PRESERVAÇÃO DIGITAL
- COMO CONSULTAR O STATUS DE PRESERVAÇÃO DO PERIÓDICO
- PLANO DE PRESERVAÇÃO REDE SCIELO
- MODELO DE AVALIAÇÃO E MONITORAMENTO DE OBJETOS DIGITAIS
- IMPLEMENTAÇÃO DO MONITORAMENTO DE TAXA DE OBSOLESCÊNCIA DOS FORMATOS
- Lista de Formatos Obsoletos e em Risco baseada no PRONOM
- Lista de Formatos Obsoletos e em Risco usando o Siegfried
- PREPARANDO O AMBIENTE PARA USAR O DROID, SIEGFRIED E JHOVE
- MONITORANDO A INTEGRIDADE DOS ARQUIVOS PRESERVADOS
- COMO CONFIGURAR UMA REDE LOCKSS
COMO CONSULTAR O STATUS DE PRESERVAÇÃO DO PERIÓDICO
Desde 2016 o SciELO faz parte oficialmente da Rede CARINIANA/LOCKSS de preservação. A rede CARINIANA é uma das agências de arquivamento reconhecida pela ISSN International Centre ) juntamente com o CLOCKSS, Portico, LOCKSS e outros. O termo "Agência de Arquivamento" refere-se a uma organização ou iniciativa que está executando um programa para o arquivamento de longo prazo de periódicos eletrônicos e outros recursos contínuos e pode relatar sobre os materiais arquivados usando o ISSN. Cada agência que participa do Keepers Registry fornece regularmente ao ISSN International Center os metadados de seus acervos. Esses metadados são então incluídos no Registro ISSN que é a fonte de informação para o Portal ISSN.
CONSULTANDO O STATUS DE PRESERVAÇÃO
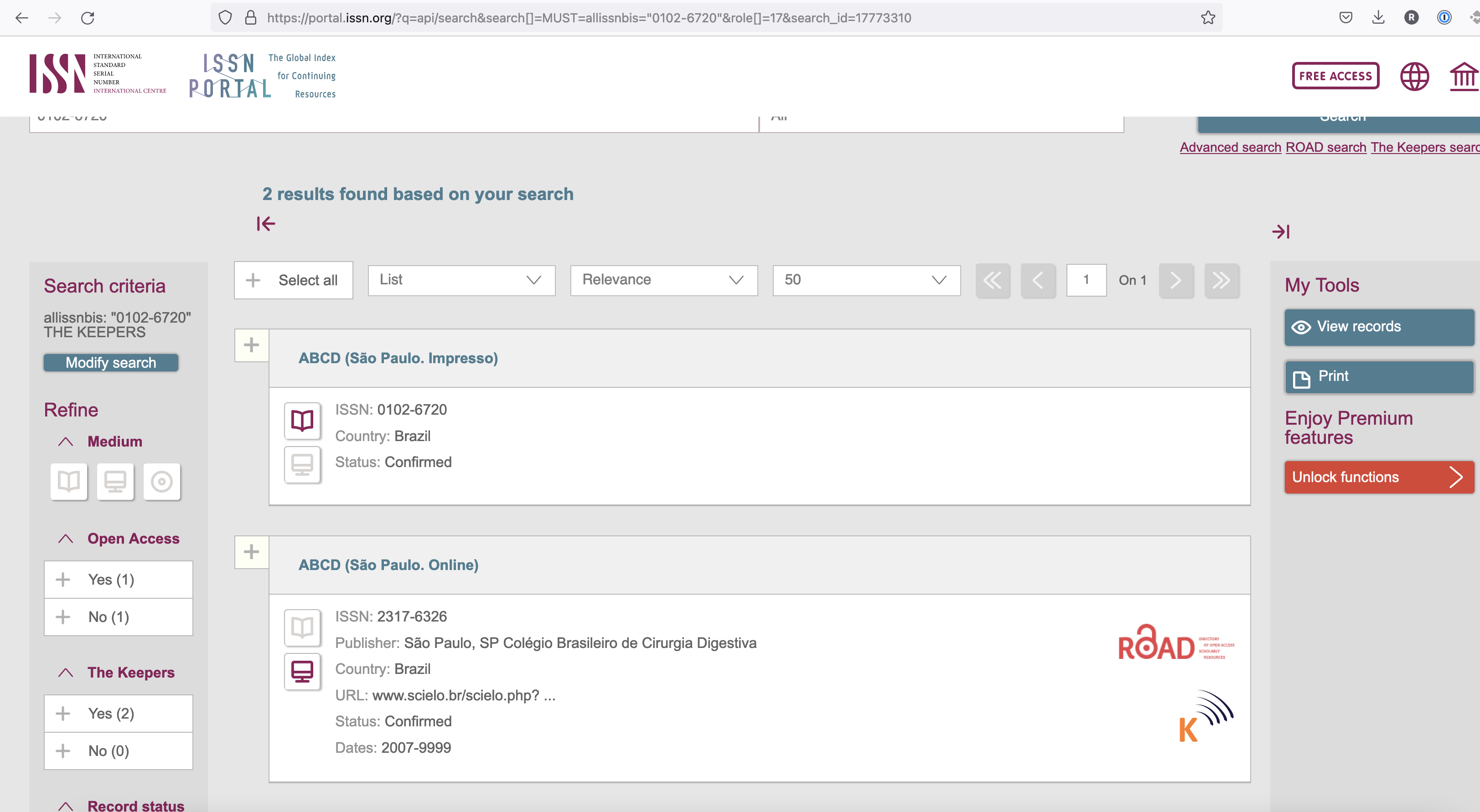
Para consultar o status de preservação de um periódico basta entrar no site https://keepers.issn.org/ e no campo "ALL, ISSN, Title".

Digite o ISSN do periódico e clique no botão Search.

Ao fazer a busca, vai aparecer o resultado com o nome do Periódico, basta clicar no Periódico com o termo Online. No exemplo abaixo, buscamos pelo periódico ABCD, veja que há dois resultados, clique em ABCD (São Paulo. Online).
Clique na aba "Archival Status" para exibir o status de preservação.
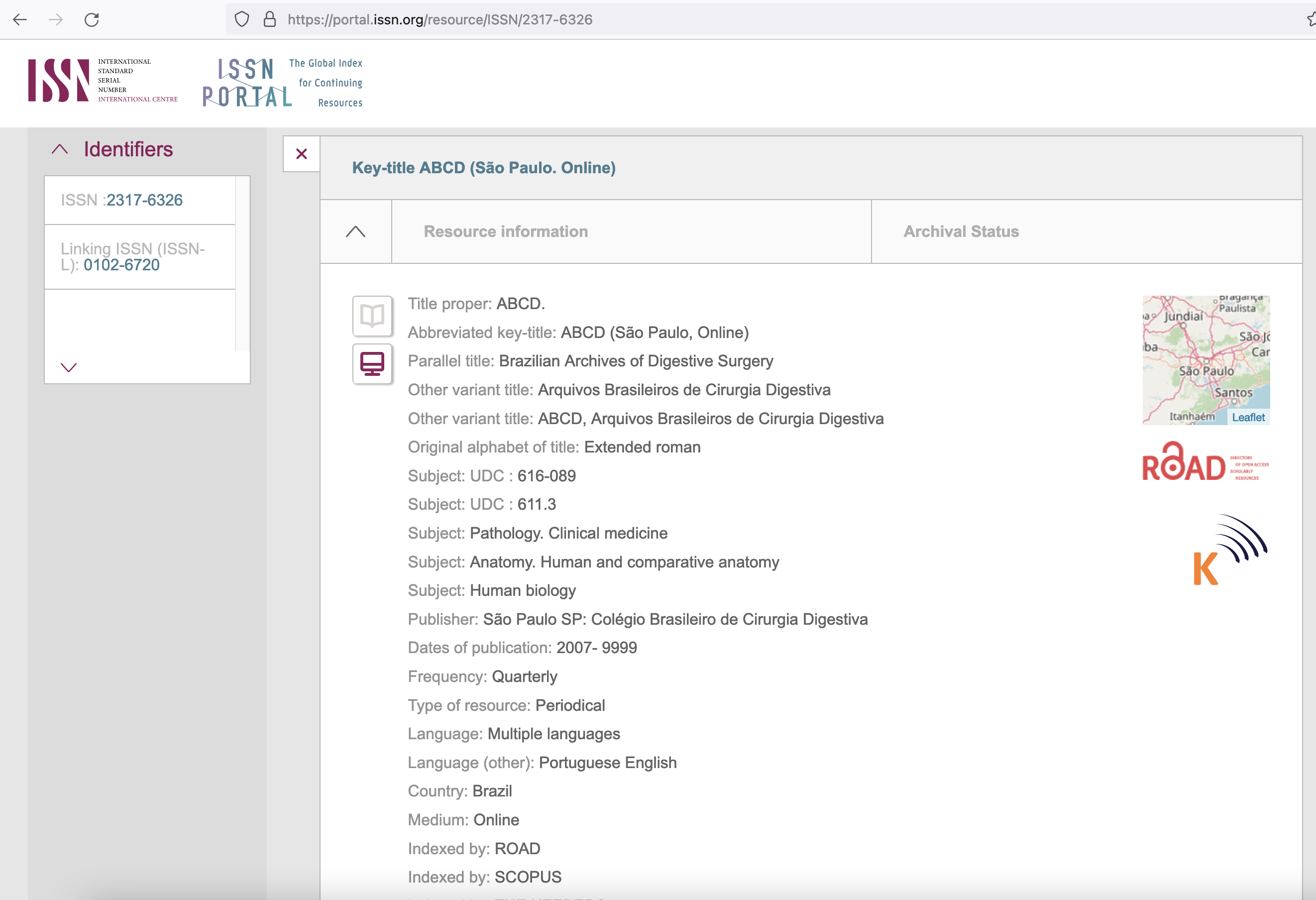
Segue o resultado:

O status "In Progress" significa que o Publisher está realizando ainda a preservação de forma contínua.
PLANO DE PRESERVAÇÃO REDE SCIELO

Política Relacionada
Política de Preservação Digital do Programa SciELO
Objetivo
O plano de preservação da rede SciELO tem como objetivo básico preservar cada coleção da rede através da Rede de Preservação CARINIANA - LOCKSS. A fim de garantir a confidencialidade, integridade e disponibilidade do website da coleção e seu respectivo conteúdo ao longo do tempo.
Escopo
Este plano de preservação digital se aplica a todos os membros da rede SciELO. Isso inclui a todos os recursos digitais inserido no website da coleção. Isso inclui documentos pdf, xml, html e imagens.
Definições
- Servidor: é um computador ou dispositivo especializado que desempenha o papel central na gestão, organização e compartilhamento de recursos e serviços em uma rede de computadores. Esses servidores são projetados para fornecer funcionalidades específicas para os clientes ou dispositivos que estão conectados à rede.
- Cluster de Preservação: é uma configuração na qual dois ou mais computadores são interconectados para trabalhar juntos como uma única unidade, a fim de realizar tarefas computacionais complexas ou para melhorar o desempenho e a confiabilidade de determinadas aplicações. Essa configuração é usada principalmente em situações em que um único computador não é suficiente para lidar com a carga de trabalho exigida.
- Rede de Preservação: é uma estrutura ou colaboração organizada entre instituições, organizações ou entidades que compartilham recursos, conhecimentos e boas práticas relacionadas à preservação e conservação de recursos digitais, como documentos, arquivos digitais, imagens, vídeos e outros tipos de conteúdo digital. O principal objetivo de uma rede de preservação é garantir que esses recursos digitais sejam mantidos a longo prazo, preservando sua acessibilidade, autenticidade e integridade.
- LOCKSS: é um sistema de preservação digital descentralizado que foi desenvolvido para garantir a preservação de conteúdo digital, como periódicos acadêmicos e outros tipos de publicações online.
- Unidade de Arquivamento: é um espaço lógico dedicado ao armazenamento e organização de documentos, arquivos e outros tipos de materiais arquivístico. Uma UA no LOCKSS armazena o volume de um determinado periódico.
- Backup: refere-se ao processo de criar cópias de dados, arquivos ou sistemas de computador para fins de preservação e recuperação em caso de perda de dados, falha de hardware, erros humanos, ataques cibernéticos ou outros eventos adversos. Os backups são essenciais para garantir a disponibilidade e a integridade dos dados, bem como para a continuidade das operações de negócios.
- The Keepers: refere-se a uma organização ou iniciativa que está executando um programa para o arquivamento de longo prazo de periódicos eletrônicos e outros recursos contínuos e pode relatar sobre os materiais arquivados usando o ISSN.
Papéis e Responsabilidades
- Gestor da Unidade de Infraestrutura SciELO Brasil:
- Adicionar novos servidores ao cluster da Rede de Preservação LOCKSS;
- Adicionar novas unidades de arquivamento;
- monitorar o estado de preservação dos volumes;
- Enviar o relatório ao The Keepers para atualizar a base de periódicos preservados;
- Notificar erros que envolva os servidores
- Gestor da coleção:
- Disponibilizar servidor para ser membro do cluster de preservação;
- Garantir que o servidor esteja disponível e acessível no cluster de preservação;
- Monitoramento da saúde do servidor;
- Garantir backup do servidor
Estratégia de Preservação
Participação da sub-rede de Preservação
Requisitos para participar:
- Cada membro da rede precisa se comprometer em configurar na sua rede um servidor para ser membro da rede de preservação. Segue a configuração:
- pelo o menos 500 Gigabytes de disco rígido;
- 8 cpus;
- 8 Gigabytes de memória RAM;
- Conexão com a internet.
- Uma vez atendido o item acima, entrar em contato com a Unidade de Infraestrutura do SciELO Brasil (infra@scielo.org) solicitando a participação.
- O Gestor da Unidade de Infraestrutura do SciELO avaliará a inclusão.
Gerenciamento da sub-rede de Preservação
O SciELO Brasil será responsável por:
- Manter a sub-rede funcionando;
- Monitorar o estado do servidor;
- Adição mensal de novos volumes na preservação;
- Geração de relatórios mensais para o The Keepers atualizar o estado de preservação.
