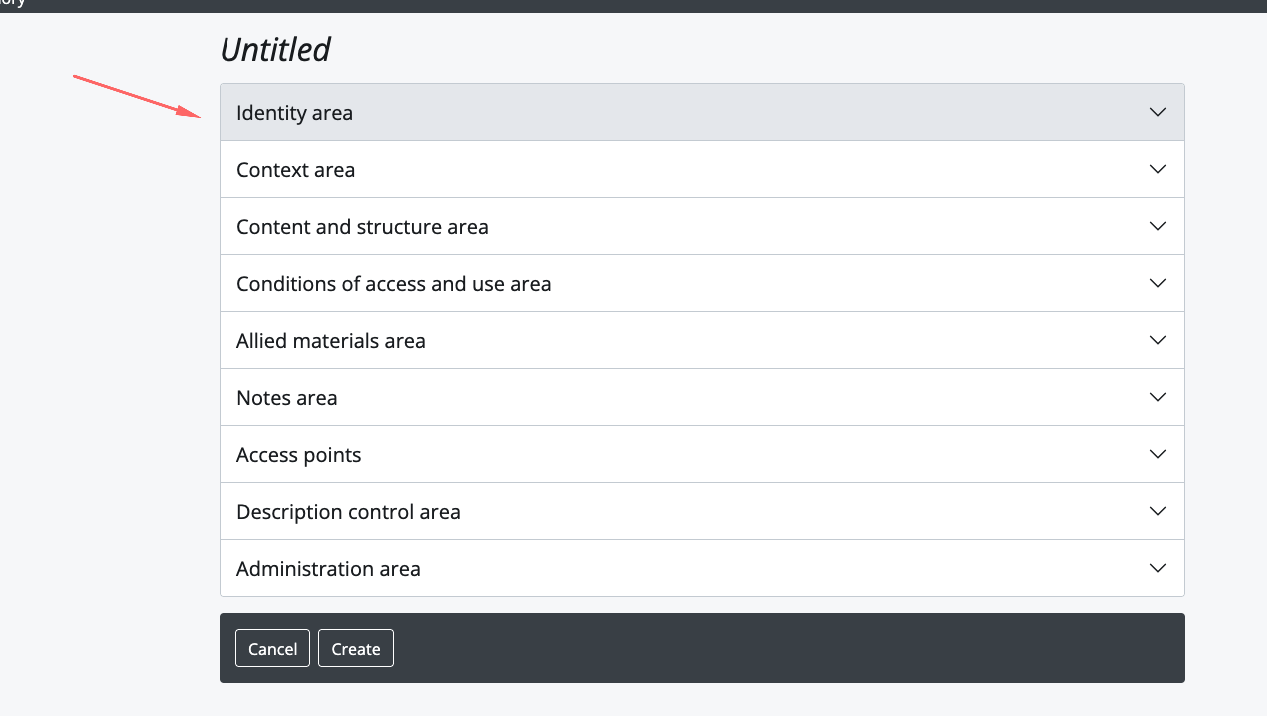
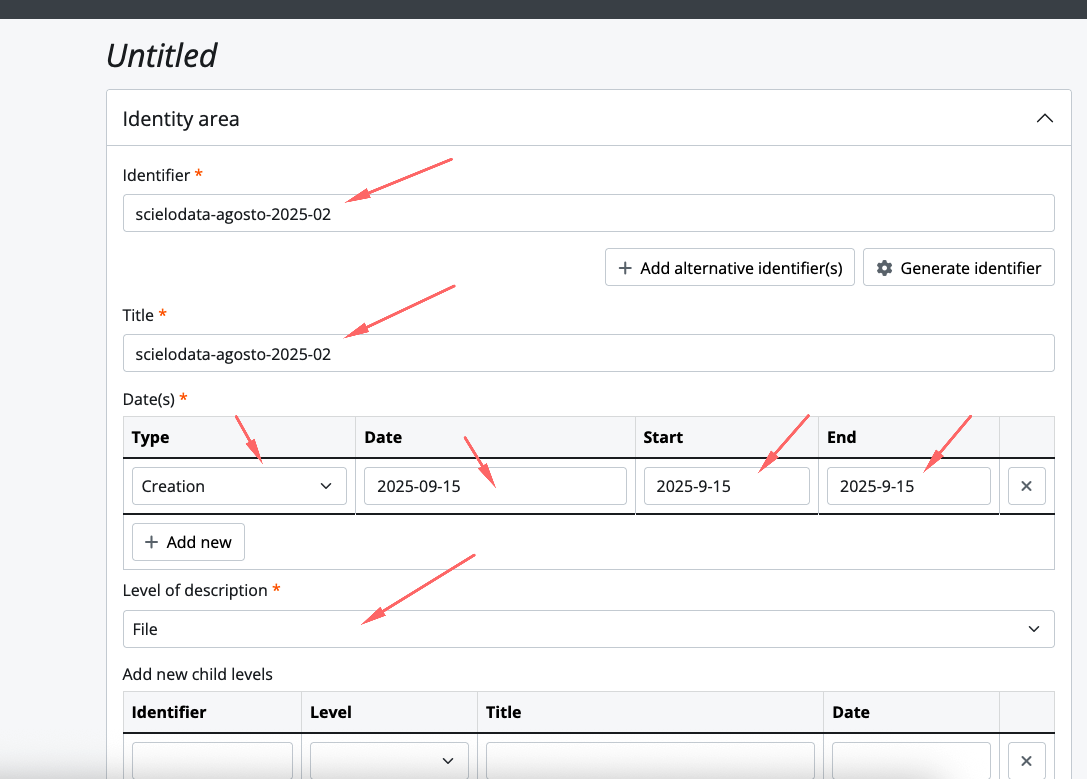
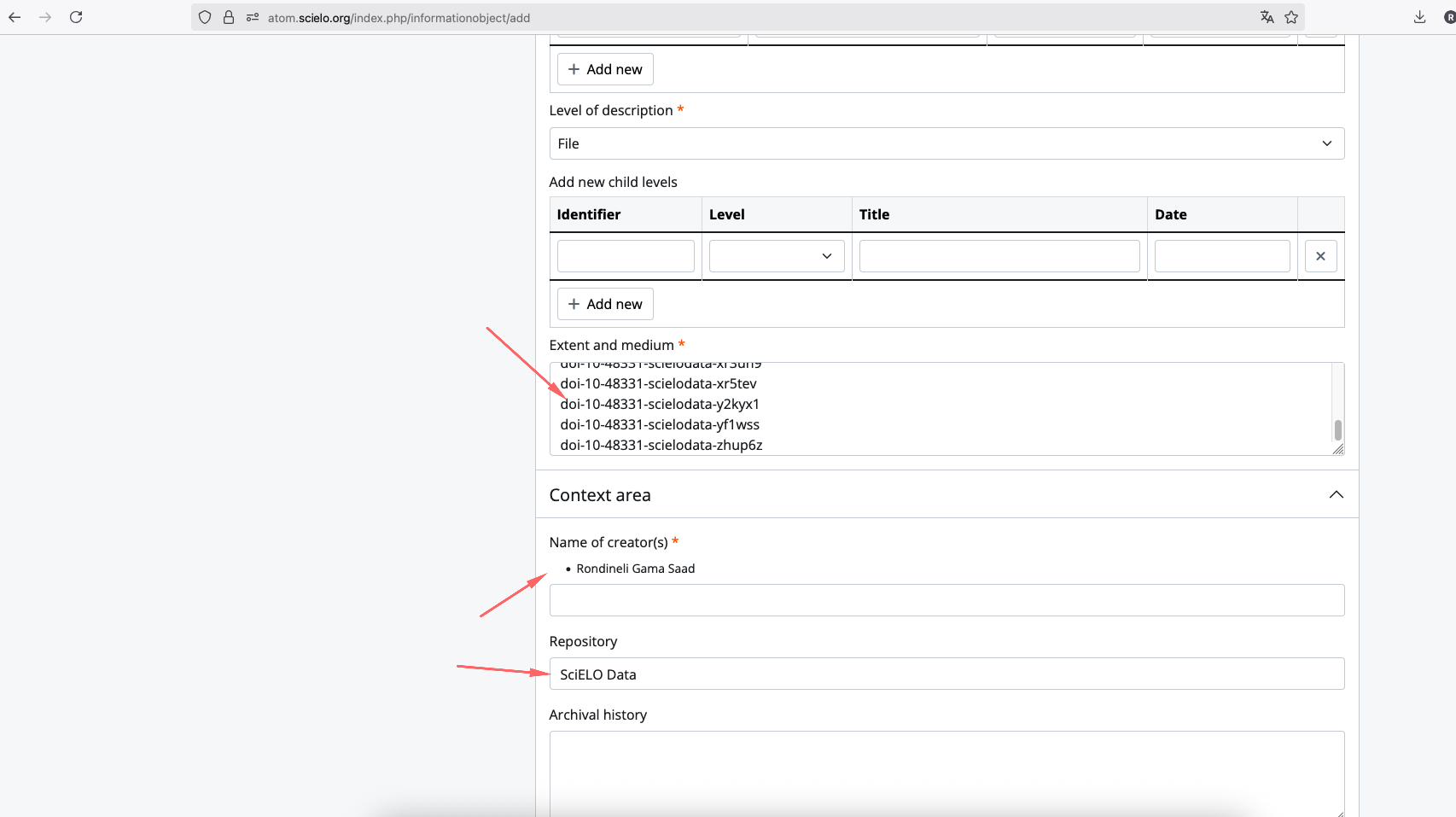
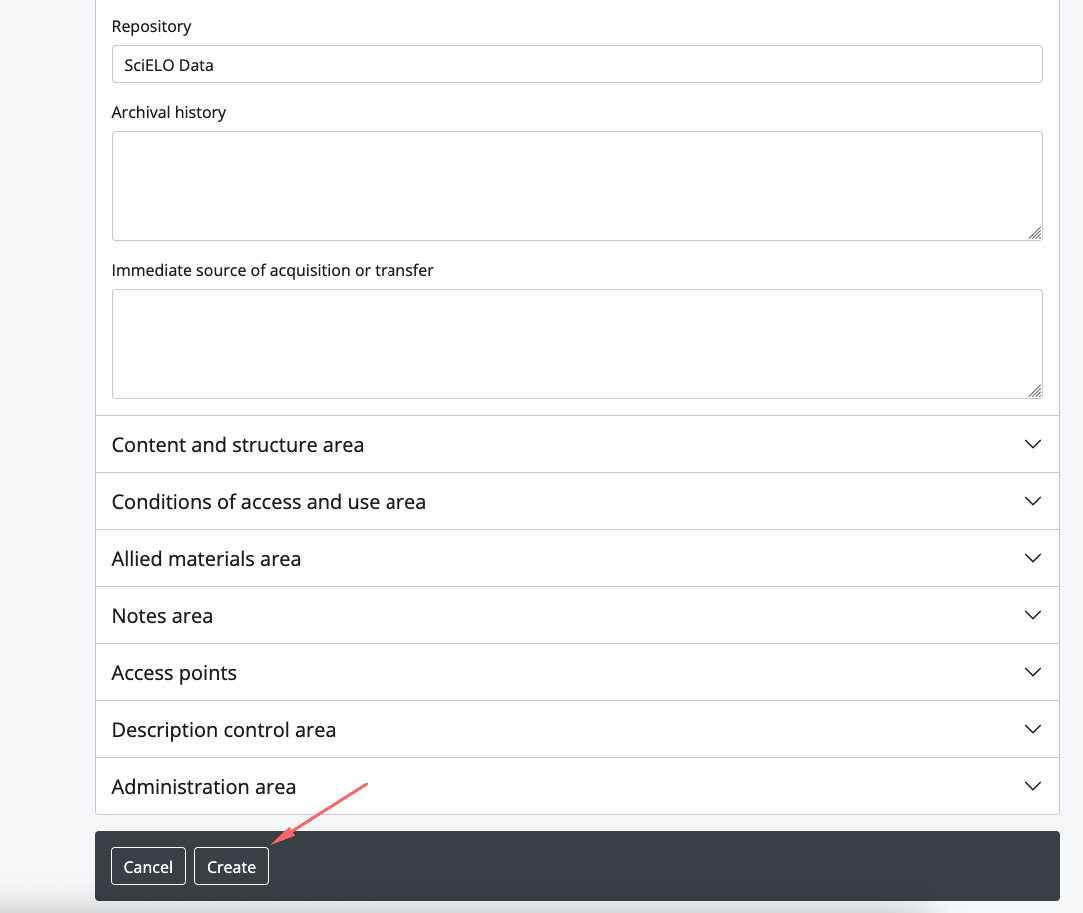
FLUXO DE PRESERVAÇÃO DIGITAL USANDO O ARCHIVEMATICA E O ATOM
Esta documentação visa apresentar o fluxo de preservação digital do site SciELO e seus objetos digitais. Estes objetos digitais fazem parte do pacote enviados pelos editores para produzir o conteúdo no site.