Histórico de versões
| Data |
Versão |
Descrição |
Autor |
| 11/09/2023 |
1.0 |
Criação do documento. |
Rondineli Saad |
MODELO DE AVALIAÇÃO E MONITORAMENTO DE OBJETOS DIGITAIS

IMPLEMENTAÇÃO DO MONITORAMENTO DE TAXA DE OBSOLESCÊNCIA DOS FORMATOS
1. Infraestrutura Base
Banco de Dados de Formatos Crie um repositório central para armazenar informações sobre formatos:
- Nome e extensão do formato
- Versão
- Especificações técnicas
- Status (ativo, obsoleto, em observação)
- Data de inclusão no sistema
- Ferramentas compatíveis
- Nível de risco de obsolescência
Integração com Ferramentas de Identificação
- DROID: Automatize varreduras regulares dos repositórios digitais para identificar formatos em uso
- JHOVE: Configure validações automáticas de integridade e conformidade dos arquivos
- Integre os resultados dessas ferramentas ao seu banco de dados central
2. Sistema de Monitoramento Automatizado
Scripts de Auditoria Periódica
Frequência: Mensal ou trimestral
Ações:
- Varredura completa do acervo digital
- Identificação de novos formatos
- Validação de formatos existentes
- Geração de relatórios comparativosMétricas a Coletar
- Total de formatos únicos no acervo
- Formatos suportados vs. não suportados
- Distribuição de arquivos por formato
- Idade média dos formatos
- Formatos em risco de obsolescência
3. Processo de Revisão e Atualização
Fluxo de Trabalho Sugerido:
- Auditoria Automática (mensal)
- Execução das ferramentas DROID/JHOVE
- Consolidação dos dados no banco central
- Análise Técnica (trimestral)
- Revisão de formatos não suportados
- Avaliação de riscos de obsolescência
- Identificação de necessidades de migração
- Revisão Estratégica (anual)
- Atualização da política de formatos
- Planejamento de migrações necessárias
- Avaliação de novas tecnologias
4. Indicadores e Dashboards
KPIs Principais:
- Taxa de cobertura: (Formatos suportados / Total de formatos) × 100
- Taxa de crescimento de formatos: Variação percentual entre auditorias
- Índice de obsolescência: Percentual de arquivos em formatos de alto risco
- Tempo médio para inclusão de novos formatos
Visualizações Recomendadas:
- Gráfico de tendência temporal do número de formatos
- Mapa de calor de distribuição de formatos por coleção
- Alertas para formatos críticos
- Timeline de migrações realizadas e planejadas
5. Ferramentas e Tecnologias
Para Implementação:
- Banco de dados: PostgreSQL ou MongoDB para armazenar metadados de formatos
- Orquestração: Apache Airflow ou cron jobs para automatizar auditorias
- Dashboards: Grafana, Power BI ou Tableau para visualização
- Alertas: Sistema de notificações (email, Slack) para formatos críticos
Ferramentas Open Source Recomendadas:
- DROID (The National Archives, UK)
- JHOVE (Harvard University Library)
- Apache Tika (identificação de tipos de arquivo)
- PRONOM (registro de formatos de arquivo)
6. Documentação e Governança
- Crie uma política formal de preservação digital
- Documente procedimentos de auditoria
- Estabeleça critérios claros para avaliação de risco
- Defina responsáveis por cada etapa do processo
- Mantenha um registro histórico de todas as decisões
7. Plano de Ação Inicial
Fase 1 (1-2 meses): Levantamento inicial
- Inventário completo do acervo
- Instalação e configuração das ferramentas
- Criação do banco de dados de formatos
Fase 2 (2-3 meses): Automação
- Desenvolvimento de scripts de auditoria
- Configuração de processos automatizados
- Criação de dashboards básicos
Fase 3 (Contínua): Operação e melhoria
- Execução regular das auditorias
- Análise de tendências
- Refinamento do processo
Essa abordagem permite começar de forma simples e escalar conforme necessário, sempre mantendo visibilidade sobre o estado tecnológico do seu acervo digital.
Implementação Prática com DROID e JHOVE
Vou mostrar como configurar e automatizar essas ferramentas:
1. DROID - Identificação de Formatos
Instalação e Configuração
Download e Setup:
# Download do DROID
wget https://github.com/digital-preservation/droid/releases/download/6.9.9/droid-binary-6.9.9-bin.zip
# Descompactar
unzip droid-binary-6.9.9-bin.zip -d /opt/droid
# Tornar executável
chmod +x /opt/droid/droid.shUso via Interface Gráfica
- Execute:
./droid.sh - Crie um novo perfil
- Adicione diretórios para varredura
- Execute a análise
- Exporte relatórios (CSV, PDF, DROID Report)
Automação via Linha de Comando
Script básico de varredura:
#!/bin/bash
# scan_droid.sh
# Variáveis
DROID_HOME="/opt/droid"
REPOSITORY_PATH="/caminho/para/seu/repositorio"
OUTPUT_DIR="/var/droid/reports"
DATE=$(date +%Y%m%d_%H%M%S)
PROFILE_NAME="scan_${DATE}.droid"
REPORT_NAME="report_${DATE}.csv"
# Criar perfil e executar varredura
$DROID_HOME/droid.sh -a "$REPOSITORY_PATH" -p "$OUTPUT_DIR/$PROFILE_NAME"
# Gerar relatório CSV
$DROID_HOME/droid.sh -p "$OUTPUT_DIR/$PROFILE_NAME" -e "$OUTPUT_DIR/$REPORT_NAME"
# Gerar relatório detalhado
$DROID_HOME/droid.sh -p "$OUTPUT_DIR/$PROFILE_NAME" -r "$OUTPUT_DIR/detailed_${DATE}.pdf"
echo "Varredura concluída: $OUTPUT_DIR/$REPORT_NAME"Tornar executável:
chmod +x scan_droid.shAnálise dos Resultados do DROID
Script Python para processar relatórios CSV:
#!/usr/bin/env python3
# analyze_droid_report.py
import pandas as pd
import json
from datetime import datetime
from collections import Counter
def analyze_droid_report(csv_file):
"""Analisa relatório CSV do DROID"""
# Ler CSV
df = pd.read_csv(csv_file)
# Análise de formatos
formats = df['FORMAT_NAME'].dropna()
format_counts = Counter(formats)
# Análise por extensão
extensions = df['EXT'].dropna()
ext_counts = Counter(extensions)
# Estatísticas gerais
stats = {
'data_analise': datetime.now().isoformat(),
'total_arquivos': len(df),
'total_formatos_unicos': len(format_counts),
'total_extensoes_unicas': len(ext_counts),
'top_10_formatos': dict(format_counts.most_common(10)),
'top_10_extensoes': dict(ext_counts.most_common(10)),
'arquivos_sem_identificacao': len(df[df['FORMAT_NAME'].isna()]),
'tamanho_total_mb': df['SIZE'].sum() / (1024 * 1024)
}
# Identificar formatos em risco
formatos_obsoletos = identify_obsolete_formats(format_counts)
stats['formatos_obsoletos'] = formatos_obsoletos
# Salvar análise
output_file = f"analysis_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json"
with open(output_file, 'w') as f:
json.dump(stats, f, indent=2)
print(f"Análise salva em: {output_file}")
return stats
def identify_obsolete_formats(format_counts):
"""Identifica formatos potencialmente obsoletos"""
# Lista de formatos conhecidos como obsoletos ou em risco
obsolete_keywords = [
'WordPerfect', 'Lotus', 'dBase', 'PageMaker',
'Harvard Graphics', 'QuarkXPress'
]
obsolete = {}
for format_name, count in format_counts.items():
for keyword in obsolete_keywords:
if keyword.lower() in format_name.lower():
obsolete[format_name] = count
break
return obsolete
if __name__ == "__main__":
import sys
if len(sys.argv) < 2:
print("Uso: python analyze_droid_report.py <arquivo.csv>")
sys.exit(1)
analyze_droid_report(sys.argv[1])2. JHOVE - Validação de Integridade
Instalação
# Download do JHOVE
wget http://software.openpreservation.org/rel/jhove-latest.jar
# Configurar PATH
export JHOVE_HOME=/opt/jhove
export PATH=$PATH:$JHOVE_HOME/binScript de Validação Automatizada
#!/bin/bash
# validate_jhove.sh
JHOVE_HOME="/opt/jhove"
REPOSITORY_PATH="/caminho/para/seu/repositorio"
OUTPUT_DIR="/var/jhove/reports"
DATE=$(date +%Y%m%d_%H%M%S)
REPORT_FILE="$OUTPUT_DIR/jhove_report_${DATE}.xml"
# Criar diretório de saída
mkdir -p "$OUTPUT_DIR"
# Executar JHOVE recursivamente
$JHOVE_HOME/bin/jhove -h XML -o "$REPORT_FILE" -kr "$REPOSITORY_PATH"
echo "Validação concluída: $REPORT_FILE"
# Análise básica do relatório
grep -c "Status: Well-Formed and valid" "$REPORT_FILE" > "$OUTPUT_DIR/valid_count_${DATE}.txt"
grep -c "Status: Not well-formed" "$REPORT_FILE" > "$OUTPUT_DIR/invalid_count_${DATE}.txt"Script Python para Análise do JHOVE
#!/usr/bin/env python3
# analyze_jhove_report.py
import xml.etree.ElementTree as ET
import json
from datetime import datetime
from collections import defaultdict
def analyze_jhove_report(xml_file):
"""Analisa relatório XML do JHOVE"""
tree = ET.parse(xml_file)
root = tree.getroot()
# Namespace do JHOVE
ns = {'jhove': 'http://hul.harvard.edu/ois/xml/ns/jhove'}
results = {
'data_analise': datetime.now().isoformat(),
'total_arquivos': 0,
'validos': 0,
'invalidos': 0,
'bem_formados': 0,
'erros_por_formato': defaultdict(list),
'formatos_analisados': defaultdict(int)
}
# Processar cada arquivo
for repInfo in root.findall('.//jhove:repInfo', ns):
results['total_arquivos'] += 1
# Obter status
status = repInfo.find('.//jhove:status', ns)
formato = repInfo.find('.//jhove:format', ns)
filepath = repInfo.get('uri', 'unknown')
if status is not None:
status_text = status.text
if 'valid' in status_text.lower():
results['validos'] += 1
else:
results['invalidos'] += 1
# Coletar mensagens de erro
messages = repInfo.findall('.//jhove:message', ns)
for msg in messages:
error_msg = msg.text
formato_nome = formato.text if formato is not None else 'unknown'
results['erros_por_formato'][formato_nome].append({
'arquivo': filepath,
'erro': error_msg
})
if 'well-formed' in status_text.lower():
results['bem_formados'] += 1
# Contar formatos
if formato is not None:
results['formatos_analisados'][formato.text] += 1
# Converter defaultdict para dict normal
results['erros_por_formato'] = dict(results['erros_por_formato'])
results['formatos_analisados'] = dict(results['formatos_analisados'])
# Calcular percentuais
if results['total_arquivos'] > 0:
results['percentual_validos'] = (results['validos'] / results['total_arquivos']) * 100
results['percentual_invalidos'] = (results['invalidos'] / results['total_arquivos']) * 100
# Salvar análise
output_file = f"jhove_analysis_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json"
with open(output_file, 'w') as f:
json.dump(results, f, indent=2)
print(f"Análise JHOVE salva em: {output_file}")
print(f"Total de arquivos: {results['total_arquivos']}")
print(f"Válidos: {results['validos']} ({results.get('percentual_validos', 0):.2f}%)")
print(f"Inválidos: {results['invalidos']} ({results.get('percentual_invalidos', 0):.2f}%)")
return results
if __name__ == "__main__":
import sys
if len(sys.argv) < 2:
print("Uso: python analyze_jhove_report.py <arquivo.xml>")
sys.exit(1)
analyze_jhove_report(sys.argv[1])3. Integração e Automação Completa
Script Master de Orquestração
#!/bin/bash
# master_preservation_scan.sh
set -e
# Configurações
BASE_DIR="/var/preservation"
REPOSITORY="/caminho/para/repositorio"
DROID_SCRIPT="/opt/scripts/scan_droid.sh"
JHOVE_SCRIPT="/opt/scripts/validate_jhove.sh"
PYTHON_ANALYZE="/opt/scripts/analyze_droid_report.py"
JHOVE_ANALYZE="/opt/scripts/analyze_jhove_report.py"
LOG_FILE="$BASE_DIR/logs/scan_$(date +%Y%m%d_%H%M%S).log"
# Criar estrutura de diretórios
mkdir -p "$BASE_DIR"/{logs,reports,droid,jhove,database}
echo "=== Iniciando Varredura de Preservação Digital ===" | tee -a "$LOG_FILE"
echo "Data: $(date)" | tee -a "$LOG_FILE"
# 1. Executar DROID
echo "--- Executando DROID ---" | tee -a "$LOG_FILE"
$DROID_SCRIPT 2>&1 | tee -a "$LOG_FILE"
# Encontrar último relatório DROID
LATEST_DROID=$(ls -t /var/droid/reports/report_*.csv | head -1)
# 2. Analisar relatório DROID
echo "--- Analisando relatório DROID ---" | tee -a "$LOG_FILE"
python3 $PYTHON_ANALYZE "$LATEST_DROID" 2>&1 | tee -a "$LOG_FILE"
# 3. Executar JHOVE
echo "--- Executando JHOVE ---" | tee -a "$LOG_FILE"
$JHOVE_SCRIPT 2>&1 | tee -a "$LOG_FILE"
# Encontrar último relatório JHOVE
LATEST_JHOVE=$(ls -t /var/jhove/reports/jhove_report_*.xml | head -1)
# 4. Analisar relatório JHOVE
echo "--- Analisando relatório JHOVE ---" | tee -a "$LOG_FILE"
python3 $JHOVE_ANALYZE "$LATEST_JHOVE" 2>&1 | tee -a "$LOG_FILE"
# 5. Consolidar resultados
echo "--- Consolidando resultados ---" | tee -a "$LOG_FILE"
python3 /opt/scripts/consolidate_reports.py 2>&1 | tee -a "$LOG_FILE"
echo "=== Varredura Concluída ===" | tee -a "$LOG_FILE"Script de Consolidação
#!/usr/bin/env python3
# consolidate_reports.py
import json
import glob
from datetime import datetime
import sqlite3
def consolidate_reports():
"""Consolida análises do DROID e JHOVE em banco de dados"""
# Conectar ao banco de dados
conn = sqlite3.connect('/var/preservation/database/preservation.db')
cursor = conn.cursor()
# Criar tabelas se não existirem
cursor.execute('''
CREATE TABLE IF NOT EXISTS scans (
id INTEGER PRIMARY KEY AUTOINCREMENT,
data_scan TIMESTAMP,
total_arquivos INTEGER,
total_formatos INTEGER,
arquivos_validos INTEGER,
arquivos_invalidos INTEGER,
tamanho_total_mb REAL
)
''')
cursor.execute('''
CREATE TABLE IF NOT EXISTS formatos (
id INTEGER PRIMARY KEY AUTOINCREMENT,
scan_id INTEGER,
nome_formato TEXT,
quantidade INTEGER,
FOREIGN KEY (scan_id) REFERENCES scans(id)
)
''')
# Encontrar últimas análises
latest_droid = max(glob.glob('analysis_*.json'), key=lambda x: x)
latest_jhove = max(glob.glob('jhove_analysis_*.json'), key=lambda x: x)
# Carregar dados
with open(latest_droid) as f:
droid_data = json.load(f)
with open(latest_jhove) as f:
jhove_data = json.load(f)
# Inserir scan
cursor.execute('''
INSERT INTO scans (data_scan, total_arquivos, total_formatos,
arquivos_validos, arquivos_invalidos, tamanho_total_mb)
VALUES (?, ?, ?, ?, ?, ?)
''', (
datetime.now(),
droid_data['total_arquivos'],
droid_data['total_formatos_unicos'],
jhove_data['validos'],
jhove_data['invalidos'],
droid_data['tamanho_total_mb']
))
scan_id = cursor.lastrowid
# Inserir formatos
for formato, qtd in droid_data['top_10_formatos'].items():
cursor.execute('''
INSERT INTO formatos (scan_id, nome_formato, quantidade)
VALUES (?, ?, ?)
''', (scan_id, formato, qtd))
conn.commit()
conn.close()
print(f"Dados consolidados no banco de dados (Scan ID: {scan_id})")
if __name__ == "__main__":
consolidate_reports()4. Agendamento com Cron
# Editar crontab
crontab -e
# Adicionar linha para execução mensal (dia 1 às 2h da manhã)
0 2 1 * * /opt/scripts/master_preservation_scan.sh
# Ou para execução semanal (toda segunda às 3h da manhã)
0 3 * * 1 /opt/scripts/master_preservation_scan.sh5. Dashboard de Visualização
#!/usr/bin/env python3
# generate_dashboard.py
import sqlite3
import matplotlib.pyplot as plt
import pandas as pd
from datetime import datetime
def generate_dashboard():
"""Gera dashboard com métricas de preservação"""
conn = sqlite3.connect('/var/preservation/database/preservation.db')
# Evolução temporal
df_scans = pd.read_sql_query('''
SELECT data_scan, total_formatos, arquivos_validos,
arquivos_invalidos, tamanho_total_mb
FROM scans
ORDER BY data_scan
''', conn)
# Criar gráficos
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
# Gráfico 1: Evolução de formatos
axes[0, 0].plot(df_scans['data_scan'], df_scans['total_formatos'], marker='o')
axes[0, 0].set_title('Evolução do Número de Formatos')
axes[0, 0].set_xlabel('Data')
axes[0, 0].set_ylabel('Total de Formatos')
axes[0, 0].grid(True)
# Gráfico 2: Validade dos arquivos
axes[0, 1].plot(df_scans['data_scan'], df_scans['arquivos_validos'],
label='Válidos', marker='o')
axes[0, 1].plot(df_scans['data_scan'], df_scans['arquivos_invalidos'],
label='Inválidos', marker='x')
axes[0, 1].set_title('Integridade dos Arquivos')
axes[0, 1].set_xlabel('Data')
axes[0, 1].set_ylabel('Quantidade')
axes[0, 1].legend()
axes[0, 1].grid(True)
# Gráfico 3: Top formatos do último scan
df_formatos = pd.read_sql_query('''
SELECT nome_formato, quantidade
FROM formatos
WHERE scan_id = (SELECT MAX(id) FROM scans)
ORDER BY quantidade DESC
LIMIT 10
''', conn)
axes[1, 0].barh(df_formatos['nome_formato'], df_formatos['quantidade'])
axes[1, 0].set_title('Top 10 Formatos (Último Scan)')
axes[1, 0].set_xlabel('Quantidade')
# Gráfico 4: Tamanho total
axes[1, 1].plot(df_scans['data_scan'], df_scans['tamanho_total_mb'],
marker='o', color='green')
axes[1, 1].set_title('Evolução do Tamanho Total (MB)')
axes[1, 1].set_xlabel('Data')
axes[1, 1].set_ylabel('Tamanho (MB)')
axes[1, 1].grid(True)
plt.tight_layout()
plt.savefig(f'/var/preservation/reports/dashboard_{datetime.now().strftime("%Y%m%d")}.png',
dpi=300)
print("Dashboard gerado com sucesso!")
conn.close()
if __name__ == "__main__":
generate_dashboard()
Lista de Formatos Obsoletos e em Risco baseada no PRONOM
1. Script para Consultar e Classificar Formatos PRONOM
#!/usr/bin/env python3
# pronom_obsolescence_checker.py
import requests
import json
import csv
from datetime import datetime
from typing import Dict, List
import xml.etree.ElementTree as ET
class PRONOMObsolescenceChecker:
"""
Consulta o registro PRONOM e classifica formatos por risco de obsolescência
"""
def __init__(self):
self.base_url = "https://www.nationalarchives.gov.uk/PRONOM"
self.api_url = "https://www.nationalarchives.gov.uk/pronom"
# Categorias de risco
self.risk_categories = {
'CRÍTICO': [],
'ALTO': [],
'MÉDIO': [],
'BAIXO': [],
'MÍNIMO': []
}
# Palavras-chave para classificação
self.obsolete_keywords = [
'obsolete', 'deprecated', 'discontinued', 'legacy',
'superseded', 'replaced', 'outdated', 'no longer'
]
self.high_risk_vendors = [
'WordPerfect', 'Lotus', 'Corel', 'Borland', 'Novell',
'PageMaker', 'Ventura', 'QuarkXPress', 'FrameMaker',
'Harvard Graphics', 'Aldus', 'Claris'
]
self.proprietary_vendors = [
'Microsoft', 'Adobe', 'Apple', 'Autodesk'
]
def load_pronom_database(self):
"""
Carrega lista de formatos do PRONOM
"""
formats_database = self._get_known_formats_database()
return formats_database
def _get_known_formats_database(self) -> List[Dict]:
"""
Base de dados de formatos conhecidos com classificação de risco
Baseado no PRONOM Registry
"""
formats = [
# FORMATOS DE ALTO RISCO / OBSOLETOS
{
'puid': 'x-fmt/44',
'name': 'WordPerfect Document',
'version': '5.x',
'extension': ['wpd', 'wp', 'wp5'],
'risk_level': 'CRÍTICO',
'vendor': 'WordPerfect Corporation',
'reason': 'Formato proprietário descontinuado, suporte limitado',
'migration_target': 'PDF/A, DOCX, ODT'
},
{
'puid': 'x-fmt/45',
'name': 'WordPerfect Document',
'version': '6.x',
'extension': ['wpd', 'wp6'],
'risk_level': 'ALTO',
'vendor': 'Corel',
'reason': 'Formato proprietário com suporte declinante',
'migration_target': 'PDF/A, DOCX, ODT'
},
{
'puid': 'x-fmt/274',
'name': 'Lotus 1-2-3 Worksheet',
'version': '2-5',
'extension': ['wk1', 'wk3', 'wk4', 'wks'],
'risk_level': 'CRÍTICO',
'vendor': 'IBM/Lotus',
'reason': 'Software descontinuado, formato obsoleto',
'migration_target': 'XLSX, ODS, CSV'
},
{
'puid': 'fmt/341',
'name': 'dBase Database',
'version': 'III-V',
'extension': ['dbf'],
'risk_level': 'ALTO',
'vendor': 'dBase LLC',
'reason': 'Formato legado com suporte limitado',
'migration_target': 'SQLite, CSV, XLSX'
},
{
'puid': 'fmt/467',
'name': 'Harvard Graphics Presentation',
'version': '2.x-3.x',
'extension': ['ch3', 'sho'],
'risk_level': 'CRÍTICO',
'vendor': 'Software Publishing Corporation',
'reason': 'Software descontinuado em 2001',
'migration_target': 'PDF/A, PPTX, ODP'
},
{
'puid': 'x-fmt/88',
'name': 'PageMaker Document',
'version': '6.x-7.x',
'extension': ['pmd', 'pm6', 'p65'],
'risk_level': 'ALTO',
'vendor': 'Adobe (descontinuado)',
'reason': 'Substituído pelo InDesign em 2004',
'migration_target': 'INDD, PDF/A'
},
{
'puid': 'fmt/1214',
'name': 'Ventura Publisher Document',
'version': '4.x-10.x',
'extension': ['vp'],
'risk_level': 'CRÍTICO',
'vendor': 'Corel (descontinuado)',
'reason': 'Descontinuado em 2002',
'migration_target': 'PDF/A, INDD'
},
{
'puid': 'fmt/998',
'name': 'QuarkXPress Document',
'version': '3.x-4.x',
'extension': ['qxd'],
'risk_level': 'MÉDIO',
'vendor': 'Quark',
'reason': 'Versões antigas com compatibilidade limitada',
'migration_target': 'Versão atual do QXD, PDF/A, INDD'
},
# FORMATOS DE MÉDIO RISCO
{
'puid': 'fmt/39',
'name': 'Microsoft Word Document',
'version': '97-2003',
'extension': ['doc'],
'risk_level': 'MÉDIO',
'vendor': 'Microsoft',
'reason': 'Formato legado, substituído por DOCX',
'migration_target': 'DOCX, PDF/A, ODT'
},
{
'puid': 'fmt/61',
'name': 'Microsoft Excel Spreadsheet',
'version': '97-2003',
'extension': ['xls'],
'risk_level': 'MÉDIO',
'vendor': 'Microsoft',
'reason': 'Formato legado, substituído por XLSX',
'migration_target': 'XLSX, ODS, CSV'
},
{
'puid': 'fmt/126',
'name': 'Microsoft PowerPoint Presentation',
'version': '97-2003',
'extension': ['ppt'],
'risk_level': 'MÉDIO',
'vendor': 'Microsoft',
'reason': 'Formato legado, substituído por PPTX',
'migration_target': 'PPTX, ODP, PDF/A'
},
{
'puid': 'fmt/101',
'name': 'Adobe Photoshop',
'version': '3.x-6.x',
'extension': ['psd'],
'risk_level': 'MÉDIO',
'vendor': 'Adobe',
'reason': 'Versões antigas com recursos limitados',
'migration_target': 'PSD atual, TIFF, PNG'
},
{
'puid': 'fmt/124',
'name': 'Macromedia Flash',
'version': 'SWF',
'extension': ['swf'],
'risk_level': 'CRÍTICO',
'vendor': 'Adobe (descontinuado)',
'reason': 'Flash Player descontinuado em 2020',
'migration_target': 'HTML5, MP4, WebM'
},
{
'puid': 'fmt/175',
'name': 'Windows Media Video',
'version': '7-9',
'extension': ['wmv'],
'risk_level': 'MÉDIO',
'vendor': 'Microsoft',
'reason': 'Formato proprietário com suporte declinante',
'migration_target': 'MP4, WebM, MOV'
},
{
'puid': 'fmt/134',
'name': 'RealMedia',
'version': 'RM, RMVB',
'extension': ['rm', 'rmvb'],
'risk_level': 'ALTO',
'vendor': 'RealNetworks',
'reason': 'Formato obsoleto, software descontinuado',
'migration_target': 'MP4, WebM'
},
# FORMATOS DE BAIXO RISCO
{
'puid': 'fmt/412',
'name': 'Microsoft Word Document',
'version': '2007-2019 (OOXML)',
'extension': ['docx'],
'risk_level': 'BAIXO',
'vendor': 'Microsoft',
'reason': 'Formato moderno e amplamente suportado',
'migration_target': 'PDF/A para preservação de longo prazo'
},
{
'puid': 'fmt/214',
'name': 'Microsoft Excel Spreadsheet',
'version': '2007-2019 (OOXML)',
'extension': ['xlsx'],
'risk_level': 'BAIXO',
'vendor': 'Microsoft',
'reason': 'Formato moderno e amplamente suportado',
'migration_target': 'ODS, CSV para preservação'
},
{
'puid': 'fmt/215',
'name': 'Microsoft PowerPoint Presentation',
'version': '2007-2019 (OOXML)',
'extension': ['pptx'],
'risk_level': 'BAIXO',
'vendor': 'Microsoft',
'reason': 'Formato moderno e amplamente suportado',
'migration_target': 'PDF/A para preservação'
},
# FORMATOS DE RISCO MÍNIMO
{
'puid': 'fmt/95',
'name': 'PDF/A',
'version': '1a, 1b, 2, 3',
'extension': ['pdf'],
'risk_level': 'MÍNIMO',
'vendor': 'ISO Standard',
'reason': 'Padrão aberto para preservação digital',
'migration_target': 'N/A - formato de preservação'
},
{
'puid': 'fmt/291',
'name': 'OpenDocument Text',
'version': '1.x',
'extension': ['odt'],
'risk_level': 'MÍNIMO',
'vendor': 'OASIS Standard',
'reason': 'Padrão aberto ISO/IEC 26300',
'migration_target': 'PDF/A para preservação'
},
{
'puid': 'fmt/294',
'name': 'OpenDocument Spreadsheet',
'version': '1.x',
'extension': ['ods'],
'risk_level': 'MÍNIMO',
'vendor': 'OASIS Standard',
'reason': 'Padrão aberto ISO/IEC 26300',
'migration_target': 'CSV para dados tabulares simples'
},
{
'puid': 'fmt/295',
'name': 'OpenDocument Presentation',
'version': '1.x',
'extension': ['odp'],
'risk_level': 'MÍNIMO',
'vendor': 'OASIS Standard',
'reason': 'Padrão aberto ISO/IEC 26300',
'migration_target': 'PDF/A para preservação'
},
{
'puid': 'x-fmt/18',
'name': 'Plain Text',
'version': 'UTF-8',
'extension': ['txt'],
'risk_level': 'MÍNIMO',
'vendor': 'Unicode Consortium',
'reason': 'Formato universal e simples',
'migration_target': 'N/A'
},
{
'puid': 'x-fmt/384',
'name': 'Comma Separated Values',
'version': 'RFC 4180',
'extension': ['csv'],
'risk_level': 'MÍNIMO',
'vendor': 'IETF Standard',
'reason': 'Formato aberto e universal',
'migration_target': 'N/A'
},
{
'puid': 'fmt/11',
'name': 'Portable Network Graphics',
'version': '1.x',
'extension': ['png'],
'risk_level': 'MÍNIMO',
'vendor': 'W3C Standard',
'reason': 'Formato aberto amplamente suportado',
'migration_target': 'N/A'
},
{
'puid': 'fmt/353',
'name': 'JPEG 2000',
'version': 'JP2',
'extension': ['jp2'],
'risk_level': 'BAIXO',
'vendor': 'ISO/IEC Standard',
'reason': 'Padrão aberto para imagens de alta qualidade',
'migration_target': 'PNG, TIFF para preservação'
},
{
'puid': 'fmt/353',
'name': 'TIFF',
'version': '6.0',
'extension': ['tif', 'tiff'],
'risk_level': 'MÍNIMO',
'vendor': 'Adobe (padrão aberto)',
'reason': 'Padrão de facto para preservação de imagens',
'migration_target': 'N/A'
},
{
'puid': 'fmt/199',
'name': 'MPEG-4',
'version': 'Part 14',
'extension': ['mp4'],
'risk_level': 'BAIXO',
'vendor': 'ISO/IEC Standard',
'reason': 'Padrão aberto amplamente suportado',
'migration_target': 'N/A'
},
{
'puid': 'fmt/134',
'name': 'WAV',
'version': 'PCM',
'extension': ['wav'],
'risk_level': 'MÍNIMO',
'vendor': 'Microsoft/IBM',
'reason': 'Formato não comprimido padrão',
'migration_target': 'FLAC para compressão sem perdas'
},
{
'puid': 'fmt/279',
'name': 'FLAC',
'version': '1.x',
'extension': ['flac'],
'risk_level': 'MÍNIMO',
'vendor': 'Xiph.Org (código aberto)',
'reason': 'Código aberto, compressão sem perdas',
'migration_target': 'N/A'
},
{
'puid': 'fmt/134',
'name': 'MP3',
'version': 'MPEG-1/2 Layer III',
'extension': ['mp3'],
'risk_level': 'BAIXO',
'vendor': 'ISO/IEC Standard',
'reason': 'Amplamente suportado, mas com perdas',
'migration_target': 'FLAC, WAV para preservação'
},
{
'puid': 'x-fmt/263',
'name': 'ZIP',
'version': '2.0',
'extension': ['zip'],
'risk_level': 'BAIXO',
'vendor': 'PKWARE',
'reason': 'Amplamente suportado',
'migration_target': 'TAR.GZ, 7Z para melhor compressão'
},
{
'puid': 'x-fmt/266',
'name': 'RAR',
'version': '4.x-5.x',
'extension': ['rar'],
'risk_level': 'MÉDIO',
'vendor': 'RARlab (proprietário)',
'reason': 'Formato proprietário',
'migration_target': 'ZIP, 7Z, TAR.GZ'
},
{
'puid': 'fmt/471',
'name': 'HTML',
'version': '5',
'extension': ['html', 'htm'],
'risk_level': 'MÍNIMO',
'vendor': 'W3C Standard',
'reason': 'Padrão web atual',
'migration_target': 'PDF/A para preservação'