Objetivo
Apresentar o fluxo de preservação digital utilizando o Archivematica e o AtoM.
Archivematica
O Archivematica é um conjunto integrado de ferramentas de código aberto que permite o processamento de objetos digitais desde o ingresso até o acesso. Baseado em padrões em conformidade com o modelo funcional ISO-OAIS permite preservar o acesso de longo prazo a conteúdo digital confiável, autêntico e seguro. O Archivematica usa o METS, PREMIS, Dublin Core, a especificação BagIt da Library of Congress e outros normas reconhecidos para gerar Pacotes de Informações de Arquivamento (AIPs) confiáveis, autênticos, seguros e independentes do sistema para armazenamento em seu repositório preferido.
No Format Policy Registry (FPR), o Archivematica implementa suas políticas de formato padrão com base em uma análise das características significativas dos formatos de arquivo. O FPR também oferece uma estrutura editável e flexível para identificação de formatos, extração de pacotes, transcrição e normalização para preservação e acesso. Sua instituição pode atualizar ferramentas, regras e comandos em seu FPR local a partir do servidor FPR gerenciado pela Artefactual. Você também pode adicionar suas próprias políticas locais ao FPR interno. O FPR é integrado ao PRONOM.
O Archivematica integra aos sistemas: dSpace, CONTENTdm, Islandora, LOCKSS, AtoM, DuraCloud, OpenStack, Archivists'Toolkit, Arkivum, ArchivesSpace.
Usuários monitoram e controlam a ingestão e a preservação através de micro-serviços que são gerenciados através de um painel baseado em web.
Manual de uso
Acesse o site https://archivematica.scielo.org
Guia Transferência
A guia Transferência é o local onde muitos usuários iniciam o processo de transformar seus objetos digitais em Pacotes de Informações de Arquivamento (AIPs). Na guia Transferência, os usuários selecionam o material a ser preservado, nomeiam a transferência e iniciam o processo de transferência.
A seção na parte superior da guia Transferência é onde você encontrará materiais para transferência para o Archivematica. Existem quatro campos a serem preenchidos, os botões Browse e Start transfer e a caixa de seleção Approve automatically
- Tipo de transferência : o tipo de material que está sendo transferido. Consulte Tipos de transferência para obter mais informações.
- Nome da transferência : um nome para sua transferência. Este se tornará o nome do pacote de informações de arquivamento (AIP) resultante. Este é um campo obrigatório.
- Adesão no. : A inserção de um número de acesso para sua transferência resultará na cópia do número de acesso no arquivo AIP METS como um evento de registro. Não é usado para identificar ou procurar o AIP no Archivematica. Este campo é opcional.
- ID do sistema de acesso : inserir um campo de ID do sistema de acesso ao configurar sua transferência permite automatizar o processo de upload de um DIP para o AtoM. O Archivematica automaticamente captura esse valor quando alcançar o microsserviço DIP de upload. Consulte Carregar um DIP para AtoM para obter mais informações. Este campo é opcional.