},
{
'puid': 'fmt/817',
'name': 'EPUB',
'version': '3.x',
'extension': ['epub'],
'risk_level': 'BAIXO',
'vendor': 'IDPF/W3C Standard',
'reason': 'Padrão aberto para e-books',
'migration_target': 'PDF/A para preservação'
},
{
'puid': 'fmt/24',
'name': 'AutoCAD Drawing',
'version': 'DWG R14-2000',
'extension': ['dwg'],
'risk_level': 'MÉDIO',
'vendor': 'Autodesk (proprietário)',
'reason': 'Formato proprietário, versões antigas',
'migration_target': 'DWG atual, DXF, PDF/A'
},
{
'puid': 'fmt/64',
'name': 'AutoCAD Drawing Exchange',
'version': 'DXF',
'extension': ['dxf'],
'risk_level': 'BAIXO',
'vendor': 'Autodesk',
'reason': 'Formato de intercâmbio documentado',
'migration_target': 'PDF/A para preservação'
},
]
return formats
def classify_formats(self):
"""Classifica formatos por nível de risco"""
formats = self.load_pronom_database()
for fmt in formats:
risk_level = fmt['risk_level']
self.risk_categories[risk_level].append(fmt)
return self.risk_categories
def export_to_json(self, filename='pronom_obsolescence_list.json'):
"""Exporta lista para JSON"""
categories = self.classify_formats()
output = {
'metadata': {
'generated_date': datetime.now().isoformat(),
'source': 'PRONOM Registry',
'total_formats': sum(len(v) for v in categories.values())
},
'risk_categories': categories
}
with open(filename, 'w', encoding='utf-8') as f:
json.dump(output, f, indent=2, ensure_ascii=False)
print(f"Lista exportada para: {filename}")
return filename
def export_to_csv(self, filename='pronom_obsolescence_list.csv'):
"""Exporta lista para CSV"""
categories = self.classify_formats()
with open(filename, 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow([
'PUID', 'Nome', 'Versão', 'Extensões', 'Nível de Risco',
'Fornecedor', 'Razão', 'Formato de Migração'
])
for risk_level, formats in categories.items():
for fmt in formats:
writer.writerow([
fmt['puid'],
fmt['name'],
fmt['version'],
', '.join(fmt['extension']),
risk_level,
fmt['vendor'],
fmt['reason'],
fmt['migration_target']
])
print(f"Lista exportada para: {filename}")
return filename
def generate_markdown_report(self, filename='pronom_obsolescence_report.md'):
"""Gera relatório em Markdown"""
categories = self.classify_formats()
with open(filename, 'w', encoding='utf-8') as f:
f.write("# Lista de Formatos - Risco de Obsolescência\n\n")
f.write(f"**Data de Geração:** {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n\n")
f.write(f"**Fonte:** PRONOM Registry (The National Archives, UK)\n\n")
f.write("---\n\n")
risk_order = ['CRÍTICO', 'ALTO', 'MÉDIO', 'BAIXO', 'MÍNIMO']
for risk_level in risk_order:
formats = categories[risk_level]
f.write(f"## {risk_level} RISCO ({len(formats)} formatos)\n\n")
for fmt in formats:
f.write(f"### {fmt['name']} (v{fmt['version']})\n\n")
f.write(f"- **PUID:** {fmt['puid']}\n")
f.write(f"- **Extensões:** {', '.join(fmt['extension'])}\n")
f.write(f"- **Fornecedor:** {fmt['vendor']}\n")
f.write(f"- **Razão:** {fmt['reason']}\n")
f.write(f"- **Migração recomendada:** {fmt['migration_target']}\n\n")
f.write("---\n\n")
print(f"Relatório gerado: {filename}")
return filename
def get_statistics(self):
"""Retorna estatísticas sobre os formatos"""
categories = self.classify_formats()
stats = {
'total_formats': sum(len(v) for v in categories.values()),
'by_risk_level': {k: len(v) for k, v in categories.items()},
'critical_extensions': [],
'high_risk_extensions': []
}
for fmt in categories['CRÍTICO']:
stats['critical_extensions'].extend(fmt['extension'])
for fmt in categories['ALTO']:
stats['high_risk_extensions'].extend(fmt['extension'])
return stats
def main():
"""Função principal"""
checker = PRONOMObsolescenceChecker()
print("=== Gerador de Lista de Obsolescência PRONOM ===\n")
print("Gerando arquivos de saída...\n")
checker.export_to_json()
checker.export_to_csv()
checker.generate_markdown_report()
stats = checker.get_statistics()
print("\n=== ESTATÍSTICAS ===")
print(f"Total de formatos catalogados: {stats['total_formats']}")
print("\nDistribuição por nível de risco:")
for level, count in stats['by_risk_level'].items():
print(f" {level}: {count} formatos")
print(f"\nExtensões CRÍTICAS: {', '.join(set(stats['critical_extensions']))}")
print(f"\nExtensões ALTO RISCO: {', '.join(set(stats['high_risk_extensions']))}")
print("\n✓ Arquivos gerados com sucesso!")
if __name__ == "__main__":
main()2. Script de Integração com DROID
#!/usr/bin/env python3
# check_obsolescence_in_droid.py
import json
import csv
import pandas as pd
from collections import defaultdict
def check_obsolescence_in_collection(droid_csv, obsolescence_json):
"""
Verifica quais formatos obsoletos existem na coleção
"""
# Carregar lista de obsolescência
with open(obsolescence_json, 'r') as f:
obsolescence_data = json.load(f)
# Criar dicionário de extensões por risco
extension_risk = {}
for risk_level, formats in obsolescence_data['risk_categories'].items():
for fmt in formats:
for ext in fmt['extension']:
extension_risk[ext.lower()] = {
'risk_level': risk_level,
'format_name': fmt['name'],
'migration_target': fmt['migration_target'],
'reason': fmt['reason']
}
# Carregar relatório DROID
df = pd.read_csv(droid_csv)
# Analisar formatos encontrados
results = {
'CRÍTICO': defaultdict(int),
'ALTO': defaultdict(int),
'MÉDIO': defaultdict(int),
'BAIXO': defaultdict(int),
'MÍNIMO': defaultdict(int),
'NÃO_CLASSIFICADO': defaultdict(int)
}
total_files = len(df)
files_at_risk = 0
for idx, row in df.iterrows():
ext = str(row.get('EXT', '')).lower()
if ext in extension_risk:
risk_info = extension_risk[ext]
risk_level = risk_info['risk_level']
results[risk_level][ext] += 1
if risk_level in ['CRÍTICO', 'ALTO', 'MÉDIO']:
files_at_risk += 1
else:
results['NÃO_CLASSIFICADO'][ext] += 1
# Gerar relatório
report = {
'summary': {
'total_files': total_files,
'files_at_risk': files_at_risk,
'risk_percentage': (files_at_risk / total_files * 100) if total_files > 0 else 0
},
'by_risk_level': {}
}
for risk_level, extensions in results.items():
if extensions:
report['by_risk_level'][risk_level] = {
'count': sum(extensions.values()),
'extensions': dict(extensions)
}
# Salvar relatório
output_file = 'obsolescence_analysis_report.json'
with open(output_file, 'w') as f:
json.dump(report, f, indent=2)
# Gerar relatório detalhado
generate_detailed_report(df, extension_risk, 'obsolescence_detailed_report.csv')
print(f"\n=== ANÁLISE DE OBSOLESCÊNCIA ===")
print(f"Total de arquivos: {total_files}")
print(f"Arquivos em risco: {files_at_risk} ({report['summary']['risk_percentage']:.2f}%)")
print(f"\nDistribuição por nível de risco:")
for risk_level in ['CRÍTICO', 'ALTO', 'MÉDIO', 'BAIXO', 'MÍNIMO']:
if risk_level in report['by_risk_level']:
count = report['by_risk_level'][risk_level]['count']
print(f" {risk_level}: {count} arquivos")
print(f"\n✓ Relatórios salvos:")
print(f" - {output_file}")
print(f" - obsolescence_detailed_report.csv")
return report
def generate_detailed_report(df, extension_risk, output_file):
"""Gera relatório detalhado com todos os arquivos em risco"""
with open(output_file, 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow([
'Arquivo', 'Extensão', 'Nível de Risco', 'Formato',
'Tamanho (bytes)', 'Razão', 'Migração Recomendada'
])
for idx, row in df.iterrows():
ext = str(row.get('EXT', '')).lower()
filepath = row.get('FILE_PATH', row.get('URI', 'N/A'))
filesize = row.get('SIZE', 0)
if ext in extension_risk:
risk_info = extension_risk[ext]
# Apenas incluir arquivos de risco médio ou superior
if risk_info['risk_level'] in ['CRÍTICO', 'ALTO', 'MÉDIO']:
writer.writerow([
filepath,
ext,
risk_info['risk_level'],
risk_info['format_name'],
filesize,
risk_info['reason'],
risk_info['migration_target']
])
if __name__ == "__main__":
import sys
if len(sys.argv) < 2:
print("Uso: python check_obsolescence_in_droid.py <droid_report.csv> [obsolescence_list.json]")
sys.exit(1)
droid_csv = sys.argv[1]
obsolescence_json = sys.argv[2] if len(sys.argv) > 2 else 'pronom_obsolescence_list.json'
check_obsolescence_in_collection(droid_csv, obsolescence_json)3. Uso Prático
#!/bin/bash
# run_obsolescence_check.sh
# 1. Gerar lista de formatos obsoletos do PRONOM
echo "Gerando lista de formatos obsoletos..."
python3 pronom_obsolescence_checker.py
# 2. Executar varredura DROID
echo "Executando varredura DROID..."
./scan_droid.sh
# 3. Verificar obsolescência na coleção
echo "Analisando obsolescência na coleção..."
LATEST_DROID=$(ls -t /OPT/droid/reports/report_*.csv | head -1)
python3 check_obsolescence_in_droid.py "$LATEST_DROID" pronom_obsolescence_list.json
echo "Análise completa!"4. Saídas Geradas
Os scripts geram:
- pronom_obsolescence_list.json - Lista completa em JSON
- pronom_obsolescence_list.csv - Lista em CSV para Excel
- pronom_obsolescence_report.md - Relatório legível em Markdown
- obsolescence_analysis_report.json - Análise da sua coleção
- obsolescence_detailed_report.csv - Lista de arquivos em risco
Esses scripts fornecem uma base sólida baseada no PRONOM para monitorar obsolescência tecnológica no seu acervo digital.
Lista de Formatos Obsoletos e em Risco usando o Siegfried
Siegfried é uma alternativa ao DROID, mais moderna e sem dependência de Java:
# Instalar Siegfried
wget https://github.com/richardlehane/siegfried/releases/download/v1.11.2/siegfried_1-11-2_linux64.zip
unzip siegfried_1-11-2_linux64.zip
sudo cp sf /usr/local/bin/
sudo cp roy /usr/local/bin/
# Atualizar assinaturas PRONOM
sf -update
# Executar varredura
sf -csv /var/archivematica/sharedDirectory/transferSource/dataverse/dataverse/ > report.csvNo diretório /opt/scripts-preservacao/checar-obsolescencia/scripts do servidor node01-archivematica foi criado o script abaixo:
run_cron_obsolescence.sh (monta o environment python e executa o script run_obsolescence_check_siegfried.sh)
\- setup_python_environment.sh (monta o ambiente python)
\-run_obsolescence_check_siegfried.sh
|- email_config.sh (carrega as variáveis para funcionar o envio de mensagem)
|- repositories_config.sh (carrega a variável REPOSITORIES com a relação de pastas que serão monitoradas)
|- pronom_obsolescence_checker.py (Gera lista de formatos obsoletos (PRONOM)
|- scan_siegfried_multi.sh (Executando varredura Siegfried)
|- consolidate_siegfried_reports.py (Executar consolidação e salvar toda a saída)
|- check_obsolescence_in_droid.py (Analisar obsolescência)
|- generate_comprehensive_report.py (Gerar HTML abrangente)
|- send_email_report.py (Enviar email)Caso queira alterar as credenciais do e-mail, basta editar o email_config.sh
Caso queira alterar (adicionar/remover) diretório, basta editar o repositories_config.sh
Foi adicionado no crontab para que fosse executado todo dia 07 de cada mês
0 2 7 * * /opt/scripts-preservacao/checar-obsolescencia/scripts/run_cron_obsolescence.sh >> /opt/scripts-preservacao/checar-obsolescencia/logs/cron_$(date +\%Y\%m).log 2>&1PREPARANDO O AMBIENTE PARA USAR O DROID, SIEGFRIED E JHOVE
- Ambiente Virtual com venv (Recomendado - Python 3.3+)
Criar ambiente virtual
# Navegar para o diretório do projeto
cd /opt/scripts-preservacao
# Criar ambiente virtual
python3 -m venv venv
Ativar ambiente virtual
# No Linux/Mac
source venv/bin/activate
# Você verá (venv) no início do prompt quando ativado
(venv) [root@node01-archivematica scripts-preservacao]#Desativar ambiente virtual
deactivate2. Instalar Dependências no Ambiente Virtual
# Após ativar o ambiente
pip install pandas
pip install matplotlib
pip install requests
# Ou instalar de uma vez
pip install pandas matplotlib requests openpyxl
# Ou criar um arquivo requirements.txt
cat > requirements.txt <<EOF
pandas>=2.0.0
matplotlib>=3.7.0
requests>=2.31.0
openpyxl>=3.1.0
lxml>=4.9.0
EOF
# Instalar do requirements.txt
pip install -r requirements.txt3. Script Completo de Setup
#!/bin/bash
# setup_python_environment.sh
set -e
PROJECT_DIR="/opt/scripts-preservacao"
VENV_NAME="venv"
echo "=== Configurando Ambiente Python ==="
# Verificar se Python 3 está instalado
if ! command -v python3 &> /dev/null; then
echo "Python 3 não encontrado. Instalando..."
sudo yum install -y python3 python3-pip
fi
# Criar diretório do projeto se não existir
mkdir -p "$PROJECT_DIR"
cd "$PROJECT_DIR"
# Criar ambiente virtual
echo "Criando ambiente virtual..."
python3 -m venv "$VENV_NAME"
# Ativar ambiente virtual
source "$VENV_NAME/bin/activate"
# Atualizar pip
echo "Atualizando pip..."
pip install --upgrade pip
# Criar requirements.txt
echo "Criando requirements.txt..."
cat > requirements.txt <<EOF
# Análise de dados
pandas>=2.0.0
numpy>=1.24.0
# Visualização
matplotlib>=3.7.0
seaborn>=0.12.0
# Processamento de arquivos
openpyxl>=3.1.0
lxml>=4.9.0
# Requisições HTTP
requests>=2.31.0
# Utilitários
python-dateutil>=2.8.0
EOF
# Instalar dependências
echo "Instalando dependências..."
pip install -r requirements.txt
# Verificar instalação
echo ""
echo "=== Pacotes Instalados ==="
pip list
echo ""
echo "=== Ambiente Configurado com Sucesso! ==="
echo "Para ativar o ambiente no futuro, execute:"
echo " cd $PROJECT_DIR"
echo " source $VENV_NAME/bin/activate"Executar o script de setup
chmod +x setup_python_environment.sh
./setup_python_environment.sh4. Estrutura de Projeto Recomendada
/opt/scripts-preservacao/
├── venv/ # Ambiente virtual (não versionar)
├── requirements.txt # Dependências do projeto
├── README.md # Documentação
├── scripts/
│ ├── pronom_obsolescence_checker.py
│ ├── check_obsolescence_in_droid.py
│ ├── analyze_droid_report.py
│ └── analyze_jhove_report.py
├── data/
│ ├── input/ # Dados de entrada
│ └── output/ # Relatórios gerados
└── config/
└── settings.py # Configurações5. Criar Script de Ativação Rápida
# Criar alias no .bashrc para ativação rápida
cat >> ~/.bashrc <<'EOF'
# Ativar ambiente Python de preservação
alias preserve='cd /opt/scripts-preservacao && source venv/bin/activate'
EOF
source ~/.bashrc
# Agora você pode simplesmente digitar:
preserve
MONITORANDO A INTEGRIDADE DOS ARQUIVOS PRESERVADOS
O script file_integrity_monitor_multi_dir.py tem como objetivo monitorar a integridade de um ou mais diretórios gerando como resultado um arquivo txt e um html em formato de relatório e envia via e-mail.
#!/usr/bin/env python3
"""
File Integrity Monitor
Sistema de monitoramento de integridade de arquivos com suporte a múltiplos diretórios
"""
import os
import sys
import json
import hashlib
import subprocess
from datetime import datetime
from pathlib import Path
import argparse
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
class FileIntegrityMonitor:
def __init__(self, target_dirs, database_dir=".file_integrity"):
# Suporta lista de diretórios
if isinstance(target_dirs, str):
target_dirs = [target_dirs]
self.target_dirs = [Path(d).resolve() for d in target_dirs]
self.database_dir = Path(database_dir)
self.database_dir.mkdir(exist_ok=True)
self.current_scan_file = self.database_dir / "current_scan.json"
self.previous_scan_file = self.database_dir / "previous_scan.json"
self.history_file = self.database_dir / "scan_history.json"
self.config_file = self.database_dir / "config.json"
self.email_config_file = self.database_dir / "email_config.json"
def calculate_hash(self, filepath, algorithm='sha256'):
"""Calcula hash de um arquivo"""
hash_obj = hashlib.new(algorithm)
try:
with open(filepath, 'rb') as f:
for chunk in iter(lambda: f.read(4096), b''):
hash_obj.update(chunk)
return hash_obj.hexdigest()
except Exception as e:
return f"ERROR: {str(e)}"
def scan_directory(self):
"""Escaneia todos os diretórios configurados"""
print(f"Escaneando {len(self.target_dirs)} diretório(s)...")
scan_data = {
'timestamp': datetime.now().isoformat(),
'target_dirs': [str(d) for d in self.target_dirs],
'files': {}
}
total_files = 0
for target_dir in self.target_dirs:
if not target_dir.exists():
print(f"⚠️ Diretório não encontrado: {target_dir}")
continue
print(f"\n📁 Escaneando: {target_dir}")
dir_files = 0
for root, dirs, files in os.walk(target_dir):
# Ignora o diretório de database
if self.database_dir.name in dirs:
dirs.remove(self.database_dir.name)
for filename in files:
filepath = Path(root) / filename
# Usa caminho relativo ao diretório base
try:
relative_path = filepath.relative_to(target_dir)
# Prefixo com o nome do diretório base para evitar conflitos
key = f"{target_dir.name}/{relative_path}"
except ValueError:
# Se não conseguir fazer relativo, usa caminho absoluto
key = str(filepath)
try:
file_stat = filepath.stat()
file_hash = self.calculate_hash(filepath)
scan_data['files'][key] = {
'hash': file_hash,
'size': file_stat.st_size,
'modified': datetime.fromtimestamp(file_stat.st_mtime).isoformat(),
'full_path': str(filepath),
'base_dir': str(target_dir)
}
dir_files += 1
total_files += 1
if dir_files % 100 == 0:
print(f" Processados {dir_files} arquivos...")
except Exception as e:
print(f" Erro ao processar {filepath}: {e}")
print(f" ✓ {dir_files} arquivos processados")
print(f"\n✓ Scan completo: {total_files} arquivos no total")
return scan_data
def save_scan(self, scan_data):
"""Salva dados do scan"""
# Move scan atual para anterior
if self.current_scan_file.exists():
self.current_scan_file.rename(self.previous_scan_file)
# Salva novo scan
with open(self.current_scan_file, 'w') as f:
json.dump(scan_data, f, indent=2)
# Adiciona ao histórico
self.add_to_history(scan_data)
def add_to_history(self, scan_data):
"""Adiciona scan ao histórico"""
history = []
if self.history_file.exists():
with open(self.history_file, 'r') as f:
history = json.load(f)
history_entry = {
'timestamp': scan_data['timestamp'],
'total_files': len(scan_data['files']),
'total_size': sum(f['size'] for f in scan_data['files'].values()),
'directories': scan_data['target_dirs']
}
history.append(history_entry)
# Mantém apenas últimos 50 registros
history = history[-50:]
with open(self.history_file, 'w') as f:
json.dump(history, f, indent=2)
def compare_scans(self):
"""Compara scan atual com anterior"""
if not self.previous_scan_file.exists():
return None
with open(self.current_scan_file, 'r') as f:
current = json.load(f)
with open(self.previous_scan_file, 'r') as f:
previous = json.load(f)
current_files = set(current['files'].keys())
previous_files = set(previous['files'].keys())
# Arquivos novos
new_files = current_files - previous_files
# Arquivos removidos
removed_files = previous_files - current_files
# Arquivos modificados e corrompidos
modified_files = []
corrupted_files = []
intact_files = []
common_files = current_files & previous_files
for filepath in common_files:
current_hash = current['files'][filepath]['hash']
previous_hash = previous['files'][filepath]['hash']
if current_hash.startswith('ERROR'):
corrupted_files.append(filepath)
elif current_hash != previous_hash:
modified_files.append(filepath)
else:
intact_files.append(filepath)
# Agrupa por diretório base
def group_by_dir(file_list):
by_dir = {}
for f in file_list:
base_dir = current['files'].get(f, {}).get('base_dir') or \
previous['files'].get(f, {}).get('base_dir', 'unknown')
if base_dir not in by_dir:
by_dir[base_dir] = []
by_dir[base_dir].append(f)
return by_dir
return {
'current_timestamp': current['timestamp'],
'previous_timestamp': previous['timestamp'],
'total_current': len(current_files),
'total_previous': len(previous_files),
'new_files': list(new_files),
'removed_files': list(removed_files),
'modified_files': modified_files,
'corrupted_files': corrupted_files,
'intact_files': intact_files,
'new_by_dir': group_by_dir(new_files),
'modified_by_dir': group_by_dir(modified_files),
'corrupted_by_dir': group_by_dir(corrupted_files),
'target_dirs': current['target_dirs']
}
def generate_report(self, comparison):
"""Gera relatório de integridade"""
if comparison is None:
print("\n" + "="*60)
print("PRIMEIRO SCAN - Baseline criado")
print("="*60)
print(f"Diretórios monitorados: {len(self.target_dirs)}")
for d in self.target_dirs:
print(f" • {d}")
return
total = comparison['total_current']
intact = len(comparison['intact_files'])
modified = len(comparison['modified_files'])
corrupted = len(comparison['corrupted_files'])
new = len(comparison['new_files'])
removed = len(comparison['removed_files'])
# Calcula porcentagens
intact_pct = (intact / total * 100) if total > 0 else 0
modified_pct = (modified / total * 100) if total > 0 else 0
corrupted_pct = (corrupted / total * 100) if total > 0 else 0
new_pct = (new / total * 100) if total > 0 else 0
print("\n" + "="*60)
print("RELATÓRIO DE INTEGRIDADE DE ARQUIVOS")
print("="*60)
print(f"Scan atual: {comparison['current_timestamp']}")
print(f"Scan anterior: {comparison['previous_timestamp']}")
print(f"\nDiretórios monitorados: {len(comparison['target_dirs'])}")
for d in comparison['target_dirs']:
print(f" • {d}")
print("\n" + "-"*60)
print("ESTATÍSTICAS GERAIS")
print("-"*60)
print(f"Total de arquivos atuais: {total}")
print(f"Total de arquivos anteriores: {comparison['total_previous']}")
print("\n" + "-"*60)
print("GRAU DE INTEGRIDADE")
print("-"*60)
print(f"✓ Arquivos íntegros: {intact:4d} ({intact_pct:6.2f}%)")
print(f"≠ Arquivos modificados: {modified:4d} ({modified_pct:6.2f}%)")
print(f"✗ Arquivos corrompidos: {corrupted:4d} ({corrupted_pct:6.2f}%)")
print(f"+ Arquivos novos: {new:4d} ({new_pct:6.2f}%)")
print(f"- Arquivos removidos: {removed:4d}")
# Integridade geral
if intact + modified + corrupted > 0:
integrity_score = (intact / (intact + modified + corrupted)) * 100
print(f"\n{'='*60}")
print(f"INTEGRIDADE GERAL: {integrity_score:.2f}%")
print(f"{'='*60}")
# Detalhes por diretório
if corrupted > 0:
print("\n" + "-"*60)
print("ARQUIVOS CORROMPIDOS POR DIRETÓRIO")
print("-"*60)
for base_dir, files in comparison['corrupted_by_dir'].items():
print(f"\n 📁 {base_dir} ({len(files)} arquivos)")
for f in files[:10]:
print(f" ✗ {f}")
if len(files) > 10:
print(f" ... e mais {len(files) - 10} arquivos")
if modified > 0:
print("\n" + "-"*60)
print("ARQUIVOS MODIFICADOS POR DIRETÓRIO")
print("-"*60)
for base_dir, files in comparison['modified_by_dir'].items():
print(f"\n 📁 {base_dir} ({len(files)} arquivos)")
for f in files[:10]:
print(f" ≠ {f}")
if len(files) > 10:
print(f" ... e mais {len(files) - 10} arquivos")
# Salva relatórios
self.save_report_to_file(comparison)
html_file = self.save_html_report(comparison)
return html_file
def save_report_to_file(self, comparison):
"""Salva relatório em arquivo texto"""
report_file = self.database_dir / f"report_{datetime.now().strftime('%Y%m%d_%H%M%S')}.txt"
with open(report_file, 'w') as f:
f.write("="*60 + "\n")
f.write("RELATÓRIO DE INTEGRIDADE DE ARQUIVOS\n")
f.write("="*60 + "\n")
f.write(f"Scan atual: {comparison['current_timestamp']}\n")
f.write(f"Scan anterior: {comparison['previous_timestamp']}\n\n")
f.write(f"Diretórios monitorados: {len(comparison['target_dirs'])}\n")
for d in comparison['target_dirs']:
f.write(f" • {d}\n")
total = comparison['total_current']
intact = len(comparison['intact_files'])
modified = len(comparison['modified_files'])
corrupted = len(comparison['corrupted_files'])
new = len(comparison['new_files'])
removed = len(comparison['removed_files'])
intact_pct = (intact / total * 100) if total > 0 else 0
modified_pct = (modified / total * 100) if total > 0 else 0
corrupted_pct = (corrupted / total * 100) if total > 0 else 0
f.write("\n" + "-"*60 + "\n")
f.write("GRAU DE INTEGRIDADE\n")
f.write("-"*60 + "\n")
f.write(f"Arquivos íntegros: {intact} ({intact_pct:.2f}%)\n")
f.write(f"Arquivos modificados: {modified} ({modified_pct:.2f}%)\n")
f.write(f"Arquivos corrompidos: {corrupted} ({corrupted_pct:.2f}%)\n")
f.write(f"Arquivos novos: {new}\n")
f.write(f"Arquivos removidos: {removed}\n\n")
if intact + modified + corrupted > 0:
integrity_score = (intact / (intact + modified + corrupted)) * 100
f.write("="*60 + "\n")
f.write(f"INTEGRIDADE GERAL: {integrity_score:.2f}%\n")
f.write("="*60 + "\n\n")
# Lista completa de arquivos com problemas por diretório
if corrupted:
f.write("\nARQUIVOS CORROMPIDOS POR DIRETÓRIO:\n")
for base_dir, files in comparison['corrupted_by_dir'].items():
f.write(f"\n{base_dir}:\n")
for file in files:
f.write(f" {file}\n")
if modified:
f.write("\nARQUIVOS MODIFICADOS POR DIRETÓRIO:\n")
for base_dir, files in comparison['modified_by_dir'].items():
f.write(f"\n{base_dir}:\n")
for file in files:
f.write(f" {file}\n")
if new:
f.write("\nARQUIVOS NOVOS POR DIRETÓRIO:\n")
for base_dir, files in comparison['new_by_dir'].items():
f.write(f"\n{base_dir}:\n")
for file in files:
f.write(f" {file}\n")
print(f"\nRelatório TXT salvo em: {report_file}")
def save_html_report(self, comparison):
"""Gera relatório HTML"""
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
report_file = self.database_dir / f"report_{timestamp}.html"
total = comparison['total_current']
intact = len(comparison['intact_files'])
modified = len(comparison['modified_files'])
corrupted = len(comparison['corrupted_files'])
new = len(comparison['new_files'])
removed = len(comparison['removed_files'])
intact_pct = (intact / total * 100) if total > 0 else 0
modified_pct = (modified / total * 100) if total > 0 else 0
corrupted_pct = (corrupted / total * 100) if total > 0 else 0
new_pct = (new / total * 100) if total > 0 else 0
integrity_score = (intact / (intact + modified + corrupted)) * 100 if (intact + modified + corrupted) > 0 else 0
# Determina cor e status
if integrity_score >= 99:
status_color = "#28a745"
status_text = "EXCELENTE"
elif integrity_score >= 95:
status_color = "#5bc0de"
status_text = "BOM"
elif integrity_score >= 90:
status_color = "#ffc107"
status_text = "ATENÇÃO"
else:
status_color = "#dc3545"
status_text = "CRÍTICO"
# Lista de diretórios
dirs_html = ""
for d in comparison['target_dirs']:
dirs_html += f"<li>{d}</li>"
html_content = f"""
<!DOCTYPE html>
<html lang="pt-BR">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Relatório de Integridade - {timestamp}</title>