- Procurar : O botão Procurar alterna para abrir o navegador de transferência. Isso permite que os usuários visualizem e naveguem pelos locais configurados da fonte de transferência. Para obter mais informações sobre como configurar locais de origem de transferência que o Archivematica pode acessar, consulte o Manual do administrador - Serviço de armazenamento . Selecionar um diretório e clicar em Adicionar adiciona o diretório de materiais à transferência.
- Iniciar transferência : depois de atribuir à sua transferência um nome e o material selecionado no navegador de transferências, o botão Iniciar transferência inicia os microsserviços de transferência.
- Aprovar automaticamente : se esta caixa estiver desmarcada, o Archivematica fará uma pausa no primeiro micros serviço, Aprovar transferência , e você terá a chance de confirmar que sua transferência foi configurada corretamente. Se a caixa estiver marcada, o Archivematica não fará uma pausa nesta etapa.
Definindo o nome da transferência
O padrão de nome adotado para transferências dos conjuntos de dados do Data SciELO ficou:
<acrônimo do periódico no dataverse>-<identificador DOI>-<dia-mes-ano-hora-minuto>
Exemplo: mxvetmexoa-scielodata-qbt2oa-161020241746
Este exemplo corresponde ao conjunto de dados com a https://data.scielo.org/dataset.xhtml?persistentId=doi:10.48331/scielodata.QBT2OA
Para iniciar o processo de transferência, clique no botão Browse para listar as coleções. Selecione a coleção, conforme a imagem abaixo:
Ao selecionar a coleção, os datasets aparecerão.
Selecione o dataset e clique no botão Add
Importante que antes de pressionar o botão Start Transfer, execute o procedimento abaixo:
PREPARANDO O ATOM PARA RECEBER O DIP
Acesse https://atom.scielo.org/
A url criada foi https://atom.scielo.org/index.php/mxvetmexoa-scielodata-qbt2oa
Ao finalizar o procedimento de preparação do AtoM, clique no botão Start transfer para iniciar o processo.
Se não houver erro, o processo de ingestão iniciará.
Depois que uma transferência é iniciada, ela aparece abaixo da área de preparação da transferência. Vários microsserviços executam o material transferido para prepará-lo para se tornar um SIP. A lista de microsserviços deve ser lida de baixo para cima.
No final do processo de transferência, o material transferido pode ser enviado para o backlog , onde pode ser armazenado até que você esteja pronto para transformá-lo em um AIP. O backlog também oferece aos usuários a chance de realizar tarefas de avaliação . Como alternativa, o usuário pode transformar o material transferido em um SIP e enviá-lo para a guia Ingest .
Você pode limpar a guia Transferência removendo transferências concluídas ou rejeitadas. Para obter mais informações, consulte Limpando a guia Transferir abaixo.
ALIMENTANDO A PLANILHA DE CONTROLE
Uma vez que o fluxo de ingest finalize, é necessário adicionar na planilha [ARCHIVEMATICA] PRESERVAÇÃO DIGITAL DATAVERSE o pacote que foi preservado. Cada aba da planilha corresponde a gestão dos conjuntos de dados que foram preservador.
Os campos a serem preenchidos são:
- DATA DE SUBMISSÃO: Corresponde quando o fluxo foi executado.
- ACRONIMO: Corresponde ao acrônimo da revista no Data SciELO
- DATASET (DOI): O identificador único do conjunto de dados
- TRANSFER NAME: Nome de indentificação de transferência
-
ACCESS SYSTEM ID: ID de acesso ao sistema.
-
UUID DO AIP: Identificador único do AIP.
-
UUID DO REPLICATOR DIGITAL OCEAN: Clique em Job: Store de AIP e busque por replicas.
-
UUID DO REPLICATOR MINIO: Clique em Job: Store de AIP e busque por replicas.
-
UUID DO REPLICATOR AWS: Clique em Job: Store de AIP e busque por replicas.
-
CHECKSUM DO AIP
-
CHECKSUM DO DIP
-
AtoM: Corresponde a url do DIP no AtoM