<style>
* {{ margin: 0; padding: 0; box-sizing: border-box; }}
body {{ font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif; background: linear-gradient(135deg, #667eea 0%, #764ba2 100%); padding: 20px; color: #333; }}
.container {{ max-width: 1200px; margin: 0 auto; background: white; border-radius: 10px; box-shadow: 0 10px 40px rgba(0,0,0,0.2); overflow: hidden; }}
.header {{ background: linear-gradient(135deg, #667eea 0%, #764ba2 100%); color: white; padding: 40px; text-align: center; }}
.header h1 {{ font-size: 2.5em; margin-bottom: 10px; }}
.header .subtitle {{ opacity: 0.9; font-size: 1.1em; }}
.integrity-score {{ background: {status_color}; color: white; padding: 40px; text-align: center; font-size: 3em; font-weight: bold; }}
.integrity-score .label {{ font-size: 0.4em; opacity: 0.9; display: block; margin-bottom: 10px; }}
.integrity-score .status {{ font-size: 0.5em; margin-top: 10px; }}
.content {{ padding: 40px; }}
.directories {{ background: #f8f9fa; padding: 20px; border-radius: 8px; margin-bottom: 30px; }}
.directories h3 {{ color: #667eea; margin-bottom: 15px; }}
.directories ul {{ list-style: none; }}
.directories li {{ padding: 8px; margin: 5px 0; background: white; border-radius: 4px; border-left: 3px solid #667eea; }}
.stats-grid {{ display: grid; grid-template-columns: repeat(auto-fit, minmax(250px, 1fr)); gap: 20px; margin-bottom: 40px; }}
.stat-card {{ background: white; padding: 25px; border-radius: 8px; border: 2px solid #e9ecef; transition: transform 0.2s; }}
.stat-card:hover {{ transform: translateY(-5px); box-shadow: 0 5px 20px rgba(0,0,0,0.1); }}
.stat-card.intact {{ border-left: 4px solid #28a745; }}
.stat-card.modified {{ border-left: 4px solid #ffc107; }}
.stat-card.corrupted {{ border-left: 4px solid #dc3545; }}
.stat-card .number {{ font-size: 2.5em; font-weight: bold; margin: 10px 0; }}
.stat-card .percentage {{ color: #666; font-size: 1.2em; }}
.file-list {{ background: #f8f9fa; border-radius: 8px; padding: 20px; margin-top: 20px; }}
.file-list h3 {{ color: #333; margin-bottom: 15px; padding-bottom: 10px; border-bottom: 2px solid #dee2e6; }}
.file-list .dir-section {{ margin: 20px 0; }}
.file-list .dir-title {{ font-weight: bold; color: #667eea; margin-bottom: 10px; }}
.file-list ul {{ list-style: none; max-height: 300px; overflow-y: auto; }}
.file-list li {{ padding: 8px; margin: 5px 0; background: white; border-radius: 4px; word-break: break-all; }}
.file-list.corrupted li {{ border-left: 3px solid #dc3545; }}
.file-list.modified li {{ border-left: 3px solid #ffc107; }}
.timestamp {{ background: #e9ecef; padding: 15px; border-radius: 5px; margin-bottom: 20px; }}
.timestamp strong {{ color: #667eea; }}
.footer {{ background: #f8f9fa; padding: 20px; text-align: center; color: #666; font-size: 0.9em; }}
</style>
</head>
<body>
<div class="container">
<div class="header">
<h1>📊 Relatório de Integridade de Arquivos</h1>
<div class="subtitle">Monitoramento de Múltiplos Diretórios</div>
</div>
<div class="integrity-score">
<span class="label">INTEGRIDADE GERAL</span>
{integrity_score:.2f}%
<div class="status">{status_text}</div>
</div>
<div class="content">
<div class="timestamp">
<strong>Scan Atual:</strong> {comparison['current_timestamp']}<br>
<strong>Scan Anterior:</strong> {comparison['previous_timestamp']}
</div>
<div class="directories">
<h3>📁 Diretórios Monitorados ({len(comparison['target_dirs'])})</h3>
<ul>{dirs_html}</ul>
</div>
<h2 style="margin: 30px 0 20px 0; color: #667eea;">Estatísticas Globais</h2>
<div class="stats-grid">
<div class="stat-card intact">
<div style="font-size:2em">✓</div>
<div class="number">{intact}</div>
<div class="percentage">{intact_pct:.2f}%</div>
<div>Arquivos Íntegros</div>
</div>
<div class="stat-card modified">
<div style="font-size:2em">≠</div>
<div class="number">{modified}</div>
<div class="percentage">{modified_pct:.2f}%</div>
<div>Arquivos Modificados</div>
</div>
<div class="stat-card corrupted">
<div style="font-size:2em">✗</div>
<div class="number">{corrupted}</div>
<div class="percentage">{corrupted_pct:.2f}%</div>
<div>Arquivos Corrompidos</div>
</div>
</div>
"""
# Adiciona seções por diretório
if corrupted > 0:
html_content += '<div class="file-list corrupted"><h3>⚠️ Arquivos Corrompidos</h3>'
for base_dir, files in comparison['corrupted_by_dir'].items():
html_content += f'<div class="dir-section"><div class="dir-title">📁 {base_dir} ({len(files)})</div><ul>'
for f in files[:50]:
html_content += f"<li>✗ {f}</li>"
if len(files) > 50:
html_content += f"<li><strong>... e mais {len(files) - 50} arquivos</strong></li>"
html_content += '</ul></div>'
html_content += '</div>'
if modified > 0:
html_content += '<div class="file-list modified"><h3>📝 Arquivos Modificados</h3>'
for base_dir, files in comparison['modified_by_dir'].items():
html_content += f'<div class="dir-section"><div class="dir-title">📁 {base_dir} ({len(files)})</div><ul>'
for f in files[:50]:
html_content += f"<li>≠ {f}</li>"
if len(files) > 50:
html_content += f"<li><strong>... e mais {len(files) - 50} arquivos</strong></li>"
html_content += '</ul></div>'
html_content += '</div>'
html_content += f"""
</div>
<div class="footer">
Gerado em {datetime.now().strftime('%d/%m/%Y às %H:%M:%S')}<br>
File Integrity Monitor - Monitoramento de Múltiplos Diretórios
</div>
</div>
</body>
</html>"""
with open(report_file, 'w', encoding='utf-8') as f:
f.write(html_content)
print(f"Relatório HTML salvo em: {report_file}")
return report_file
def send_email_notification(self, comparison, html_file, config):
"""Envia notificação por email"""
try:
total = comparison['total_current']
intact = len(comparison['intact_files'])
modified = len(comparison['modified_files'])
corrupted = len(comparison['corrupted_files'])
new = len(comparison['new_files'])
removed = len(comparison['removed_files'])
# Calcula porcentagens
intact_pct = (intact / total * 100) if total > 0 else 0
modified_pct = (modified / total * 100) if total > 0 else 0
corrupted_pct = (corrupted / total * 100) if total > 0 else 0
integrity_score = (intact / (intact + modified + corrupted)) * 100 if (intact + modified + corrupted) > 0 else 0
if corrupted > 0 or integrity_score < 90:
priority = "ALTA"
elif integrity_score < 95:
priority = "MÉDIA"
else:
priority = "NORMAL"
msg = MIMEMultipart('alternative')
msg['Subject'] = f"[{priority}] Integridade {len(comparison['target_dirs'])} Diretórios - {integrity_score:.1f}%"
msg['From'] = config['from_email']
msg['To'] = config['to_email']
dirs_text = "\n".join(f" • {d}" for d in comparison['target_dirs'])
text = f"""
Relatório de Integridade - Múltiplos Diretórios
===============================================
Integridade Geral: {integrity_score:.2f}%
Prioridade: {priority}
Diretórios Monitorados ({len(comparison['target_dirs'])}):
{dirs_text}
Scan atual: {comparison['current_timestamp']}
Estatísticas:
- Arquivos íntegros: {intact} ({intact_pct:.1f}%)
- Arquivos modificados: {modified} ({modified_pct:.1f}%)
- Arquivos corrompidos: {corrupted} ({corrupted_pct:.1f}%)
- Arquivos novos: {new}
- Arquivos removidos: {removed}
Relatório HTML completo em anexo.
"""
with open(html_file, 'r', encoding='utf-8') as f:
html = f.read()
msg.attach(MIMEText(text, 'plain'))
msg.attach(MIMEText(html, 'html'))
with smtplib.SMTP(config['smtp_server'], config['smtp_port']) as server:
if config.get('use_tls', True):
server.starttls()
if config.get('smtp_user') and config.get('smtp_password'):
server.login(config['smtp_user'], config['smtp_password'])
server.send_message(msg)
print(f"\n✓ Email enviado com sucesso para {config['to_email']}")
return True
except Exception as e:
print(f"\n✗ Erro ao enviar email: {e}")
return False
def save_config(self, directories):
"""Salva configuração de diretórios"""
config = {
'directories': [str(d) for d in directories],
'last_updated': datetime.now().isoformat()
}
with open(self.config_file, 'w') as f:
json.dump(config, f, indent=2)
def load_config(self):
"""Carrega configuração"""
if not self.config_file.exists():
return None
with open(self.config_file, 'r') as f:
return json.load(f)
def save_email_config(self, smtp_server, smtp_port, from_email, to_email,
smtp_user=None, smtp_password=None, use_tls=True):
"""Salva configuração de email"""
config = {
'smtp_server': smtp_server,
'smtp_port': smtp_port,
'from_email': from_email,
'to_email': to_email,
'smtp_user': smtp_user,
'smtp_password': smtp_password,
'use_tls': use_tls
}
with open(self.email_config_file, 'w') as f:
json.dump(config, f, indent=2)
print(f"Configuração de email salva em: {self.email_config_file}")
def load_email_config(self):
"""Carrega configuração de email"""
if not self.email_config_file.exists():
return None
with open(self.email_config_file, 'r') as f:
return json.load(f)
def main():
parser = argparse.ArgumentParser(
description='File Integrity Monitor - Suporta múltiplos diretórios',
formatter_class=argparse.RawDescriptionHelpFormatter,
epilog="""
Exemplos:
%(prog)s /dados # Um diretório
%(prog)s /dados /backup /www --send-email # Múltiplos diretórios
%(prog)s --add-dir /novo/diretorio # Adiciona diretório
%(prog)s --list-dirs # Lista diretórios configurados
%(prog)s --config-email # Configura email
"""
)
parser.add_argument('directories', nargs='*', help='Diretórios a monitorar')
parser.add_argument('--database', default='.file_integrity',
help='Diretório para dados (padrão: .file_integrity)')
parser.add_argument('--scan-only', action='store_true',
help='Apenas escaneia, não gera relatório')
parser.add_argument('--send-email', action='store_true',
help='Envia relatório por email')
parser.add_argument('--config-email', action='store_true',
help='Configura email')
parser.add_argument('--add-dir', metavar='DIR',
help='Adiciona diretório à configuração')
parser.add_argument('--remove-dir', metavar='DIR',
help='Remove diretório da configuração')
parser.add_argument('--list-dirs', action='store_true',
help='Lista diretórios configurados')
parser.add_argument('--use-config', action='store_true',
help='Usa diretórios da configuração')
args = parser.parse_args()
# Modo configuração de email
if args.config_email:
print("\n=== Configuração de Email ===\n")
smtp_server = input("Servidor SMTP (ex: smtp.gmail.com): ")
smtp_port = int(input("Porta SMTP (ex: 587): "))
from_email = input("Email remetente: ")
to_email = input("Email destinatário: ")
smtp_user = input("Usuário SMTP (ou Enter): ") or None
smtp_password = input("Senha SMTP (ou Enter): ") or None
use_tls = input("Usar TLS? (s/n): ").lower() != 'n'
monitor = FileIntegrityMonitor(["/tmp"], args.database)
monitor.save_email_config(smtp_server, smtp_port, from_email, to_email,
smtp_user, smtp_password, use_tls)
print("\n✓ Configuração salva!")
return
# Inicializa monitor temporário para operações de config
temp_monitor = FileIntegrityMonitor(["/tmp"], args.database)
# Lista diretórios
if args.list_dirs:
config = temp_monitor.load_config()
if config and config.get('directories'):
print("\nDiretórios configurados:")
for i, d in enumerate(config['directories'], 1):
print(f" {i}. {d}")
else:
print("\nNenhum diretório configurado ainda.")
return
# Adiciona diretório
if args.add_dir:
if not os.path.isdir(args.add_dir):
print(f"Erro: {args.add_dir} não é um diretório válido")
sys.exit(1)
config = temp_monitor.load_config() or {'directories': []}
if args.add_dir not in config['directories']:
config['directories'].append(args.add_dir)
temp_monitor.save_config(config['directories'])
print(f"✓ Diretório adicionado: {args.add_dir}")
else:
print(f"⚠️ Diretório já configurado: {args.add_dir}")
return
# Remove diretório
if args.remove_dir:
config = temp_monitor.load_config()
if config and args.remove_dir in config['directories']:
config['directories'].remove(args.remove_dir)
temp_monitor.save_config(config['directories'])
print(f"✓ Diretório removido: {args.remove_dir}")
else:
print(f"⚠️ Diretório não encontrado na configuração")
return
# Determina quais diretórios usar
directories = []
if args.use_config:
config = temp_monitor.load_config()
if config and config.get('directories'):
directories = config['directories']
else:
print("Erro: Nenhum diretório configurado. Use --add-dir primeiro.")
sys.exit(1)
elif args.directories:
directories = args.directories
else:
config = temp_monitor.load_config()
if config and config.get('directories'):
print("Usando diretórios da configuração...")
directories = config['directories']
else:
print("Erro: Especifique diretórios ou use --add-dir para configurar")
sys.exit(1)
# Valida diretórios
for d in directories:
if not os.path.isdir(d):
print(f"Erro: {d} não é um diretório válido")
sys.exit(1)
# Cria monitor e executa scan
monitor = FileIntegrityMonitor(directories, args.database)
monitor.save_config(directories)
scan_data = monitor.scan_directory()
monitor.save_scan(scan_data)
if not args.scan_only:
comparison = monitor.compare_scans()
html_file = monitor.generate_report(comparison)
if args.send_email and comparison is not None:
config = monitor.load_email_config()
if config:
monitor.send_email_notification(comparison, html_file, config)
else:
print("\n⚠️ Configure email com --config-email")
if __name__ == '__main__':
main()COMO USAR
Método 1: Linha de Comando Direta
./file_integrity_monitor_multi_dir.py /var/archivematica/sharedDirectory/transferSource/dataverse/dataverse/ --send-emailNesse exemplo será monitorado o diretório e gerado o html e enviado via e-mail. Deve ser usado pontualmente.
Método 2: Configuração Persistente (RECOMENDADO)
# Adiciona diretórios
./file_integrity_monitor_multi_dir.py --add-dir /var/archivematica/sharedDirectory/transferSource/dataverse/dataverse
./file_integrity_monitor_multi_dir.py --add-dir /var/archivematica/sharedDirectory/www/AIPsStore
./file_integrity_monitor_multi_dir.py --add-dir /var/archivematica/sharedDirectory/www/DIPsStore
./file_integrity_monitor_multi_dir.py --add-dir /var/archivematica/sharedDirectory/AIPbackup
# Lista diretórios
./file_integrity_monitor_multi_dir.py --list-dirs
# Executa (usa os diretórios configurados automaticamente)
./file_integrity_monitor_multi_dir.py --send-email
# Remove diretório
./file_integrity_monitor_multi_dir.py --remove-dir /var/archivematica/sharedDirectory/AIPbackup ✅ Ideal para automação com cron ✅ Não precisa repetir diretórios toda vez
Configuração no crontab
0 2 * * 1 /usr/bin/python3 /opt/scripts-preservacao/checar-integridade/file_integrity_monitor_multi_dir.py --send-email >> /var/log/file_integrity.log 2>&1COMO CONFIGURAR UMA REDE LOCKSS
CONFIGURAR O SERVIDOR
ESQUEMA DE PARTIÇÃO

Uma vez instalado o sistema operacional vamos instalar os pacotes:
yum -y install java-1.8.0-openjdk bind-utils dstat gitiotop lshw lsof lynx nmap pciutils rsync smartmontools sysstat tmux wget
Vamos agora instalar o pacote do lockss:
rpm -Uhiv https://assets.lockss.org/rpm/repo/lockss-daemon-1.78.6-1.noarch.rpmAjustamos a permissão na pasta /cache0
chown lockss. /cache0/CONFIGURAR CAIXA LOCKSS
[root@node03-lockss-scielored lockss]# ./hostconfig
root is configuring
eth0: error fetching interface information: Device not found
LOCKSS host configuration for Linux.
For more information see /etc/lockss/README
Configuring for user lockss
Fully qualified hostname (FQDN) of this machine: [node03-lockss-scielored.scielo.org]
IP address of this machine: [] 192.168.169.166
Is this machine behind NAT?: [N] Y
External IP address for NAT: [] 177.92.116.203
Initial subnet for admin UI access: [192.168.169.0/24]
LCAP V3 protocol port: [9729] 9735
PROXY port: [8080]
Admin UI port: [8081]
Mail relay for this machine: [localhost] mailrelay.scielo.org
Does mail relay mailrelay.scielo.org need user & password: [N]
E-mail address for administrator: [] infra@scielo.org
Path to java: [/usr/bin/java]
Java switches: []
Configuration URL: [http://props.lockss.org:8001/daemon/lockss.xml] http://200.130.45.61/props/unampln/lockss.xml
Configuration proxy (host:port): [NONE]
Enable config failover: [Y]
Config failover max age: []
Preservation group(s): [prod] unampln
Content storage directories: [] /cache0
Temporary storage directory: [/cache0/tmp]
User name for web UI administration: [] admin
Password for web UI administration user admin: []
Password for web UI administration (again): []
Configuration:
LOCKSS_CONFIG_VERSION=1
LOCKSS_USER="lockss"
LOCKSS_HOSTNAME=node03-lockss-scielored.scielo.org
LOCKSS_IPADDR=192.168.169.166
LOCKSS_EXTERNAL_IPADDR=177.92.116.203
LOCKSS_V3_PORT=9735
LOCKSS_ACCESS_SUBNET="192.168.169.0/24"
LOCKSS_MAILHUB=mailrelay.scielo.org
LOCKSS_MAILHUB_USER=
LOCKSS_MAILHUB_PASSWORD=
LOCKSS_EMAIL=infra@scielo.org
LOCKSS_JAVA_CMD=/usr/bin/java
LOCKSS_JAVA_SWITCHES=
LOCKSS_JAVA_HEAP=
LOCKSS_PROPS_URL="http://200.130.45.61/props/unampln/lockss.xml"
LOCKSS_PROPS_PROXY="NONE"
LOCKSS_PROPS_SERVER_AUTHENTICATE_KEYSTORE=""
LOCKSS_CONFIG_FAILOVER_ENABLE="Y"
LOCKSS_CONFIG_FAILOVER_MAX_AGE=""
LOCKSS_TEST_GROUP="unampln"
LOCKSS_DISK_PATHS="/cache0"
LOCKSS_ADMIN_USER=admin
LOCKSS_ADMIN_PASSWD=SHA-256:d17f0af8b8b9ec09d051523e6a3eb76f3c114ab2cc93f330e4d73e0b7f7347e0
LOCKSS_PROXY_PORT=8080
LOCKSS_UI_PORT=8081
LOCKSS_TMPDIR=/cache0/tmp
LOCKSS_CLEAR_TMPDIR=yes
LOCKSS_RELEASE=1.78.6-1
LOCKSS_HOME is
OK to store this configuration: [Y]
Checking content storage dirs
/cache0 exists and is writable by lockss
/var/log/lockss does not exist; shall I create it: [Y]
/cache0/tmp does not exist; shall I create it: [Y]
Done
/tmp/hostconfig.TWkRu: line 518: chkconfig: command not found
LOCKSS will start automatically at next reboot, or you may
start it now by running /etc/init.d/lockss start
/tmp/hostconfig.TWkRu: line 530: mail: command not found
Sending mail failed. Please check mail configuration.
Please also send /tmp/unsent-lockss-config to lockssdiag@lockss.org.Ao executar /etc/init.d/lockss start deu o seguinte erro:
[root@node03-lockss-scielored lockss]# /etc/init.d/lockss start
/etc/init.d/lockss: line 8: /etc/init.d/functions: No such file or directoryCopiei de um outro servidor o /etc/init.d/functions
# -*-Shell-script-*-
#
# functions This file contains functions to be used by most or all
# shell scripts in the /etc/init.d directory.
#
TEXTDOMAIN=initscripts
# Make sure umask is sane
umask 022
# Set up a default search path.
PATH="/sbin:/usr/sbin:/bin:/usr/bin"
export PATH
if [ $PPID -ne 1 -a -z "$SYSTEMCTL_SKIP_REDIRECT" ] && \
[ -d /run/systemd/system ] ; then
case "$0" in
/etc/init.d/*|/etc/rc.d/init.d/*)
_use_systemctl=1
;;
esac
fi
systemctl_redirect () {
local s
local prog=${1##*/}
local command=$2
local options=""
case "$command" in
start)
s=$"Starting $prog (via systemctl): "
;;
stop)
s=$"Stopping $prog (via systemctl): "
;;
reload|try-reload)
s=$"Reloading $prog configuration (via systemctl): "
;;
restart|try-restart|condrestart)
s=$"Restarting $prog (via systemctl): "
;;
esac
if [ -n "$SYSTEMCTL_IGNORE_DEPENDENCIES" ] ; then
options="--ignore-dependencies"
fi
if ! systemctl show "$prog.service" > /dev/null 2>&1 || \
systemctl show -p LoadState "$prog.service" | grep -q 'not-found' ; then
action $"Reloading systemd: " /bin/systemctl daemon-reload
fi
action "$s" /bin/systemctl $options $command "$prog.service"
}
# Get a sane screen width
[ -z "${COLUMNS:-}" ] && COLUMNS=80
# Read in our configuration
if [ -z "${BOOTUP:-}" ]; then
if [ -f /etc/sysconfig/init ]; then
. /etc/sysconfig/init
else
# verbose ->> very (very!) old bootup look (prior to RHL-6.0?)
# color ->> default bootup look
# other ->> default bootup look without ANSI colors or positioning
BOOTUP=color
# Column to start "[ OK ]" label in:
RES_COL=60
# terminal sequence to move to that column:
MOVE_TO_COL="echo -en \\033[${RES_COL}G"
# Terminal sequence to set color to a 'success' (bright green):
SETCOLOR_SUCCESS="echo -en \\033[1;32m"
# Terminal sequence to set color to a 'failure' (bright red):
SETCOLOR_FAILURE="echo -en \\033[1;31m"
# Terminal sequence to set color to a 'warning' (bright yellow):
SETCOLOR_WARNING="echo -en \\033[1;33m"
# Terminal sequence to reset to the default color:
SETCOLOR_NORMAL="echo -en \\033[0;39m"
# Verbosity of logging:
LOGLEVEL=1
fi
# NOTE: /dev/ttyS* is serial console. "not a tty" is such as
# /dev/null associated when executed under systemd service units.
if LANG=C tty | grep -q -e '\(/dev/ttyS\|not a tty\)'; then
BOOTUP=serial
MOVE_TO_COL=
SETCOLOR_SUCCESS=
SETCOLOR_FAILURE=
SETCOLOR_WARNING=
SETCOLOR_NORMAL=
fi
fi
# Check if any of $pid (could be plural) are running
checkpid() {
local i
for i in $* ; do
[ -d "/proc/$i" ] && return 0
done
return 1
}
__kill_pids_term_kill_checkpids() {
local base_stime=$1
shift 1
local pid=
local pids=$*
local remaining=
local stat=
local stime=
for pid in $pids ; do
[ ! -e "/proc/$pid" ] && continue
read -r line < "/proc/$pid/stat" 2> /dev/null
stat=($line)
stime=${stat[21]}
[ -n "$stime" ] && [ "$base_stime" -lt "$stime" ] && continue
remaining+="$pid "
done
echo "$remaining"
[ -n "$remaining" ] && return 1
return 0
}
__kill_pids_term_kill() {
local try=0
local delay=3;
local pid=
local stat=
local base_stime=
# We can't initialize stat & base_stime on the same line where 'local'
# keyword is, otherwise the sourcing of this file will fail for ksh...
stat=($(< /proc/self/stat))
base_stime=${stat[21]}
if [ "$1" = "-d" ]; then
delay=$2
shift 2
fi
local kill_list=$*
kill_list=$(__kill_pids_term_kill_checkpids $base_stime $kill_list)
[ -z "$kill_list" ] && return 0
kill -TERM $kill_list >/dev/null 2>&1
sleep 0.1
kill_list=$(__kill_pids_term_kill_checkpids $base_stime $kill_list)
if [ -n "$kill_list" ] ; then
while [ $try -lt $delay ] ; do
sleep 1
kill_list=$(__kill_pids_term_kill_checkpids $base_stime $kill_list)
[ -z "$kill_list" ] && break
let try+=1
done
if [ -n "$kill_list" ] ; then
kill -KILL $kill_list >/dev/null 2>&1
sleep 0.1
kill_list=$(__kill_pids_term_kill_checkpids $base_stime $kill_list)
fi
fi
[ -n "$kill_list" ] && return 1
return 0
}
# __proc_pids {program} [pidfile]
# Set $pid to pids from /run* for {program}. $pid should be declared
# local in the caller.
# Returns LSB exit code for the 'status' action.
__pids_var_run() {
local base=${1##*/}
local pid_file=${2:-/run/$base.pid}
local pid_dir=$(/usr/bin/dirname $pid_file > /dev/null)
local binary=$3
[ -d "$pid_dir" ] && [ ! -r "$pid_dir" ] && return 4
pid=
if [ -f "$pid_file" ] ; then
local line p
[ ! -r "$pid_file" ] && return 4 # "user had insufficient privilege"
while : ; do
read line
[ -z "$line" ] && break
for p in $line ; do
if [ -z "${p//[0-9]/}" ] && [ -d "/proc/$p" ] ; then
if [ -n "$binary" ] ; then
local b=$(readlink /proc/$p/exe | sed -e 's/\s*(deleted)$//')
[ "$b" != "$binary" ] && continue
fi
pid="$pid $p"
fi
done
done < "$pid_file"
if [ -n "$pid" ]; then
return 0
fi
return 1 # "Program is dead and /run pid file exists"
fi
return 3 # "Program is not running"
}
# Output PIDs of matching processes, found using pidof
__pids_pidof() {
pidof -c -o $$ -o $PPID -o %PPID -x "$1" || \
pidof -c -o $$ -o $PPID -o %PPID -x "${1##*/}"
}
# A function to start a program.
daemon() {
# Test syntax.
local gotbase= force= nicelevel corelimit
local pid base= user= nice= bg= pid_file=
local cgroup=
nicelevel=0
while [ "$1" != "${1##[-+]}" ]; do
case $1 in
'')
echo $"$0: Usage: daemon [+/-nicelevel] {program}" "[arg1]..."
return 1
;;
--check)
base=$2
gotbase="yes"
shift 2
;;
--check=?*)
base=${1#--check=}
gotbase="yes"
shift
;;
--user)
user=$2
shift 2
;;
--user=?*)
user=${1#--user=}
shift
;;
--pidfile)
pid_file=$2
shift 2
;;
--pidfile=?*)
pid_file=${1#--pidfile=}
shift
;;
--force)
force="force"
shift
;;
[-+][0-9]*)
nice="nice -n $1"
shift
;;
*)
echo $"$0: Usage: daemon [+/-nicelevel] {program}" "[arg1]..."
return 1
;;
esac
done
# Save basename.
[ -z "$gotbase" ] && base=${1##*/}
# See if it's already running. Look *only* at the pid file.
__pids_var_run "$base" "$pid_file"
[ -n "$pid" -a -z "$force" ] && return
# make sure it doesn't core dump anywhere unless requested
corelimit="ulimit -S -c ${DAEMON_COREFILE_LIMIT:-0}"
# if they set NICELEVEL in /etc/sysconfig/foo, honor it
[ -n "${NICELEVEL:-}" ] && nice="nice -n $NICELEVEL"
# Echo daemon
[ "${BOOTUP:-}" = "verbose" -a -z "${LSB:-}" ] && echo -n " $base"
# And start it up.
if [ -z "$user" ]; then
$nice /bin/bash -c "$corelimit >/dev/null 2>&1 ; $*"
else
$nice runuser -s /bin/bash $user -c "$corelimit >/dev/null 2>&1 ; $*"
fi
[ "$?" -eq 0 ] && success $"$base startup" || failure $"$base startup"
}
# A function to stop a program.
killproc() {
local RC killlevel= base pid pid_file= delay try binary=
RC=0; delay=3; try=0
# Test syntax.
if [ "$#" -eq 0 ]; then
echo $"Usage: killproc [-p {pidfile} [-b {binary}]] [-d {delay}] {program} [-signal]"
return 1
fi
if [ "$1" = "-p" ]; then
pid_file=$2
shift 2
fi
if [ "$1" = "-b" ]; then
if [ -z $pid_file ]; then
echo $"-b option can be used only with -p"
echo $"Usage: killproc [-p {pidfile} [-b {binary}]] [-d {delay}] {program} [-signal]"
return 1
fi
binary=$2
shift 2
fi
if [ "$1" = "-d" ]; then
delay=$(echo $2 | awk -v RS=' ' -v IGNORECASE=1 '{if($1!~/^[0-9.]+[smhd]?$/) exit 1;d=$1~/s$|^[0-9.]*$/?1:$1~/m$/?60:$1~/h$/?60*60:$1~/d$/?24*60*60:-1;if(d==-1) exit 1;delay+=d*$1} END {printf("%d",delay+0.5)}')
if [ "$?" -eq 1 ]; then
echo $"Usage: killproc [-p {pidfile} [-b {binary}]] [-d {delay}] {program} [-signal]"
return 1
fi
shift 2
fi
# check for second arg to be kill level
[ -n "${2:-}" ] && killlevel=$2
# Save basename.
base=${1##*/}
# Find pid.
__pids_var_run "$1" "$pid_file" "$binary"
RC=$?
if [ -z "$pid" ]; then
if [ -z "$pid_file" ]; then
pid="$(__pids_pidof "$1")"
else
[ "$RC" = "4" ] && { failure $"$base shutdown" ; return $RC ;}
fi
fi
# Kill it.
if [ -n "$pid" ] ; then
[ "$BOOTUP" = "verbose" -a -z "${LSB:-}" ] && echo -n "$base "
if [ -z "$killlevel" ] ; then
__kill_pids_term_kill -d $delay $pid
RC=$?
[ "$RC" -eq 0 ] && success $"$base shutdown" || failure $"$base shutdown"
# use specified level only
else
if checkpid $pid; then
kill $killlevel $pid >/dev/null 2>&1
RC=$?
[ "$RC" -eq 0 ] && success $"$base $killlevel" || failure $"$base $killlevel"
elif [ -n "${LSB:-}" ]; then
RC=7 # Program is not running
fi
fi
else
if [ -n "${LSB:-}" -a -n "$killlevel" ]; then
RC=7 # Program is not running
else
failure $"$base shutdown"
RC=0
fi
fi
# Remove pid file if any.
if [ -z "$killlevel" ]; then
rm -f "${pid_file:-/run/$base.pid}"
fi
return $RC
}
# A function to find the pid of a program. Looks *only* at the pidfile
pidfileofproc() {
local pid
# Test syntax.
if [ "$#" = 0 ] ; then
echo $"Usage: pidfileofproc {program}"
return 1
fi
__pids_var_run "$1"
[ -n "$pid" ] && echo $pid
return 0
}
# A function to find the pid of a program.
pidofproc() {
local RC pid pid_file=
# Test syntax.
if [ "$#" = 0 ]; then
echo $"Usage: pidofproc [-p {pidfile}] {program}"
return 1
fi
if [ "$1" = "-p" ]; then
pid_file=$2
shift 2
fi
fail_code=3 # "Program is not running"
# First try "/run/*.pid" files
__pids_var_run "$1" "$pid_file"
RC=$?
if [ -n "$pid" ]; then
echo $pid
return 0
fi
[ -n "$pid_file" ] && return $RC
__pids_pidof "$1" || return $RC
}
status() {
local base pid lock_file= pid_file= binary=
# Test syntax.
if [ "$#" = 0 ] ; then
echo $"Usage: status [-p {pidfile}] [-l {lockfile}] [-b {binary}] {program}"
return 1
fi
if [ "$1" = "-p" ]; then
pid_file=$2
shift 2
fi
if [ "$1" = "-l" ]; then
lock_file=$2
shift 2
fi
if [ "$1" = "-b" ]; then
if [ -z $pid_file ]; then
echo $"-b option can be used only with -p"
echo $"Usage: status [-p {pidfile}] [-l {lockfile}] [-b {binary}] {program}"
return 1
fi
binary=$2
shift 2
fi
base=${1##*/}
if [ "$_use_systemctl" = "1" ]; then
systemctl status ${0##*/}.service
ret=$?
# LSB daemons that dies abnormally in systemd looks alive in systemd's eyes due to RemainAfterExit=yes
# lets adjust the reality a little bit
if systemctl show -p ActiveState ${0##*/}.service | grep -q '=active$' && \
systemctl show -p SubState ${0##*/}.service | grep -q '=exited$' ; then
ret=3
fi
return $ret
fi
# First try "pidof"
__pids_var_run "$1" "$pid_file" "$binary"
RC=$?
if [ -z "$pid_file" -a -z "$pid" ]; then
pid="$(__pids_pidof "$1")"
fi
if [ -n "$pid" ]; then
echo $"${base} (pid $pid) is running..."
return 0
fi
case "$RC" in
0)
echo $"${base} (pid $pid) is running..."
return 0
;;
1)
echo $"${base} dead but pid file exists"
return 1
;;
4)
echo $"${base} status unknown due to insufficient privileges."
return 4
;;
esac
if [ -z "${lock_file}" ]; then
lock_file=${base}
fi
# See if /var/lock/subsys/${lock_file} exists
if [ -f /var/lock/subsys/${lock_file} ]; then
echo $"${base} dead but subsys locked"
return 2
fi
echo $"${base} is stopped"
return 3
}
echo_success() {
[ "$BOOTUP" = "color" ] && $MOVE_TO_COL
echo -n "["
[ "$BOOTUP" = "color" ] && $SETCOLOR_SUCCESS
echo -n $" OK "
[ "$BOOTUP" = "color" ] && $SETCOLOR_NORMAL
echo -n "]"
echo -ne "\r"
return 0
}
echo_failure() {
[ "$BOOTUP" = "color" ] && $MOVE_TO_COL
echo -n "["
[ "$BOOTUP" = "color" ] && $SETCOLOR_FAILURE
echo -n $"FAILED"
[ "$BOOTUP" = "color" ] && $SETCOLOR_NORMAL
echo -n "]"
echo -ne "\r"
return 1
}
echo_passed() {
[ "$BOOTUP" = "color" ] && $MOVE_TO_COL
echo -n "["
[ "$BOOTUP" = "color" ] && $SETCOLOR_WARNING
echo -n $"PASSED"
[ "$BOOTUP" = "color" ] && $SETCOLOR_NORMAL
echo -n "]"
echo -ne "\r"
return 1
}
echo_warning() {
[ "$BOOTUP" = "color" ] && $MOVE_TO_COL
echo -n "["
[ "$BOOTUP" = "color" ] && $SETCOLOR_WARNING
echo -n $"WARNING"
[ "$BOOTUP" = "color" ] && $SETCOLOR_NORMAL
echo -n "]"
echo -ne "\r"
return 1
}
# Inform the graphical boot of our current state
update_boot_stage() {
if [ -x /bin/plymouth ]; then
/bin/plymouth --update="$1"
fi
return 0
}
# Log that something succeeded
success() {
[ "$BOOTUP" != "verbose" -a -z "${LSB:-}" ] && echo_success
return 0
}
# Log that something failed
failure() {
local rc=$?
[ "$BOOTUP" != "verbose" -a -z "${LSB:-}" ] && echo_failure
[ -x /bin/plymouth ] && /bin/plymouth --details
return $rc
}
# Log that something passed, but may have had errors. Useful for fsck
passed() {
local rc=$?
[ "$BOOTUP" != "verbose" -a -z "${LSB:-}" ] && echo_passed
return $rc
}
# Log a warning
warning() {
local rc=$?
[ "$BOOTUP" != "verbose" -a -z "${LSB:-}" ] && echo_warning
return $rc
}
# Run some action. Log its output.
action() {
local STRING rc
STRING=$1
echo -n "$STRING "
shift
"$@" && success $"$STRING" || failure $"$STRING"
rc=$?
echo
return $rc
}
# returns OK if $1 contains $2
strstr() {
[ "${1#*$2*}" = "$1" ] && return 1
return 0
}
# Check whether file $1 is a backup or rpm-generated file and should be ignored
# Copy of the function is present in usr/sbin/service
is_ignored_file() {
case "$1" in
*~ | *.bak | *.old | *.orig | *.rpmnew | *.rpmorig | *.rpmsave)
return 0
;;
esac
return 1
}
# Convert the value ${1} of time unit ${2}-seconds into seconds:
convert2sec() {
local retval=""
case "${2}" in
deci) retval=$(awk "BEGIN {printf \"%.1f\", ${1} / 10}") ;;
centi) retval=$(awk "BEGIN {printf \"%.2f\", ${1} / 100}") ;;
mili) retval=$(awk "BEGIN {printf \"%.3f\", ${1} / 1000}") ;;
micro) retval=$(awk "BEGIN {printf \"%.6f\", ${1} / 1000000}") ;;
nano) retval=$(awk "BEGIN {printf \"%.9f\", ${1} / 1000000000}") ;;
piko) retval=$(awk "BEGIN {printf \"%.12f\", ${1} / 1000000000000}") ;;
esac
echo "${retval}"
}
# Evaluate shvar-style booleans
is_true() {
case "$1" in
[tT] | [yY] | [yY][eE][sS] | [oO][nN] | [tT][rR][uU][eE] | 1)
return 0
;;
esac
return 1
}
# Evaluate shvar-style booleans
is_false() {
case "$1" in
[fF] | [nN] | [nN][oO] | [oO][fF][fF] | [fF][aA][lL][sS][eE] | 0)
return 0
;;
esac
return 1
}
# Apply sysctl settings, including files in /etc/sysctl.d
apply_sysctl() {
if [ -x /lib/systemd/systemd-sysctl ]; then
/lib/systemd/systemd-sysctl
else
for file in /usr/lib/sysctl.d/*.conf ; do
is_ignored_file "$file" && continue
[ -f /run/sysctl.d/${file##*/} ] && continue
[ -f /etc/sysctl.d/${file##*/} ] && continue
test -f "$file" && sysctl -e -p "$file" >/dev/null 2>&1
done
for file in /run/sysctl.d/*.conf ; do
is_ignored_file "$file" && continue
[ -f /etc/sysctl.d/${file##*/} ] && continue
test -f "$file" && sysctl -e -p "$file" >/dev/null 2>&1
done
for file in /etc/sysctl.d/*.conf ; do
is_ignored_file "$file" && continue
test -f "$file" && sysctl -e -p "$file" >/dev/null 2>&1
done
sysctl -e -p /etc/sysctl.conf >/dev/null 2>&1
fi
}
# A sed expression to filter out the files that is_ignored_file recognizes
__sed_discard_ignored_files='/\(~\|\.bak\|\.old\|\.orig\|\.rpmnew\|\.rpmorig\|\.rpmsave\)$/d'
if [ "$_use_systemctl" = "1" ]; then
if [ "x$1" = xstart -o \
"x$1" = xstop -o \
"x$1" = xrestart -o \
"x$1" = xreload -o \
"x$1" = xtry-restart -o \
"x$1" = xforce-reload -o \
"x$1" = xcondrestart ] ; then
systemctl_redirect $0 $1
exit $?
fi
fi
strstr "$(cat /proc/cmdline)" "rc.debug" && set -x
return 0ao tentar subir novamente o serviço
[root@node03-lockss-scielored lockss]# /etc/init.d/lockss start
Reloading systemd: [ OK ]
Starting lockss (via systemctl): Failed to start lockss.service: Unit lockss.service not found.
[FAILED]crie o script de start
/usr/local/libexec/lockss-start.sh
#!/usr/bin/env bash
set -euo pipefail
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
USER_LOCKSS=lockss
HOME_LOCKSS=/home/lockss
LOG_DIR=/var/log/lockss
LOG_FILE=/var/log/lockss/stdout
LOCKFILE=/var/run/lockss/startdaemon.lock.lockss
KEEPGOING=/home/lockss/KeepGoing
mkdir -p /var/run/lockss "${LOG_DIR}" "${HOME_LOCKSS}"
touch "${LOG_FILE}"
chown "${USER_LOCKSS}:${USER_LOCKSS}" "${HOME_LOCKSS}" "${LOG_FILE}"
chmod 755 /var/run/lockss "${LOG_DIR}" "${HOME_LOCKSS}"
chmod 644 "${LOG_FILE}"
# não sobe outra cópia por cima
if pgrep -f '^/bin/bash /etc/lockss/startdaemon lockss$' >/dev/null 2>&1; then
echo "LOCKSS already appears to be running"
exit 0
fi
rm -f "${LOCKFILE}" "${KEEPGOING}"
/etc/lockss/startdaemon "${USER_LOCKSS}"
sleep 3
if ! pgrep -f '^/bin/bash /etc/lockss/startdaemon lockss$' >/dev/null 2>&1; then
echo "LOCKSS startdaemon did not stay running" >&2
exit 1
fi
if ! pgrep -u "${USER_LOCKSS}" -f '^/bin/sh /etc/lockss/rundaemon wait$' >/dev/null 2>&1; then
echo "LOCKSS rundaemon did not start" >&2
exit 1
fi
exit 0Permissão
chmod 755 /usr/local/libexec/lockss-start.shCrie o script de stop
/usr/local/libexec/lockss-stop.sh
#!/usr/bin/env bash
set -euo pipefail
rm -f /home/lockss/KeepGoing || true
pkill -TERM -f '^/bin/bash /etc/lockss/startdaemon lockss$' || true
pkill -TERM -f '^runuser -s /bin/bash - lockss -c ulimit -S -c 0 >/dev/null 2>&1 ; /etc/lockss/rundaemon wait$' || true
pkill -TERM -u lockss -f '^/bin/sh /etc/lockss/rundaemon wait$' || true
pkill -TERM -u lockss -f java || true
sleep 5
pkill -KILL -f '^/bin/bash /etc/lockss/startdaemon lockss$' || true
pkill -KILL -f '^runuser -s /bin/bash - lockss -c ulimit -S -c 0 >/dev/null 2>&1 ; /etc/lockss/rundaemon wait$' || true
pkill -KILL -u lockss -f '^/bin/sh /etc/lockss/rundaemon wait$' || true
pkill -KILL -u lockss -f java || true
rm -f /var/run/lockss/startdaemon.lock.lockss || truePermissão:
chmod 755 /usr/local/libexec/lockss-stop.shcriei /etc/systemd/system/lockss.service
[Unit]
Description=LOCKSS daemon
After=network.target local-fs.target
[Service]
Type=oneshot
RemainAfterExit=yes
ExecStart=/usr/local/libexec/lockss-start.sh
ExecStop=/usr/local/libexec/lockss-stop.sh
TimeoutStartSec=60
TimeoutStopSec=60
[Install]
WantedBy=multi-user.targetAgora inicie o daemon
systemctl daemon-reload
systemctl status lockssDepois valide:
cat /var/run/lockss/startdaemon.lock.lockss
ps -fp "$(cat /var/run/lockss/startdaemon.lock.lockss)"
ls -l /home/lockss/KeepGoingDepois que isso estiver funcionando, confirme sempre:
ps -eo pid,ppid,user,cmd | egrep 'startdaemon|rundaemon|[j]ava'Com o serviço rodando, você deve ver apenas uma cadeia de processos.
Se aparecerem várias, significa que algum start anterior não foi limpo.
💡 Resumo honesto:
O problema não é Rocky 9. O problema é que o startdaemon do LOCKSS foi escrito com um modelo de supervisão próprio (lockfile + KeepGoing + background loops), que não conversa bem com o modelo de gerenciamento de processos do systemd. Então a abordagem correta é delegar o stop para um script que mata explicitamente os processos, como você já comprovou que funciona.
COMPILADO LOCKSS.JAR
O lockss.jar deve ser alterado para a versão compilada pelo Rondineli. Copie o lockss.jar para o servidor e siga:
systemctl stop lockss
cd /usr/share/lockss/
mv lockss.jar lockss.jar.original
cp -a /home/rondinelesaad/lockss.jar .
systemctl start lockss